mirror of
https://github.com/netdata/netdata.git
synced 2025-05-14 13:32:36 +00:00
remove "foreach" from health REFERENCE.md (#17106)
This commit is contained in:
parent
4c1adba507
commit
149719ca8c
1 changed files with 12 additions and 239 deletions
|
|
@ -253,7 +253,7 @@ Netdata parses the following lines. Beneath the table is an in-depth explanation
|
|||
| [`repeat`](#alert-line-repeat) | no | The interval for sending notifications when an alert is in WARNING or CRITICAL mode. |
|
||||
| [`options`](#alert-line-options) | no | Add an option to not clear alerts. |
|
||||
| [`host labels`](#alert-line-host-labels) | no | Restrict an alert or template to a list of matching labels present on a host. |
|
||||
| [`chart labels`](#alert-line-chart-labels) | no | Restrict an alert or template to a list of matching labels present on a chart. |
|
||||
| [`chart labels`](#alert-line-chart-labels) | no | Restrict an alert or template to a list of matching labels present on a chart. |
|
||||
| [`summary`](#alert-line-summary) | no | A brief description of the alert. |
|
||||
| [`info`](#alert-line-info) | no | A longer text field that provides more information of this alert |
|
||||
|
||||
|
|
@ -439,7 +439,7 @@ This line makes a database lookup to find a value. This result of this lookup is
|
|||
The format is:
|
||||
|
||||
```yaml
|
||||
lookup: METHOD AFTER [at BEFORE] [every DURATION] [OPTIONS] [of DIMENSIONS] [foreach DIMENSIONS]
|
||||
lookup: METHOD AFTER [at BEFORE] [every DURATION] [OPTIONS] [of DIMENSIONS]
|
||||
```
|
||||
|
||||
The full [database query API](https://github.com/netdata/netdata/blob/master/src/web/api/queries/README.md) is supported. In short:
|
||||
|
|
@ -467,12 +467,6 @@ The full [database query API](https://github.com/netdata/netdata/blob/master/src
|
|||
`,` or `|` instead of spaces)_ and the `match-ids` and `match-names` options affect the searches
|
||||
for dimensions.
|
||||
|
||||
- `foreach DIMENSIONS` is optional and works only with [templates](#alert-line-alarm-or-template), will always be the last parameter, and uses the same `,`/`|`
|
||||
rules as the `of` parameter. Each dimension you specify in `foreach` will use the same rule
|
||||
to trigger an alert. If you set both `of` and `foreach`, Netdata will ignore the `of` parameter
|
||||
and replace it with one of the dimensions you gave to `foreach`. This option allows you to
|
||||
[use dimension templates to create dynamic alerts](#use-dimension-templates-to-create-dynamic-alerts).
|
||||
|
||||
The result of the lookup will be available as `$this` and `$NAME` in expressions.
|
||||
The timestamps of the timeframe evaluated by the database lookup is available as variables
|
||||
`$after` and `$before` (both are unix timestamps).
|
||||
|
|
@ -877,17 +871,17 @@ context are essentially identical, with the only difference being the family tha
|
|||
- `$update_every` is the update frequency of the chart
|
||||
- `$green` and `$red` the threshold defined in alerts (these are per chart - the charts inherits them from the first alert that defined them)
|
||||
|
||||
Chart dimensions define their last calculated (i.e. interpolated) value, exactly as
|
||||
shown on the charts, but also a variable with their name and suffix `_raw` that resolves
|
||||
to the last collected value - as collected and another with suffix `_last_collected_t`
|
||||
that resolves to unix timestamp the dimension was last collected (there may be dimensions
|
||||
that fail to be collected while others continue normally).
|
||||
> Chart dimensions define their last calculated (i.e. interpolated) value, exactly as
|
||||
shown on the charts, but also a variable with their name and suffix `_raw` that resolves
|
||||
to the last collected value - as collected and another with suffix `_last_collected_t`
|
||||
that resolves to unix timestamp the dimension was last collected (there may be dimensions
|
||||
that fail to be collected while others continue normally).
