mirror of
https://github.com/netdata/netdata.git
synced 2025-04-10 08:07:34 +00:00
Reorg markdown files for learn (#14547)
* Move export graphite metrics guide content to new integrations landing page and exporter readme * Merge info on how to write python collector and reorg file * Codacy warning fixes
This commit is contained in:
parent
91b3c4296f
commit
3e507768b9
5 changed files with 315 additions and 424 deletions
collectors/python.d.plugin
docs
category-overview-pages
guides
exporting/graphite
|
|
@ -74,198 +74,4 @@ Where `[module]` is the directory name under <https://github.com/netdata/netdata
|
|||
|
||||
## How to write a new module
|
||||
|
||||
Writing new python module is simple. You just need to remember to include 5 major things:
|
||||
|
||||
- **ORDER** global list
|
||||
- **CHART** global dictionary
|
||||
- **Service** class
|
||||
- **\_get_data** method
|
||||
|
||||
If you plan to submit the module in a PR, make sure and go through the [PR checklist for new modules](#pull-request-checklist-for-python-plugins) beforehand to make sure you have updated all the files you need to.
|
||||
|
||||
For a quick start, you can look at the [example
|
||||
plugin](https://raw.githubusercontent.com/netdata/netdata/master/collectors/python.d.plugin/example/example.chart.py).
|
||||
|
||||
**Note**: If you are working 'locally' on a new collector and would like to run it in an already installed and running
|
||||
Netdata (as opposed to having to install Netdata from source again with your new changes) to can copy over the relevant
|
||||
file to where Netdata expects it and then either `sudo systemctl restart netdata` to have it be picked up and used by
|
||||
Netdata or you can just run the updated collector in debug mode by following a process like below (this assumes you have
|
||||
[installed Netdata from a GitHub fork](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/manual.md) you
|
||||
have made to do your development on).
|
||||
|
||||
```bash
|
||||
# clone your fork (done once at the start but shown here for clarity)
|
||||
#git clone --branch my-example-collector https://github.com/mygithubusername/netdata.git --depth=100 --recursive
|
||||
# go into your netdata source folder
|
||||
cd netdata
|
||||
# git pull your latest changes (assuming you built from a fork you are using to develop on)
|
||||
git pull
|
||||
# instead of running the installer we can just copy over the updated collector files
|
||||
#sudo ./netdata-installer.sh --dont-wait
|
||||
# copy over the file you have updated locally (pretending we are working on the 'example' collector)
|
||||
sudo cp collectors/python.d.plugin/example/example.chart.py /usr/libexec/netdata/python.d/
|
||||
# become user netdata
|
||||
sudo su -s /bin/bash netdata
|
||||
# run your updated collector in debug mode to see if it works without having to reinstall netdata
|
||||
/usr/libexec/netdata/plugins.d/python.d.plugin example debug trace nolock
|
||||
```
|
||||
|
||||
### Global variables `ORDER` and `CHART`
|
||||
|
||||
`ORDER` list should contain the order of chart ids. Example:
|
||||
|
||||
```py
|
||||
ORDER = ['first_chart', 'second_chart', 'third_chart']
|
||||
```
|
||||
|
||||
`CHART` dictionary is a little bit trickier. It should contain the chart definition in following format:
|
||||
|
||||
```py
|
||||
CHART = {
|
||||
id: {
|
||||
'options': [name, title, units, family, context, charttype],
|
||||
'lines': [
|
||||
[unique_dimension_name, name, algorithm, multiplier, divisor]
|
||||
]}
|
||||
```
|
||||
|
||||
All names are better explained in the [External Plugins](https://github.com/netdata/netdata/blob/master/collectors/plugins.d/README.md) section.
|
||||
Parameters like `priority` and `update_every` are handled by `python.d.plugin`.
|
||||
|
||||
### `Service` class
|
||||
|
||||
Every module needs to implement its own `Service` class. This class should inherit from one of the framework classes:
|
||||
|
||||
- `SimpleService`
|
||||
- `UrlService`
|
||||
- `SocketService`
|
||||
- `LogService`
|
||||
- `ExecutableService`
|
||||
|
||||
Also it needs to invoke the parent class constructor in a specific way as well as assign global variables to class variables.
|
||||
|
||||
Simple example:
|
||||
|
||||
```py
|
||||
from base import UrlService
|
||||
class Service(UrlService):
|
||||
def __init__(self, configuration=None, name=None):
|
||||
UrlService.__init__(self, configuration=configuration, name=name)
|
||||
self.order = ORDER
|
||||
self.definitions = CHARTS
|
||||
```
|
||||
|
||||
### `_get_data` collector/parser
|
||||
|
||||
This method should grab raw data from `_get_raw_data`, parse it, and return a dictionary where keys are unique dimension names or `None` if no data is collected.
|
||||
|
||||
Example:
|
||||
|
||||
```py
|
||||
def _get_data(self):
|
||||
try:
|
||||
raw = self._get_raw_data().split(" ")
|
||||
return {'active': int(raw[2])}
|
||||
except (ValueError, AttributeError):
|
||||
return None
|
||||
```
|
||||
|
||||
# More about framework classes
|
||||
|
||||
Every framework class has some user-configurable variables which are specific to this particular class. Those variables should have default values initialized in the child class constructor.
|
||||
|
||||
If module needs some additional user-configurable variable, it can be accessed from the `self.configuration` list and assigned in constructor or custom `check` method. Example:
|
||||
|
||||
```py
|
||||
def __init__(self, configuration=None, name=None):
|
||||
UrlService.__init__(self, configuration=configuration, name=name)
|
||||
try:
|
||||
self.baseurl = str(self.configuration['baseurl'])
|
||||
except (KeyError, TypeError):
|
||||
self.baseurl = "http://localhost:5001"
|
||||
```
|
||||
|
||||
Classes implement `_get_raw_data` which should be used to grab raw data. This method usually returns a list of strings.
|
||||
|
||||
### `SimpleService`
|
||||
|
||||
_This is last resort class, if a new module cannot be written by using other framework class this one can be used._
|
||||
|
||||
_Example: `ceph`, `sensors`_
|
||||
|
||||
It is the lowest-level class which implements most of module logic, like:
|
||||
|
||||
- threading
|
||||
- handling run times
|
||||
- chart formatting
|
||||
- logging
|
||||
- chart creation and updating
|
||||
|
||||
### `LogService`
|
||||
|
||||
_Examples: `apache_cache`, `nginx_log`_
|
||||
|
||||
_Variable from config file_: `log_path`.
|
||||
|
||||
Object created from this class reads new lines from file specified in `log_path` variable. It will check if file exists and is readable. Also `_get_raw_data` returns list of strings where each string is one line from file specified in `log_path`.
|
||||
|
||||
### `ExecutableService`
|
||||
|
||||
_Examples: `exim`, `postfix`_
|
||||
|
||||
_Variable from config file_: `command`.
|
||||
|
||||
This allows to execute a shell command in a secure way. It will check for invalid characters in `command` variable and won't proceed if there is one of:
|
||||
|
||||
- '&'
|
||||
- '|'
|
||||
- ';'
|
||||
- '>'
|
||||
- '\<'
|
||||
|
||||
For additional security it uses python `subprocess.Popen` (without `shell=True` option) to execute command. Command can be specified with absolute or relative name. When using relative name, it will try to find `command` in `PATH` environment variable as well as in `/sbin` and `/usr/sbin`.
|
||||
|
||||
`_get_raw_data` returns list of decoded lines returned by `command`.
|
||||
|
||||
### UrlService
|
||||
|
||||
_Examples: `apache`, `nginx`, `tomcat`_
|
||||
|
||||
_Variables from config file_: `url`, `user`, `pass`.
|
||||
|
||||
If data is grabbed by accessing service via HTTP protocol, this class can be used. It can handle HTTP Basic Auth when specified with `user` and `pass` credentials.
|
||||
|
||||
Please note that the config file can use different variables according to the specification of each module.
|
||||
|
||||
`_get_raw_data` returns list of utf-8 decoded strings (lines).
|
||||
|
||||
### SocketService
|
||||
|
||||
_Examples: `dovecot`, `redis`_
|
||||
|
||||
_Variables from config file_: `unix_socket`, `host`, `port`, `request`.
|
||||
|
||||
Object will try execute `request` using either `unix_socket` or TCP/IP socket with combination of `host` and `port`. This can access unix sockets with SOCK_STREAM or SOCK_DGRAM protocols and TCP/IP sockets in version 4 and 6 with SOCK_STREAM setting.
|
||||
|
||||
Sockets are accessed in non-blocking mode with 15 second timeout.
|
||||
|
||||
After every execution of `_get_raw_data` socket is closed, to prevent this module needs to set `_keep_alive` variable to `True` and implement custom `_check_raw_data` method.
|
||||
|
||||
`_check_raw_data` should take raw data and return `True` if all data is received otherwise it should return `False`. Also it should do it in fast and efficient way.
|
||||
|
||||
## Pull Request Checklist for Python Plugins
|
||||
|
||||
This is a generic checklist for submitting a new Python plugin for Netdata. It is by no means comprehensive.
|
||||
|
||||
At minimum, to be buildable and testable, the PR needs to include:
|
||||
|
||||
- The module itself, following proper naming conventions: `collectors/python.d.plugin/<module_dir>/<module_name>.chart.py`
|
||||
- A README.md file for the plugin under `collectors/python.d.plugin/<module_dir>`.
|
||||
- The configuration file for the module: `collectors/python.d.plugin/<module_dir>/<module_name>.conf`. Python config files are in YAML format, and should include comments describing what options are present. The instructions are also needed in the configuration section of the README.md
|
||||
- A basic configuration for the plugin in the appropriate global config file: `collectors/python.d.plugin/python.d.conf`, which is also in YAML format. Either add a line that reads `# <module_name>: yes` if the module is to be enabled by default, or one that reads `<module_name>: no` if it is to be disabled by default.
|
||||
- A makefile for the plugin at `collectors/python.d.plugin/<module_dir>/Makefile.inc`. Check an existing plugin for what this should look like.
|
||||
- A line in `collectors/python.d.plugin/Makefile.am` including the above-mentioned makefile. Place it with the other plugin includes (please keep the includes sorted alphabetically).
|
||||
- Optionally, chart information in `web/gui/dashboard_info.js`. This generally involves specifying a name and icon for the section, and may include descriptions for the section or individual charts.
|
||||
- Optionally, some default alarm configurations for your collector in `health/health.d/<module_name>.conf` and a line adding `<module_name>.conf` in `health/Makefile.am`.
|
||||
|
||||
|
||||
See [develop a custom collector in Python](https://github.com/netdata/netdata/edit/master/docs/guides/python-collector.md).
|
||||
|
|
|
|||
30
docs/category-overview-pages/integrations-overview.md
Normal file
30
docs/category-overview-pages/integrations-overview.md
Normal file
|
|
@ -0,0 +1,30 @@
|
|||
<!--
|
||||
title: "Integrations"
|
||||
sidebar_label: "Integrations"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/category-overview-pages/integrations-overview.md"
|
||||
description: "Available integrations in Netdata"
|
||||
learn_status: "Published"
|
||||
learn_rel_path: "Integrations"
|
||||
-->
|
||||
|
||||
# Netdata Integrations
|
||||
|
||||
Netdata's ability to monitor out of the box every potentially useful aspect of a node's operation is unparalleled.
|
||||
But Netdata also provides out of the box, meaningful charts and alerts for hundreds of applications, with the ability
|
||||
to be easily extended to monitor anything. See the full list of Netdata's capabilities and how you can extend them in the
|
||||
[supported collectors list](https://github.com/netdata/netdata/blobl/master/collectors/COLLECTORS.md).
|
||||
|
||||
Our out of the box alerts were created by expert professionals and have been validated on the field, countless times.
|
||||
Use them to trigger [alert notifications](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md)
|
||||
either centrally, via the
|
||||
[Cloud alert notifications](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.md)
|
||||
, or by configuring individual
|
||||
[agent notifications](https://github.com/netdata/netdata/blobl/master/health/notifications/README.md).
|
||||
|
||||
We designed Netdata with interoperability in mind. The Agent collects thousands of metrics every second, and then what
|
||||
you do with them is up to you. You can
|
||||
[store metrics in the database engine](https://github.com/netdata/netdata/blob/master/docs/guides/longer-metrics-storage.md),
|
||||
or send them to another time series database for long-term storage or further analysis using
|
||||
Netdata's [exporting engine](https://github.com/netdata/netdata/edit/master/exporting/README.md).
|
||||
|
||||
|
||||
|
|
@ -1,185 +0,0 @@
|
|||
<!--
|
||||
title: "Export and visualize Netdata metrics in Graphite"
|
||||
sidebar_label: "Export and visualize Netdata metrics in Graphite"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/guides/export/export-netdata-metrics-graphite.md"
|
||||
description: "Use Netdata to collect and export thousands of metrics to Graphite for long-term storage or further analysis."
|
||||
image: /img/seo/guides/export/export-netdata-metrics-graphite.png
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides"
|
||||
-->
|
||||
import { OneLineInstallWget } from '@site/src/components/OneLineInstall/'
|
||||
|
||||
# Export and visualize Netdata metrics in Graphite
|
||||
|
||||
Collecting metrics is an essential part of monitoring any application, service, or infrastructure, but it's not the
|
||||
final step for any developer, sysadmin, SRE, or DevOps engineer who's keeping an eye on things. To take meaningful
|
||||
action on these metrics, you may need to develop a stack of monitoring tools that work in parallel to help you diagnose
|
||||
anomalies and discover root causes faster.
|
||||
|
||||
We designed Netdata with interoperability in mind. The Agent collects thousands of metrics every second, and then what
|
||||
you do with them is up to you. You
|
||||
can [store metrics in the database engine](https://github.com/netdata/netdata/blob/master/docs/guides/longer-metrics-storage.md),
|
||||
or send them to another time series database for long-term storage or further analysis using
|
||||
Netdata's [exporting engine](https://github.com/netdata/netdata/blob/master/docs/export/external-databases.md).