|
||||
|
||||
- **host variables**. All the dimensions of all charts, including all alerts, in fullname.
|
||||
Fullname is `CHART.VARIABLE`, where `CHART` is either the chart id or the chart name (both
|
||||
are supported).
|
||||
|
||||
- **special variables\*** are:
|
||||
- **special variables** are:
|
||||
|
||||
- `$this`, which is resolved to the value of the current alert.
|
||||
|
||||
|
|
@ -1069,44 +1063,7 @@ Note that the drops chart does not exist if a network interface has never droppe
|
|||
When Netdata detects a dropped packet, it will add the chart, and it will automatically attach this
|
||||
alert to it.
|
||||
|
||||
### Example 5 - CPU usage
|
||||
|
||||
Check if user or system dimension is using more than 50% of cpu:
|
||||
|
||||
```yaml
|
||||
template: cpu_template
|
||||
on: system.cpu
|
||||
os: linux
|
||||
lookup: average -1m foreach system,user
|
||||
units: %
|
||||
every: 10s
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
```
|
||||
|
||||
The `lookup` line will calculate the average CPU usage from system and user over the last minute. Because we have
|
||||
the foreach in the `lookup` line, Netdata will create two independent alerts called `cpu_template_system`
|
||||
and `dim_template_user` that will have all the other parameters shared among them.
|
||||
|
||||
### Example 6 - CPU usage
|
||||
|
||||
Check if all dimensions are using more than 50% of cpu:
|
||||
|
||||
```yaml
|
||||
template: cpu_template
|
||||
on: system.cpu
|
||||
os: linux
|
||||
lookup: average -1m foreach *
|
||||
units: %
|
||||
every: 10s
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
```
|
||||
|
||||
The `lookup` line will calculate the average of CPU usage from system and user over the last minute. In this case
|
||||
Netdata will create alerts for all dimensions of the chart.
|
||||
|
||||
### Example 7 - Z-Score based alert
|
||||
### Example 5 - Z-Score based alert
|
||||
|
||||
Derive a "[Z Score](https://en.wikipedia.org/wiki/Standard_score)" based alert on `user` dimension of the `system.cpu` chart:
|
||||
|
||||
|
|
@ -1132,28 +1089,7 @@ lookup: mean -10s of user
|
|||
|
||||
Since [`z = (x - mean) / stddev`](https://en.wikipedia.org/wiki/Standard_score) we create two input alerts, one for `mean` and one for `stddev` and then use them both as inputs in our final `cpu_user_zscore` alert.
|
||||
|
||||
### Example 8 - [Anomaly rate](https://github.com/netdata/netdata/blob/master/src/ml/README.md#anomaly-rate) based CPU dimensions alert
|
||||
|
||||
Warning if 5 minute rolling [anomaly rate](https://github.com/netdata/netdata/blob/master/src/ml/README.md#anomaly-rate) for any CPU dimension is above 5%, critical if it goes above 20%:
|
||||
|
||||
```yaml
|
||||
template: ml_5min_cpu_dims
|
||||
on: system.cpu
|
||||
os: linux
|
||||
hosts: *
|
||||
lookup: average -5m anomaly-bit foreach *
|
||||
calc: $this
|
||||
units: %
|
||||
every: 30s
|
||||
warn: $this > (($status >= $WARNING) ? (5) : (20))
|
||||
crit: $this > (($status == $CRITICAL) ? (20) : (100))
|
||||
info: rolling 5min anomaly rate for each system.cpu dimension
|
||||
```
|
||||
|
||||
The `lookup` line will calculate the average anomaly rate of each `system.cpu` dimension over the last 5 minues. In this case
|
||||
Netdata will create alerts for all dimensions of the chart.