|
||||
|
||||
In this guide, we'll show you how to export Netdata metrics to [Graphite](https://graphiteapp.org/) for long-term
|
||||
storage and further analysis. Graphite is a free open-source software (FOSS) tool that collects graphs numeric
|
||||
time-series data, such as all the metrics collected by the Netdata Agent itself. Using Netdata and Graphite together,
|
||||
you get more visibility into the health and performance of your entire infrastructure.
|
||||
|
||||
|
||||
|
||||
Let's get started.
|
||||
|
||||
## Install the Netdata Agent
|
||||
|
||||
If you don't have the Netdata Agent installed already, visit
|
||||
the [installation guide](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md)
|
||||
for the recommended instructions for your system. In most cases, you can use the one-line installation script:
|
||||
|
||||
<OneLineInstallWget/>
|
||||
|
||||
Once installation finishes, open your browser and navigate to `http://NODE:19999`, replacing `NODE` with the IP address
|
||||
or hostname of your system, to find the Agent dashboard.
|
||||
|
||||
## Install Graphite via Docker
|
||||
|
||||
For this guide, we'll install Graphite using Docker. See the [Docker documentation](https://docs.docker.com/get-docker/)
|
||||
for details if you don't yet have it installed on your system.
|
||||
|
||||
> If you already have Graphite installed, skip this step. If you want to install via a different method, see the
|
||||
> [Graphite installation docs](https://graphite.readthedocs.io/en/latest/install.html), with the caveat that some
|
||||
> configuration settings may be different.
|
||||
|
||||
Start up the Graphite image with `docker run`.
|
||||
|
||||
```bash
|
||||
docker run -d \
|
||||
--name graphite \
|
||||
--restart=always \
|
||||
-p 80:80 \
|
||||
-p 2003-2004:2003-2004 \
|
||||
-p 2023-2024:2023-2024 \
|
||||
-p 8125:8125/udp \
|
||||
-p 8126:8126 \
|
||||
graphiteapp/graphite-statsd
|
||||
```
|
||||
|
||||
Open your browser and navigate to `http://NODE`, to see the Graphite interface. Nothing yet, but we'll fix that soon
|
||||
enough.
|
||||
|
||||
|
||||
|
||||
## Enable the Graphite exporting connector
|
||||
|
||||
You're now ready to begin exporting Netdata metrics to Graphite.
|
||||
|
||||
Begin by using `edit-config` to open the `exporting.conf` file.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory
|
||||
sudo ./edit-config exporting.conf
|
||||
```
|
||||
|
||||
If you haven't already, enable the exporting engine by setting `enabled` to `yes` in the `[exporting:global]` section.
|
||||
|
||||
```conf
|
||||
[exporting:global]
|
||||
enabled = yes
|
||||
```
|
||||
|
||||
Next, configure the connector. Find the `[graphite:my_graphite_instance]` example section and uncomment the line.
|
||||
Replace `my_graphite_instance` with a name of your choice. Let's go with `[graphite:netdata]`. Set `enabled` to `yes`
|
||||
and uncomment the line. Your configuration should now look like this:
|
||||
|
||||
```conf
|
||||
[graphite:netdata]
|
||||
enabled = yes
|
||||
# destination = localhost
|
||||
# data source = average
|
||||
# prefix = netdata
|
||||
# hostname = my_hostname
|
||||
# update every = 10
|
||||
# buffer on failures = 10
|
||||
# timeout ms = 20000
|
||||
# send names instead of ids = yes
|
||||
# send charts matching = *
|
||||
# send hosts matching = localhost *
|
||||
```
|
||||
|
||||
Set the `destination` setting to `localhost:2003`. By default, the Docker image for Graphite listens on port `2003` for
|
||||
incoming metrics. If you installed Graphite a different way, or tweaked the `docker run` command, you may need to change
|
||||
the port accordingly.
|
||||
|
||||
```conf
|
||||
[graphite:netdata]
|
||||
enabled = yes
|
||||
destination = localhost:2003
|
||||
...
|
||||
```
|
||||
|
||||
We'll not worry about the rest of the settings for now. Restart the Agent using `sudo systemctl restart netdata`, or the
|
||||
[appropriate method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your
|
||||
system, to spin up the exporting engine.
|
||||
|
||||
## See and organize Netdata metrics in Graphite
|
||||
|
||||
Head back to the Graphite interface again, then click on the **Dashboard** link to get started with Netdata's exported
|
||||
metrics. You can also navigate directly to `http://NODE/dashboard`.
|
||||
|
||||
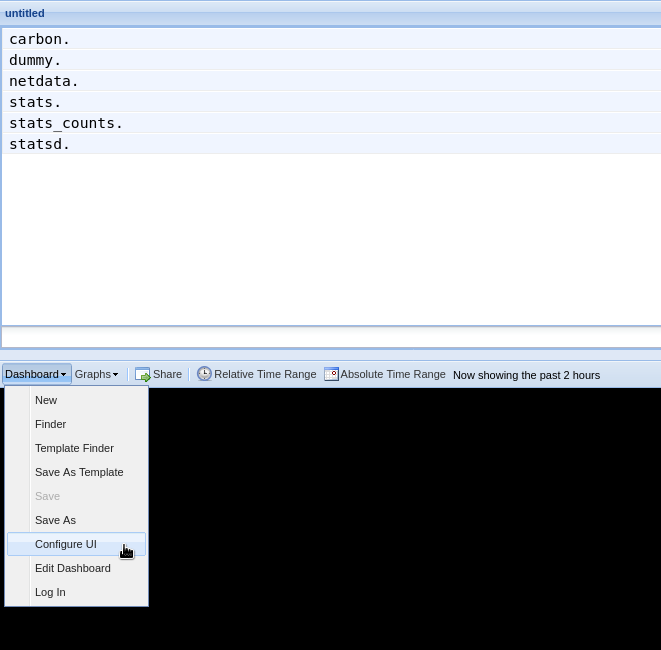
Let's switch the interface to help you understand which metrics Netdata is exporting to Graphite. Click on **Dashboard**
|
||||
and **Configure UI**, then choose the **Tree** option. Refresh your browser to change the UI.
|
||||
|
||||
|
||||
|
||||
You should now see a tree of available contexts, including one that matches the hostname of the Agent exporting metrics.
|
||||
In this example, the Agent's hostname is `arcturus`.
|
||||
|
||||
Let's add some system CPU charts so you can monitor the long-term health of your system. Click through the tree to find
|
||||
**hostname → system → cpu** metrics, then click on the **user** context. A chart with metrics from that context appears
|
||||
in the dashboard. Add a few other system CPU charts to flesh things out.