|
||||
|
||||
### Example 9 - [Anomaly rate](https://github.com/netdata/netdata/blob/master/src/ml/README.md#anomaly-rate) based CPU chart alert
|
||||
### Example 6 - [Anomaly rate](https://github.com/netdata/netdata/blob/master/src/ml/README.md#anomaly-rate) based CPU chart alert
|
||||
|
||||
Warning if 5 minute rolling [anomaly rate](https://github.com/netdata/netdata/blob/master/src/ml/README.md#anomaly-rate) averaged across all CPU dimensions is above 5%, critical if it goes above 20%:
|
||||
|
||||
|
|
@ -1174,7 +1110,7 @@ template: ml_5min_cpu_chart
|
|||
The `lookup` line will calculate the average anomaly rate across all `system.cpu` dimensions over the last 5 minues. In this case
|
||||
Netdata will create one alert for the chart.
|
||||
|
||||
### Example 10 - [Anomaly rate](https://github.com/netdata/netdata/blob/master/src/ml/README.md#anomaly-rate) based node level alert
|
||||
### Example 7 - [Anomaly rate](https://github.com/netdata/netdata/blob/master/src/ml/README.md#anomaly-rate) based node level alert
|
||||
|
||||
Warning if 5 minute rolling [anomaly rate](https://github.com/netdata/netdata/blob/master/src/ml/README.md#anomaly-rate) averaged across all ML enabled dimensions is above 5%, critical if it goes above 20%:
|
||||
|
||||
|
|
@ -1192,170 +1128,7 @@ template: ml_5min_node
|
|||
info: rolling 5min anomaly rate for all ML enabled dims
|
||||
```
|
||||
|
||||
The `lookup` line will use the `anomaly_rate` dimension of the `anomaly_detection.anomaly_rate` ML chart to calculate the average [node level anomaly rate](https://github.com/netdata/netdata/blob/master/src/ml/README.md#node-anomaly-rate) over the last 5 minues.
|
||||
|
||||
## Use dimension templates to create dynamic alerts
|
||||
|
||||
In v1.18 of Netdata, we introduced **dimension templates** for alerts, which simplifies the process of
|
||||
writing [alert entities](#health-entity-reference) for
|
||||
charts with many dimensions.
|
||||
|
||||
Dimension templates can condense many individual entities into one—no more copy-pasting one entity and changing the
|
||||
`alarm`/`template` and `lookup` lines for each dimension you'd like to monitor.
|
||||
|
||||
### The fundamentals of `foreach`
|
||||
|
||||
> **Note**: works only with [templates](#alert-line-alarm-or-template).
|
||||
|
||||
Our dimension templates update creates a new `foreach` parameter to the
|
||||
existing [`lookup` line](#alert-line-lookup). This
|
||||
is where the magic happens.
|
||||
|
||||
You use the `foreach` parameter to specify which dimensions you want to monitor with this single alert. You can separate
|
||||
them with a comma (`,`) or a pipe (`|`). You can also use
|
||||
a [Netdata simple pattern](https://github.com/netdata/netdata/blob/master/src/libnetdata/simple_pattern/README.md) to create
|
||||
many alerts with a regex-like syntax.
|
||||
|
||||
The `foreach` parameter _has_ to be the last parameter in your `lookup` line, and if you have both `of` and `foreach` in
|
||||
the same `lookup` line, Netdata will ignore the `of` parameter and use `foreach` instead.
|
||||
|
||||
Let's get into some examples, so you can see how the new parameter works.
|
||||
|
||||
> ⚠️ The following entities are examples to showcase the functionality and syntax of dimension templates. They are not
|
||||
> meant to be run as-is on production systems.
|
||||
|
||||
### Condensing entities with `foreach`
|
||||
|
||||
Let's say you want to monitor the `system`, `user`, and `nice` dimensions in your system's overall CPU utilization.