|
||||
|
||||
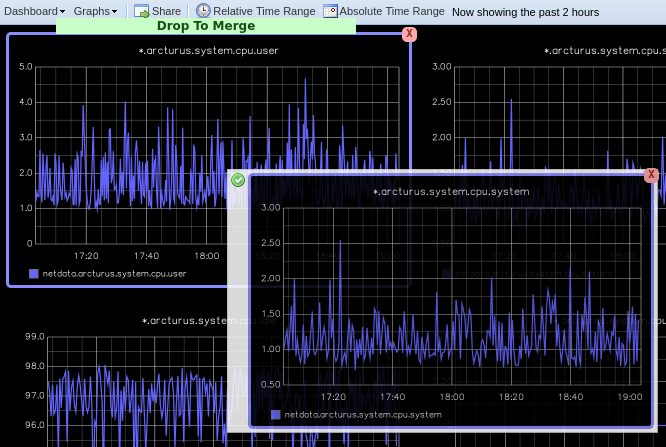
Next, let's combine one or two of these charts. Click and drag one chart onto the other, and wait until the green **Drop
|
||||
to merge** dialog appears. Release to merge the charts.
|
||||
|
||||
|
||||
|
||||
Finally, save your dashboard. Click **Dashboard**, then **Save As**, then choose a name. Your dashboard is now saved.
|
||||
|
||||
Of course, this is just the beginning of the customization you can do with Graphite. You can change the time range,
|
||||
share your dashboard with others, or use the composer to customize the size and appearance of specific charts. Learn
|
||||
more about adding, modifying, and combining graphs in
|
||||
the [Graphite docs](https://graphite.readthedocs.io/en/latest/dashboard.html).
|
||||
|
||||
## Monitor the exporting engine
|
||||
|
||||
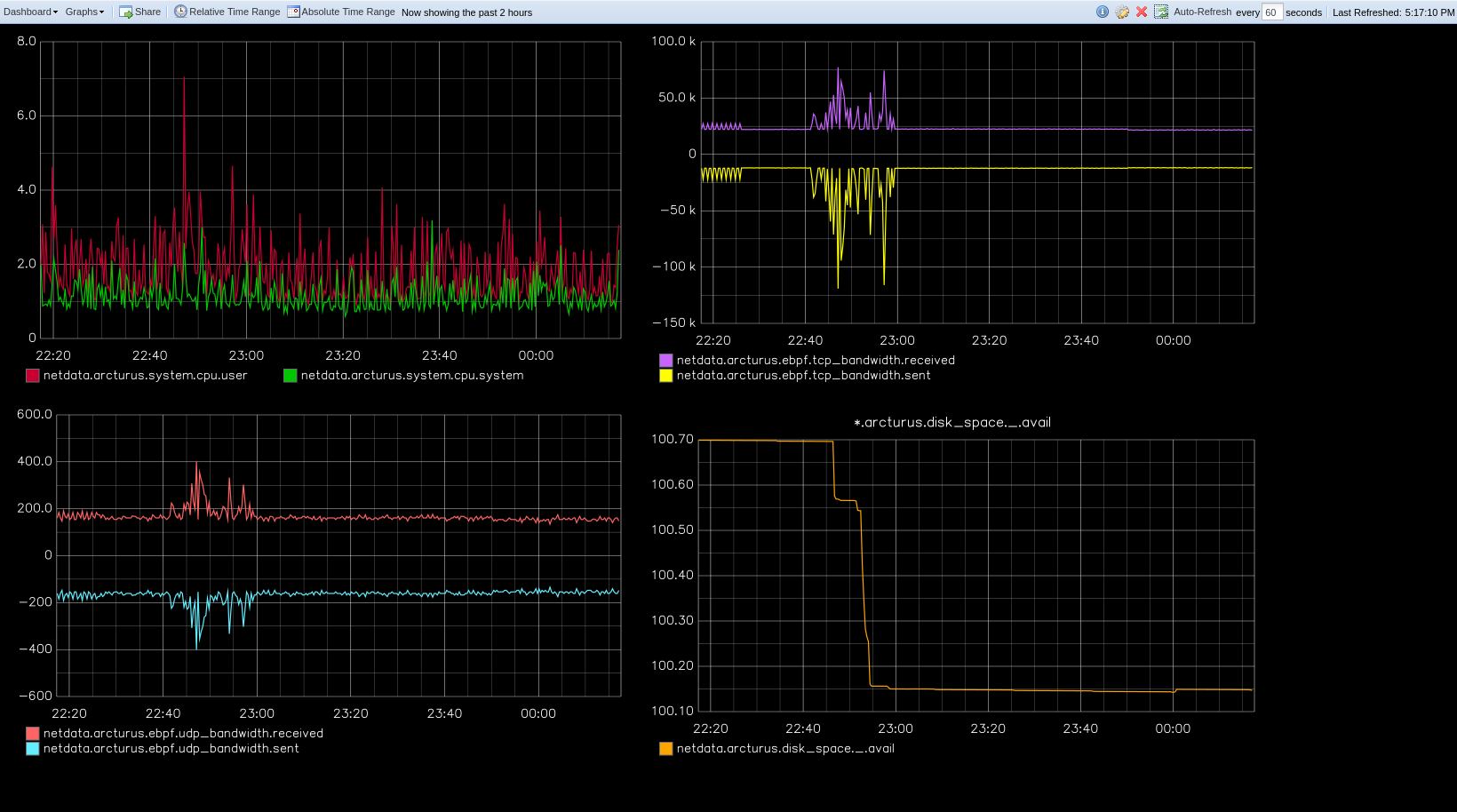
As soon as the exporting engine begins, Netdata begins reporting metrics about the system's health and performance.
|
||||
|
||||
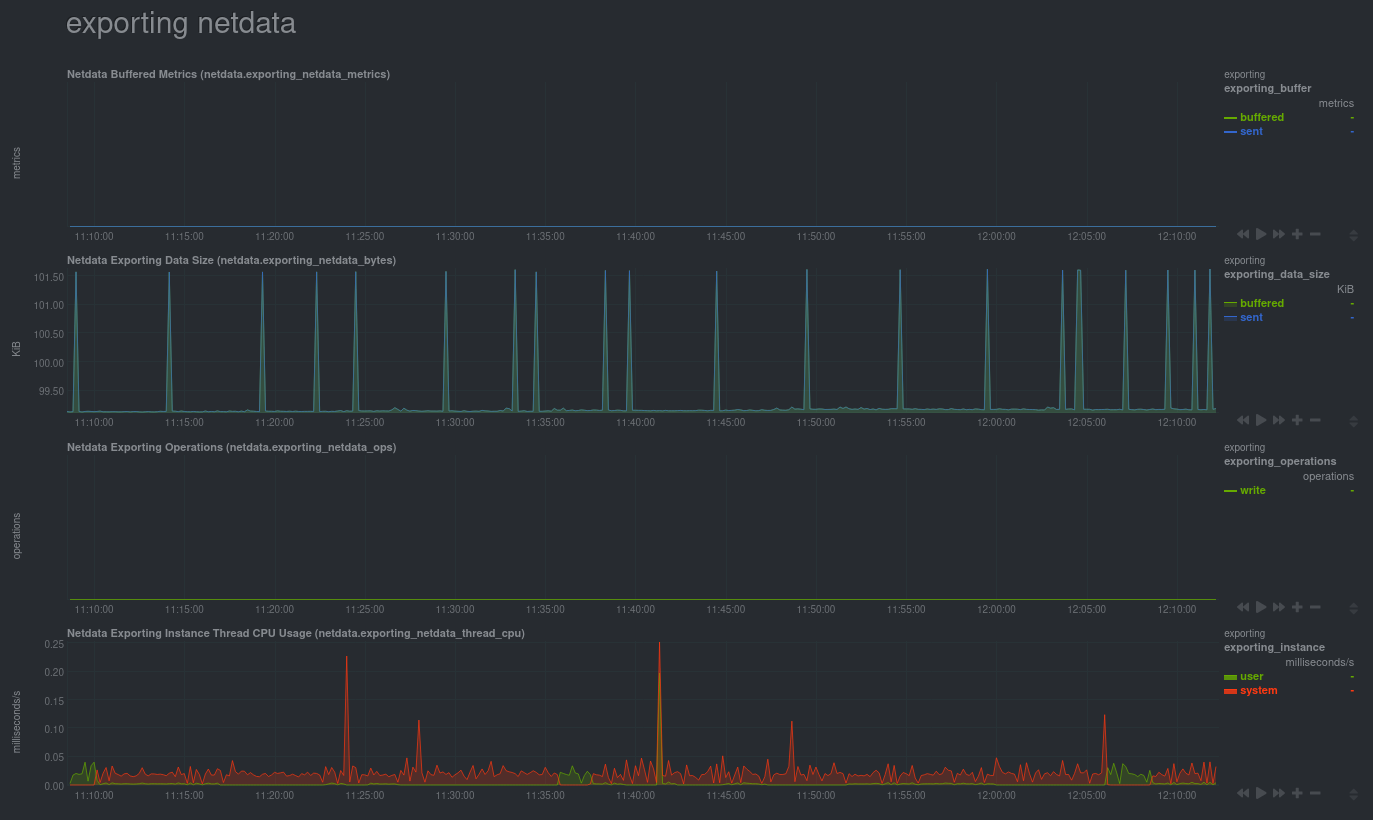
|
||||
|
||||
You can use these charts to verify that Netdata is properly exporting metrics to Graphite. You can even add these
|
||||
exporting charts to your Graphite dashboard!
|
||||
|
||||
### Add exporting charts to Netdata Cloud
|
||||
|
||||
You can also show these exporting engine metrics on Netdata Cloud. If you don't have an account already,
|
||||
go [sign in](https://app.netdata.cloud) and get started for free.
|
||||
|
||||
Add more metrics to a War Room's Nodes view by clicking on the **Add metric** button, then typing `exporting` into the
|
||||
context field. Choose the exporting contexts you want to add, then click **Add**. You'll see these charts alongside any
|
||||
others you've customized in Netdata Cloud.
|
||||
|
||||
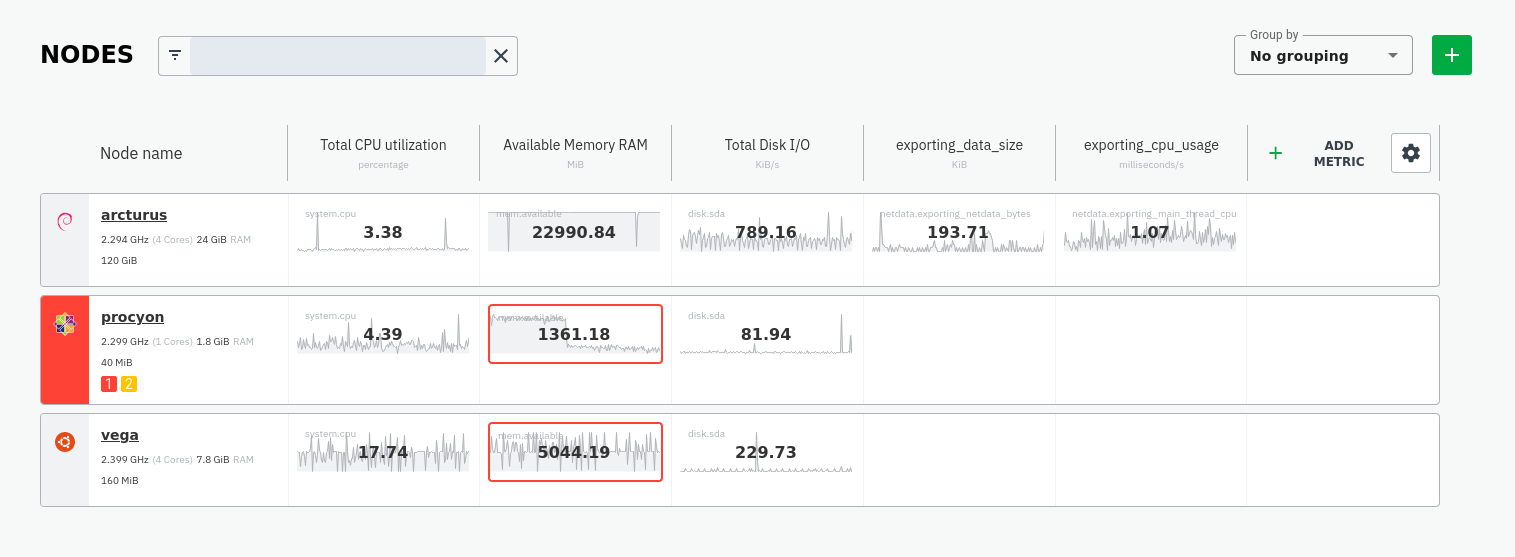
|
||||
|
||||
## What's next?
|
||||
|
||||
What you do with your exported metrics is entirely up to you, but as you might have seen in the Graphite connector
|
||||
configuration block, there are many other ways to tweak and customize which metrics you export to Graphite and how
|
||||
often.
|
||||
|
||||
For full details about each configuration option and what it does, see
|
||||
the [exporting reference guide](https://github.com/netdata/netdata/blob/master/exporting/README.md).
|
||||
|
||||
|
||||
|
|
@ -8,32 +8,58 @@ author_title: "University of Patras"
|
|||
author_img: "/img/authors/panagiotis-papaioannou.jpg"
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/python-collector.md
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Guides"
|
||||
learn_rel_path: "Developers/External plugins/python.d.plugin"
|
||||
-->
|
||||
|
||||
# Develop a custom data collector in Python
|
||||
|
||||
The Netdata Agent uses [data collectors](https://github.com/netdata/netdata/blob/master/collectors/README.md) to fetch metrics from hundreds of system,
|
||||
container, and service endpoints. While the Netdata team and community has built [powerful
|
||||
collectors](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md) for most system, container, and service/application endpoints, there are plenty
|
||||
of custom applications that can't be monitored by default.