|
||||
Before dimension templates, you would need the following three entities:
|
||||
|
||||
```yaml
|
||||
alarm: cpu_system
|
||||
on: system.cpu
|
||||
lookup: average -10m of system
|
||||
every: 1m
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
|
||||
alarm: cpu_user
|
||||
on: system.cpu
|
||||
lookup: average -10m of user
|
||||
every: 1m
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
|
||||
alarm: cpu_nice
|
||||
on: system.cpu
|
||||
lookup: average -10m of nice
|
||||
every: 1m
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
```
|
||||
|
||||
With dimension templates, you can condense these into a single template. Take note of the `lookup` line.
|
||||
|
||||
```yaml
|
||||
template: cpu_template
|
||||
on: system.cpu
|
||||
lookup: average -10m foreach system,user,nice
|
||||
every: 1m
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
```
|
||||
|
||||
The `template` line specifies the naming scheme Netdata will use. You can use whatever naming scheme you'd like, with `.`
|
||||
and `_` being the only allowed symbols.
|
||||
|
||||
The `lookup` line has changed from `of` to `foreach`, and we're now passing three dimensions.
|
||||
|
||||
In this example, Netdata will create three alerts with the names `cpu_template_system`, `cpu_template_user`, and
|
||||
`cpu_template_nice`. Every minute, each alert will use the same database query to calculate the average CPU usage for
|
||||
the `system`, `user`, and `nice` dimensions over the last 10 minutes and send out alerts if necessary.
|
||||
|
||||
You can find these three alerts active by clicking on the **Alerts** button in the top navigation, and then clicking on
|
||||
the **All** tab and scrolling to the **system - cpu** collapsible section.
|
||||
|
||||
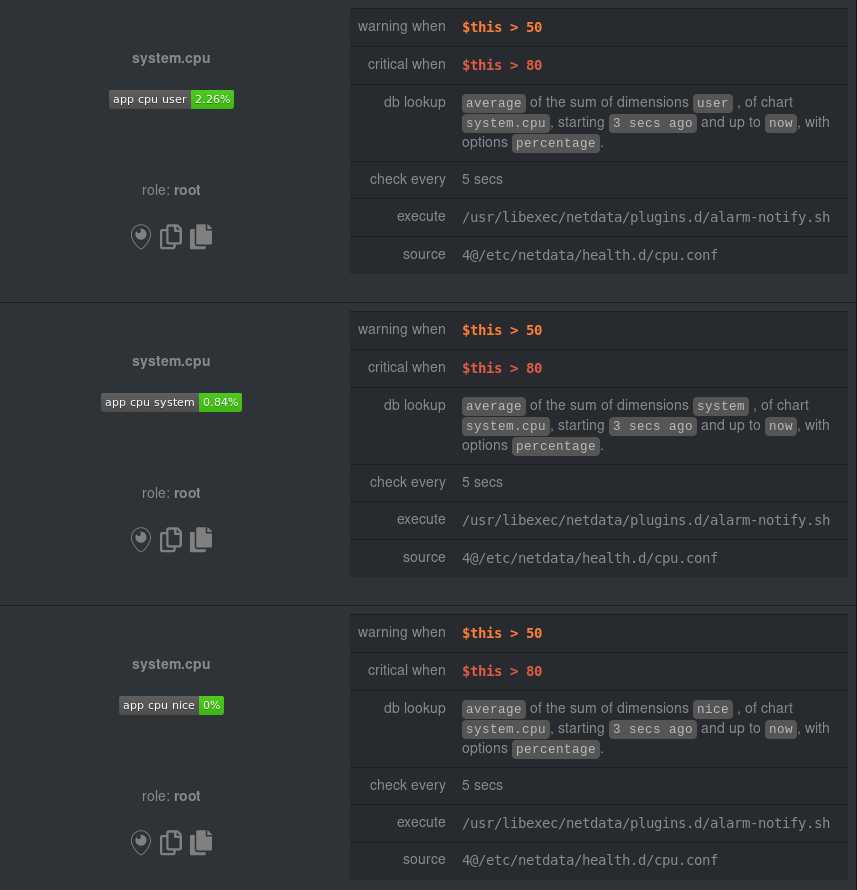
|
||||
|
||||
Let's look at some other examples of how `foreach` works, so you can best apply it in your configurations.