|
||||
|
||||
## Problem
|
||||
|
||||
You have a custom application or infrastructure that you need to monitor, but no open-source monitoring tool offers a
|
||||
prebuilt method for collecting your required metric data.
|
||||
|
||||
## Solution
|
||||
The Netdata Agent uses [data collectors](https://github.com/netdata/netdata/blob/master/collectors/README.md) to
|
||||
fetch metrics from hundreds of system, container, and service endpoints. While the Netdata team and community has built
|
||||
[powerful collectors](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md) for most system, container,
|
||||
and service/application endpoints, some custom applications can't be monitored by default.
|
||||
|
||||
In this tutorial, you'll learn how to leverage the [Python programming language](https://www.python.org/) to build a
|
||||
custom data collector for the Netdata Agent. Follow along with your own dataset, using the techniques and best practices
|
||||
covered here, or use the included examples for collecting and organizing either random or weather data.
|
||||
|
||||
If you're comfortable with Golang, consider instead writing a module for the [go.d.plugin](https://github.com/netdata/go.d.plugin).
|
||||
Golang is more performant, easier to maintain, and simpler for users since it doesn't require a particular runtime on the node to
|
||||
execute. Python plugins require Python on the machine to be executed. Netdata uses Go as the platform of choice for
|
||||
production-grade collectors.
|
||||
|
||||
## What you need to get started
|
||||
|
||||
- A physical or virtual Linux system, which we'll call a _node_.
|
||||
- A working installation of the free and open-source [Netdata](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md) monitoring agent.
|
||||
- A physical or virtual Linux system, which we'll call a _node_.
|
||||
- A working [installation of Netdata](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md) monitoring agent.
|
||||
|
||||
### Quick start
|
||||
|
||||
For a quick start, you can look at the
|
||||
[example plugin](https://raw.githubusercontent.com/netdata/netdata/master/collectors/python.d.plugin/example/example.chart.py).
|
||||
|
||||
**Note**: If you are working 'locally' on a new collector and would like to run it in an already installed and running
|
||||
Netdata (as opposed to having to install Netdata from source again with your new changes) you can copy over the relevant
|
||||
file to where Netdata expects it and then either `sudo systemctl restart netdata` to have it be picked up and used by
|
||||
Netdata or you can just run the updated collector in debug mode by following a process like below (this assumes you have
|
||||
[installed Netdata from a GitHub fork](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/manual.md) you
|
||||
have made to do your development on).
|
||||
|
||||
```bash
|
||||
# clone your fork (done once at the start but shown here for clarity)
|
||||
#git clone --branch my-example-collector https://github.com/mygithubusername/netdata.git --depth=100 --recursive
|
||||
# go into your netdata source folder
|
||||
cd netdata
|
||||
# git pull your latest changes (assuming you built from a fork you are using to develop on)
|
||||
git pull
|
||||
# instead of running the installer we can just copy over the updated collector files
|
||||
#sudo ./netdata-installer.sh --dont-wait
|
||||
# copy over the file you have updated locally (pretending we are working on the 'example' collector)
|
||||
sudo cp collectors/python.d.plugin/example/example.chart.py /usr/libexec/netdata/python.d/
|
||||
# become user netdata
|
||||
sudo su -s /bin/bash netdata
|
||||
# run your updated collector in debug mode to see if it works without having to reinstall netdata
|
||||
/usr/libexec/netdata/plugins.d/python.d.plugin example debug trace nolock
|
||||
```
|
||||
|
||||
## Jobs and elements of a Python collector
|
||||
|
||||
|
|
@ -54,6 +80,11 @@ The basic elements of a Netdata collector are:
|
|||
- `data{}`: A dictionary containing the values to be displayed.
|
||||
- `get_data()`: The basic function of the plugin which will return to Netdata the correct values.
|
||||
|
||||
**Note**: All names are better explained in the
|
||||
[External Plugins Documentation](https://github.com/netdata/netdata/blob/master/collectors/plugins.d/README.md).
|
||||
Parameters like `priority` and `update_every` mentioned in that documentation are handled by the `python.d.plugin`,
|
||||
not by each collection module.
|
||||
|
||||
Let's walk through these jobs and elements as independent elements first, then apply them to example Python code.
|
||||
|
||||
### Determine how to gather metrics data
|
||||
|
|
@ -139,11 +170,18 @@ correct values.
|
|||
|
||||
## Framework classes
|
||||
|
||||
The `python.d` plugin has a number of framework classes that can be used to speed up the development of your python
|
||||
collector. Your class can inherit one of these framework classes, which have preconfigured methods.
|
||||
Every module needs to implement its own `Service` class. This class should inherit from one of the framework classes:
|
||||
|
||||
For example, the snippet below is from the [RabbitMQ
|
||||
collector](https://github.com/netdata/netdata/blob/91f3268e9615edd393bd43de4ad8068111024cc9/collectors/python.d.plugin/rabbitmq/rabbitmq.chart.py#L273).
|
||||
- `SimpleService`
|
||||
- `UrlService`
|
||||
- `SocketService`
|
||||
- `LogService`
|
||||
- `ExecutableService`
|
||||
|
||||
Also it needs to invoke the parent class constructor in a specific way as well as assign global variables to class variables.
|
||||
|
||||
For example, the snippet below is from the
|
||||
[RabbitMQ collector](https://github.com/netdata/netdata/blob/91f3268e9615edd393bd43de4ad8068111024cc9/collectors/python.d.plugin/rabbitmq/rabbitmq.chart.py#L273).
|
||||
This collector uses an HTTP endpoint and uses the `UrlService` framework class, which only needs to define an HTTP
|
||||
endpoint for data collection.
|
||||
|
||||
|
|
@ -170,8 +208,7 @@ class Service(UrlService):
|
|||
|
||||
In our use-case, we use the `SimpleService` framework, since there is no framework class that suits our needs.
|
||||
|
||||
You can read more about the [framework classes](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/README.md#how-to-write-a-new-module) from
|
||||
the Netdata documentation.
|
||||
You can find below the [framework class reference](#framework-class-reference).
|
||||
|
||||
## An example collector using weather station data
|
||||
|
||||
|
|
@ -200,6 +237,35 @@ CHARTS = {
|
|||
|
||||
## Parse the data to extract or create the actual data to be represented
|
||||
|
||||
Every collector must implement `_get_data`. This method should grab raw data from `_get_raw_data`,
|
||||
parse it, and return a dictionary where keys are unique dimension names, or `None` if no data is collected.
|
||||
|
||||
For example:
|
||||
```py
|
||||
def _get_data(self):
|
||||
try:
|
||||
raw = self._get_raw_data().split(" ")
|
||||
return {'active': int(raw[2])}
|
||||
except (ValueError, AttributeError):
|
||||
return None
|
||||
```
|
||||
|
||||
In our weather data collector we declare `_get_data` as follows:
|
||||
|
||||
```python
|
||||
def get_data(self):
|
||||
#The data dict is basically all the values to be represented
|
||||
# The entries are in the format: { "dimension": value}
|
||||
#And each "dimension" should belong to a chart.
|
||||
data = dict()
|
||||
|
||||
self.populate_data()
|
||||
|
||||
data['current_temperature'] = self.weather_data["temp"]
|
||||
|
||||
return data
|
||||
```
|
||||
|
||||
A standard practice would be to either get the data on JSON format or transform them to JSON format. We use a dictionary
|
||||
to give this format and issue random values to simulate received data.
|
||||
|
||||
|
|
@ -465,26 +531,102 @@ variables and inform the user about the defaults. For example, take a look at th
|
|||
You can read more about the configuration file on the [`python.d.plugin`
|
||||
documentation](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/README.md).
|
||||
|
||||
## What's next?
|
||||
You can find the source code for the above examples on [GitHub](https://github.com/papajohn-uop/netdata).
|
||||
|
||||
Find the source code for the above examples on [GitHub](https://github.com/papajohn-uop/netdata).
|
||||
## Pull Request Checklist for Python Plugins
|
||||
|
||||
Now you are ready to start developing our Netdata python Collector and share it with the rest of the Netdata community.
|
||||
This is a generic checklist for submitting a new Python plugin for Netdata. It is by no means comprehensive.
|
||||
|
||||
- If you need help while developing your collector, join our [Netdata
|
||||
Community](https://community.netdata.cloud/c/agent-development/9) to chat about it.
|
||||
- Follow the
|
||||
[checklist](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/README.md#pull-request-checklist-for-python-plugins)
|
||||
to contribute the collector to the Netdata Agent [repository](https://github.com/netdata/netdata).
|
||||
- Check out the [example](https://github.com/netdata/netdata/tree/master/collectors/python.d.plugin/example) Python
|
||||
collector, which is a minimal example collector you could also use as a starting point. Once comfortable with that,
|
||||
then browse other [existing collectors](https://github.com/netdata/netdata/tree/master/collectors/python.d.plugin)
|
||||
that might have similarities to what you want to do.
|
||||
- If you're developing a proof of concept (PoC), consider migrating the collector in Golang
|
||||
([go.d.plugin](https://github.com/netdata/go.d.plugin)) once you validate its value in production. Golang is more
|
||||
performant, easier to maintain, and simpler for users since it doesn't require a particular runtime on the node to
|
||||
execute (Python plugins require Python on the machine to be executed). Netdata uses Go as the platform of choice for
|
||||
production-grade collectors.
|
||||
- Celebrate! You have contributed to an open-source project with hundreds of thousands of users!
|
||||
At minimum, to be buildable and testable, the PR needs to include:
|
||||
|
||||
- The module itself, following proper naming conventions: `collectors/python.d.plugin/<module_dir>/<module_name>.chart.py`
|
||||
- A README.md file for the plugin under `collectors/python.d.plugin/<module_dir>`.
|
||||
- The configuration file for the module: `collectors/python.d.plugin/<module_dir>/<module_name>.conf`. Python config files are in YAML format, and should include comments describing what options are present. The instructions are also needed in the configuration section of the README.md
|
||||
- A basic configuration for the plugin in the appropriate global config file: `collectors/python.d.plugin/python.d.conf`, which is also in YAML format. Either add a line that reads `# <module_name>: yes` if the module is to be enabled by default, or one that reads `<module_name>: no` if it is to be disabled by default.
|
||||
- A makefile for the plugin at `collectors/python.d.plugin/<module_dir>/Makefile.inc`. Check an existing plugin for what this should look like.
|
||||
- A line in `collectors/python.d.plugin/Makefile.am` including the above-mentioned makefile. Place it with the other plugin includes (please keep the includes sorted alphabetically).
|
||||
- Optionally, chart information in `web/gui/dashboard_info.js`. This generally involves specifying a name and icon for the section, and may include descriptions for the section or individual charts.
|
||||
- Optionally, some default alarm configurations for your collector in `health/health.d/<module_name>.conf` and a line adding `<module_name>.conf` in `health/Makefile.am`.
|
||||
|
||||
## Framework class reference
|
||||
|
||||
Every framework class has some user-configurable variables which are specific to this particular class. Those variables should have default values initialized in the child class constructor.
|
||||
|
||||
If module needs some additional user-configurable variable, it can be accessed from the `self.configuration` list and assigned in constructor or custom `check` method. Example:
|
||||
|
||||
```py
|
||||
def __init__(self, configuration=None, name=None):
|
||||
UrlService.__init__(self, configuration=configuration, name=name)
|
||||
try:
|
||||
self.baseurl = str(self.configuration['baseurl'])
|
||||
except (KeyError, TypeError):
|
||||
self.baseurl = "http://localhost:5001"
|
||||
```
|
||||
|
||||
Classes implement `_get_raw_data` which should be used to grab raw data. This method usually returns a list of strings.
|
||||
|
||||
### `SimpleService`
|
||||
|
||||
This is last resort class, if a new module cannot be written by using other framework class this one can be used.
|
||||
|
||||
Example: `ceph`, `sensors`
|
||||
|
||||
It is the lowest-level class which implements most of module logic, like:
|
||||
|
||||
- threading
|
||||
- handling run times
|
||||
- chart formatting
|
||||
- logging
|
||||
- chart creation and updating
|
||||
|
||||
### `LogService`
|
||||
|
||||
Examples: `apache_cache`, `nginx_log`_
|
||||
|
||||
Variable from config file: `log_path`.
|
||||
|
||||
Object created from this class reads new lines from file specified in `log_path` variable. It will check if file exists and is readable. Also `_get_raw_data` returns list of strings where each string is one line from file specified in `log_path`.
|
||||
|
||||
### `ExecutableService`
|
||||
|
||||
Examples: `exim`, `postfix`_
|
||||
|
||||
Variable from config file: `command`.
|
||||
|
||||
This allows to execute a shell command in a secure way. It will check for invalid characters in `command` variable and won't proceed if there is one of:
|
||||
|
||||
- '&'
|
||||
- '|'
|
||||
- ';'
|
||||
- '>'
|
||||
- '\<'
|
||||
|
||||
For additional security it uses python `subprocess.Popen` (without `shell=True` option) to execute command. Command can be specified with absolute or relative name. When using relative name, it will try to find `command` in `PATH` environment variable as well as in `/sbin` and `/usr/sbin`.
|
||||
|
||||
`_get_raw_data` returns list of decoded lines returned by `command`.
|
||||
|
||||
### UrlService
|
||||
|
||||
Examples: `apache`, `nginx`, `tomcat`_
|
||||
|
||||
Variables from config file: `url`, `user`, `pass`.
|
||||
|
||||
If data is grabbed by accessing service via HTTP protocol, this class can be used. It can handle HTTP Basic Auth when specified with `user` and `pass` credentials.
|
||||
|
||||
Please note that the config file can use different variables according to the specification of each module.
|
||||
|
||||
`_get_raw_data` returns list of utf-8 decoded strings (lines).
|
||||
|
||||
### SocketService
|
||||
|
||||
Examples: `dovecot`, `redis`
|
||||
|
||||
Variables from config file: `unix_socket`, `host`, `port`, `request`.