|
||||
|
||||
### Using a Netdata simple pattern in `foreach`
|
||||
|
||||
In the last example, we used `foreach system,user,nice` to create three distinct alerts using dimension templates. But
|
||||
what if you want to quickly create alerts for _all_ the dimensions of a given chart?
|
||||
|
||||
Use a [simple pattern](https://github.com/netdata/netdata/blob/master/src/libnetdata/simple_pattern/README.md)! One example of a simple pattern is a single wildcard
|
||||
(`*`).
|
||||
|
||||
Instead of monitoring system CPU usage, let's monitor per-application CPU usage using the `apps.cpu` chart. Passing a
|
||||
wildcard as the simple pattern tells Netdata to create a separate alert for _every_ process on your system:
|
||||
|
||||
```yaml
|
||||
alarm: app_cpu
|
||||
on: apps.cpu
|
||||
lookup: average -10m percentage foreach *
|
||||
every: 1m
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
```
|
||||
|
||||
This entity will now create alerts for every dimension in the `apps.cpu` chart. Given that most `apps.cpu` charts have
|
||||
10 or more dimensions, using the wildcard ensures you catch every CPU-hogging process.
|
||||
|
||||
To learn more about how to use simple patterns with dimension templates, see
|
||||
our [simple patterns documentation](https://github.com/netdata/netdata/blob/master/src/libnetdata/simple_pattern/README.md).
|
||||
|
||||
### Using `foreach` with alert templates
|
||||
|
||||
Dimension templates also work
|
||||
with [alert templates](#alert-line-alarm-or-template).
|
||||
Alert templates help you create alerts for all the charts with a given context—for example, all the cores of your
|
||||
system's CPU.
|
||||
|
||||
By combining the two, you can create dozens of individual alerts with a single template entity. Here's how you would
|
||||
create alerts for the `system`, `user`, and `nice` dimensions for every chart in the `cpu.cpu` context—or, in other
|
||||
words, every CPU core.
|
||||
|
||||
```yaml
|
||||
template: cpu_template
|
||||
on: cpu.cpu
|
||||
lookup: average -10m percentage foreach system,user,nice
|
||||
every: 1m
|
||||
warn: $this > 50
|
||||
crit: $this > 80
|
||||
```
|
||||
|
||||
On a system with a 6-core, 12-thread Ryzen 5 1600 CPU, this one entity creates alerts on the following charts and
|
||||
dimensions:
|
||||
|
||||
- `cpu.cpu0`
|
||||
- `cpu_template_user`
|
||||
- `cpu_template_system`
|
||||
- `cpu_template_nice`
|
||||
|
||||
- `cpu.cpu1`
|
||||
- `cpu_template_user`
|
||||
- `cpu_template_system`
|
||||
- `cpu_template_nice`
|
||||
|
||||
- `cpu.cpu2`
|
||||
- `cpu_template_user`
|
||||
- `cpu_template_system`
|
||||
- `cpu_template_nice`
|
||||
|
||||
- ...
|
||||
|
||||
- `cpu.cpu11`
|
||||
- `cpu_template_user`
|
||||
- `cpu_template_system`
|
||||
- `cpu_template_nice`
|
||||
|
||||
And how just a few of those dimension template-generated alerts look like in the Netdata dashboard.