|
||||
|
||||
Object will try execute `request` using either `unix_socket` or TCP/IP socket with combination of `host` and `port`. This can access unix sockets with SOCK_STREAM or SOCK_DGRAM protocols and TCP/IP sockets in version 4 and 6 with SOCK_STREAM setting.
|
||||
|
||||
Sockets are accessed in non-blocking mode with 15 second timeout.
|
||||
|
||||
After every execution of `_get_raw_data` socket is closed, to prevent this module needs to set `_keep_alive` variable to `True` and implement custom `_check_raw_data` method.
|
||||
|
||||
`_check_raw_data` should take raw data and return `True` if all data is received otherwise it should return `False`. Also it should do it in fast and efficient way.
|
||||
|
|
|
|||
|
|
@ -13,15 +13,36 @@ You can use the Graphite connector for
|
|||
the [exporting engine](https://github.com/netdata/netdata/blob/master/exporting/README.md) to archive your agent's
|
||||
metrics to Graphite providers for long-term storage, further analysis, or correlation with data from other sources.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
You have already [installed Netdata](https://github.com/netdata/netdata/edit/master/packaging/installer/README.md) and
|
||||
Graphite.
|
||||
|
||||
## Configuration
|
||||
|
||||
To enable data exporting to a Graphite database, run `./edit-config exporting.conf` in the Netdata configuration
|
||||
directory and set the following options:
|
||||
Begin by using `edit-config` to open the `exporting.conf` file.
|
||||
|
||||
```bash
|
||||
cd /etc/netdata # Replace this path with your Netdata config directory
|
||||
sudo ./edit-config exporting.conf
|
||||
```
|
||||
|
||||
Enable the exporting engine by setting `enabled` to `yes` in the `[exporting:global]` section.
|
||||
|
||||
```conf
|
||||
[graphite:my_graphite_instance]
|
||||
[exporting:global]
|
||||
enabled = yes
|
||||
```
|
||||
|
||||
Next, configure the connector. Find the `[graphite:my_graphite_instance]` example section and uncomment the line.
|
||||
Set the `destination` setting to `localhost:2003`. By default, the Docker image for Graphite listens on port `2003` for
|
||||
incoming metrics. If you installed Graphite a different way, you may need to change the port accordingly.
|
||||
|
||||
```conf
|
||||
[graphite:netdata]
|
||||
enabled = yes
|
||||
destination = localhost:2003
|
||||
...
|
||||
```
|
||||
|
||||
Add `:http` or `:https` modifiers to the connector type if you need to use other than a plaintext protocol. For
|
||||
|
|
@ -33,7 +54,84 @@ example: `graphite:http:my_graphite_instance`,
|
|||
password = my_password
|
||||
```
|
||||
|
||||
The Graphite connector is further configurable using additional settings. See
|
||||
the [exporting reference doc](https://github.com/netdata/netdata/blob/master/exporting/README.md#options) for details.
|
||||
The final result for a remote, secured host should be the following:
|
||||
|
||||
```conf
|
||||
[graphite:https:netdata]
|
||||
enabled = yes
|
||||
username = my_username
|
||||
password = my_password
|
||||
destination = remote_host_url:2003
|
||||
# data source = average
|
||||
# prefix = netdata
|
||||
# hostname = my_hostname
|
||||
# update every = 10
|
||||
# buffer on failures = 10
|
||||
# timeout ms = 20000
|
||||
# send names instead of ids = yes
|
||||
# send charts matching = *
|
||||
# send hosts matching = localhost *
|
||||
```
|
||||
|
||||
We'll not worry about the [rest of the settings](https://github.com/netdata/netdata/blob/master/exporting/README.md#options)
|
||||
for now. Restart the Agent using `sudo systemctl restart netdata`, or the
|
||||
[appropriate method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your
|
||||
system, to spin up the exporting engine.
|
||||
|
||||
## See and organize Netdata metrics in Graphite
|
||||
|
||||
Head back to the Graphite interface again, then click on the **Dashboard** link to get started with Netdata's exported
|
||||
metrics. You can also navigate directly to `http://NODE/dashboard`.
|
||||
|
||||
Let's switch the interface to help you understand which metrics Netdata is exporting to Graphite. Click on **Dashboard**
|
||||
and **Configure UI**, then choose the **Tree** option. Refresh your browser to change the UI.
|
||||
|
||||

|
||||
|
||||
You should now see a tree of available contexts, including one that matches the hostname of the Agent exporting metrics.
|
||||
In this example, the Agent's hostname is `arcturus`.
|
||||
|
||||
Let's add some system CPU charts so you can monitor the long-term health of your system. Click through the tree to find
|
||||
**hostname → system → cpu** metrics, then click on the **user** context. A chart with metrics from that context appears
|
||||
in the dashboard. Add a few other system CPU charts to flesh things out.
|
||||
|
||||
Next, let's combine one or two of these charts. Click and drag one chart onto the other, and wait until the green **Drop
|
||||
to merge** dialog appears. Release to merge the charts.
|
||||
|
||||

|
||||
|
||||
Finally, save your dashboard. Click **Dashboard**, then **Save As**, then choose a name. Your dashboard is now saved.
|
||||
|
||||
Of course, this is just the beginning of the customization you can do with Graphite. You can change the time range,
|
||||
share your dashboard with others, or use the composer to customize the size and appearance of specific charts. Learn
|
||||
more about adding, modifying, and combining graphs in
|
||||
the [Graphite docs](https://graphite.readthedocs.io/en/latest/dashboard.html).
|
||||
|
||||
## Monitor the exporting engine
|
||||
|
||||
As soon as the exporting engine begins, Netdata begins reporting metrics about the system's health and performance.
|
||||
|
||||

|
||||
|
||||
You can use these charts to verify that Netdata is properly exporting metrics to Graphite. You can even add these
|
||||
exporting charts to your Graphite dashboard!
|
||||
|
||||
### Add exporting charts to Netdata Cloud
|
||||
|
||||
You can also show these exporting engine metrics on Netdata Cloud. If you don't have an account already,
|
||||
go [sign in](https://app.netdata.cloud) and get started for free.
|
||||
|
||||
Add more metrics to a War Room's Nodes view by clicking on the **Add metric** button, then typing `exporting` into the
|
||||
context field. Choose the exporting contexts you want to add, then click **Add**. You'll see these charts alongside any
|
||||
others you've customized in Netdata Cloud.
|
||||
|
||||

|
||||
|
||||
## What's next
|
||||
|
||||
What you do with your exported metrics is entirely up to you, but as you might have seen in the Graphite connector
|
||||
configuration block, there are many other ways to tweak and customize which metrics you export to Graphite and how
|
||||
often.
|
||||
|
||||
For full details about each configuration option and what it does, see
|
||||
the [exporting reference guide](https://github.com/netdata/netdata/blob/master/exporting/README.md).
|
||||
|
|
|
|||
Loading…
Add table
Reference in a new issue