|
||||
|
||||
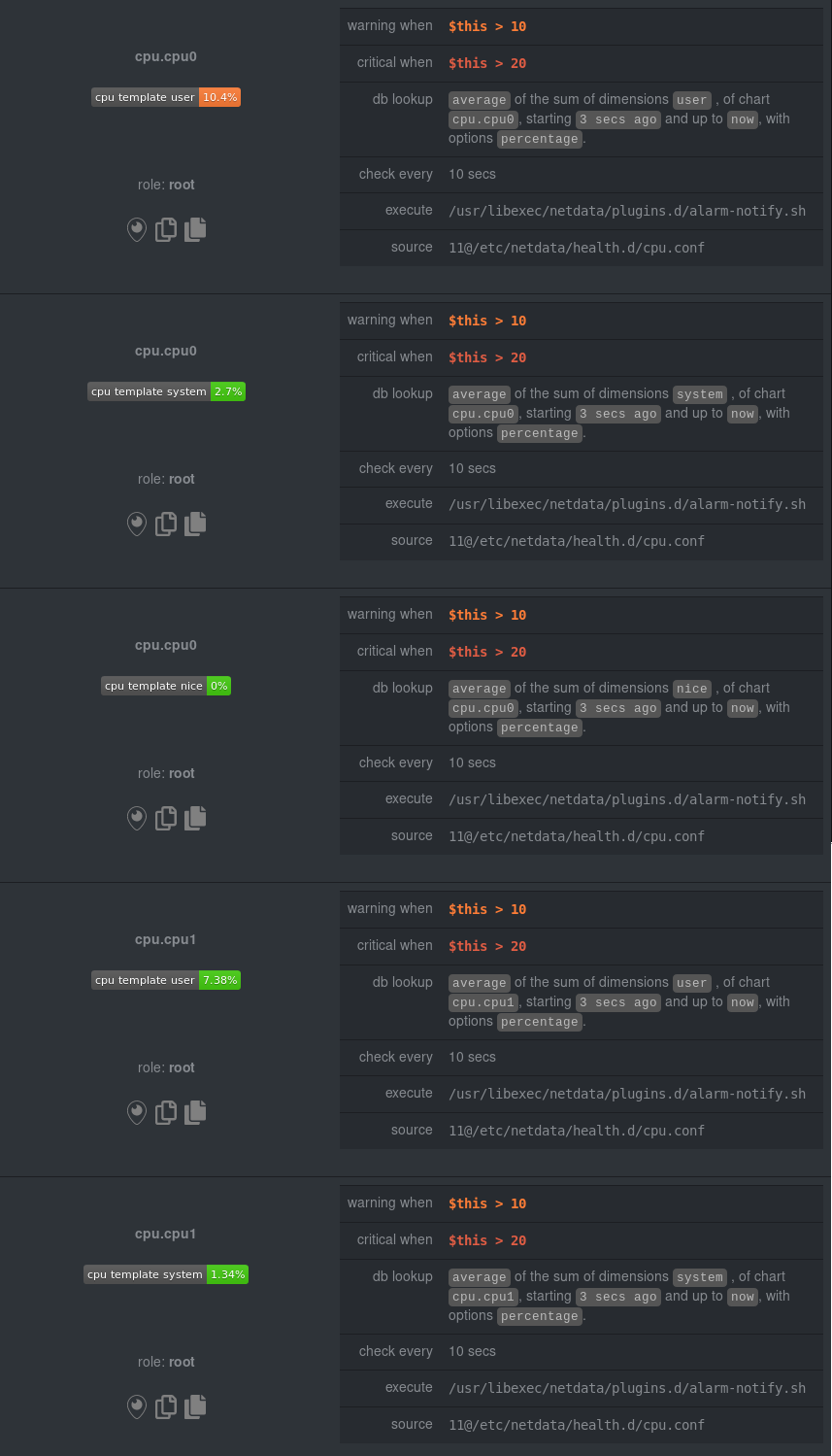
|
||||
|
||||
All in all, this single entity creates 36 individual alerts. Much easier than writing 36 separate entities in your
|
||||
health configuration files!
|
||||
The `lookup` line will use the `anomaly_rate` dimension of the `anomaly_detection.anomaly_rate` ML chart to calculate the average [node level anomaly rate](https://github.com/netdata/netdata/blob/master/src/ml/README.md#node-anomaly-rate) over the last 5 minutes.
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue