mirror of
https://github.com/netdata/netdata.git
synced 2025-04-13 17:19:11 +00:00
Reorg learn 0227 (#14621)
* reorg batch 1 * remove duplicate cloud custom dashboard and agent dashboard * Simplify the root web/README * Merge streaming references * Make enable streaming the overall intro and the README the reference * Remove reference-streaming document * Update overview pages
This commit is contained in:
parent
9fabe2340f
commit
8c73c47645
23 changed files with 629 additions and 2327 deletions
docs
category-overview-pages
concepts-overview.mddevelopers-overview.mdoperations-overview.mdtroubleshooting-overview.mdvisualizations-overview.md
contributing
dashboard
glossary.mdguidelines.mdguides/troubleshoot
metrics-storage-management
quickstart
visualize
exporting
health
packaging/installer
streaming
web
|
|
@ -1,10 +0,0 @@
|
|||
<!--
|
||||
title: "Concepts"
|
||||
sidebar_label: "Concepts"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/category-overview-pages/concepts-overview.md"
|
||||
learn_status: "Published"
|
||||
learn_rel_path: "Concepts"
|
||||
sidebar_position: 10
|
||||
-->
|
||||
|
||||
This category will help you understand how key features and components work in Netdata.
|
||||
|
|
@ -1,10 +0,0 @@
|
|||
<!--
|
||||
title: "Developers"
|
||||
sidebar_label: "Developers"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/category-overview-pages/developers-overview.md"
|
||||
learn_status: "Published"
|
||||
learn_rel_path: "Developers"
|
||||
sidebar_position: 100
|
||||
-->
|
||||
|
||||
In this category you will find information that will aid you while developing with Netdata.
|
||||
|
|
@ -1,10 +0,0 @@
|
|||
<!--
|
||||
title: "Operations"
|
||||
sidebar_label: "Operations"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/category-overview-pages/operations-overview.md"
|
||||
learn_status: "Published"
|
||||
learn_rel_path: "Operations"
|
||||
sidebar_position: 40
|
||||
-->
|
||||
|
||||
In this category you will find all the instructions on "operations" you can perform with Netdata, whether that would be using the Anomaly Advisor to surface any potential unexpected behavior, or how to interact with the charts etc.
|
||||
5
docs/category-overview-pages/troubleshooting-overview.md
Normal file
5
docs/category-overview-pages/troubleshooting-overview.md
Normal file
|
|
@ -0,0 +1,5 @@
|
|||
# Troubleshooting and machine learning
|
||||
|
||||
In this section you can learn about Netdata's advanced tools that can assist you in troubleshooting issues with
|
||||
your infrastructure, to facilitate the identification of a root cause.
|
||||
|
||||
4
docs/category-overview-pages/visualizations-overview.md
Normal file
4
docs/category-overview-pages/visualizations-overview.md
Normal file
|
|
@ -0,0 +1,4 @@
|
|||
# Visualizations, charts and dashboards
|
||||
|
||||
In this section you can learn about the various ways Netdata visualizes the collected metrics at an infrastructure level with Netdata Cloud
|
||||
and at a single node level, with the Netdata Agent Dashboard.
|
||||
|
|
@ -1,13 +1,3 @@
|
|||
<!--
|
||||
title: "Netdata style guide"
|
||||
description: "The Netdata style guide establishes editorial guidelines for all of Netdata's writing, including documentation, blog posts, in-product UX copy, and more."
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/contributing/style-guide.md
|
||||
sidebar_label: "Netdata style guide"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "References"
|
||||
learn_rel_path: "Contribute"
|
||||
-->
|
||||
|
||||
# Netdata style guide
|
||||
|
||||
The _Netdata style guide_ establishes editorial guidelines for any writing produced by the Netdata team or the Netdata
|
||||
|
|
@ -357,34 +347,6 @@ The Netdata team uses [`remark-lint`](https://github.com/remarkjs/remark-lint) f
|
|||
If you want to see all the settings, open the
|
||||
[`remarkrc.js`](https://github.com/netdata/netdata/blob/master/.remarkrc.js) file in the `netdata/netdata` repository.
|
||||
|
||||
### Frontmatter
|
||||
|
||||
Every document must begin with frontmatter, followed by an H1 (`#`) heading.
|
||||
|
||||
Unlike typical Markdown frontmatter, Netdata uses HTML comments (`<!--`, `-->`) to begin and end the frontmatter block.
|
||||
These HTML comments are later converted into typical frontmatter syntax when building [Netdata
|
||||
Learn](https://learn.netdata.cloud).
|
||||
|
||||
Frontmatter _must_ contain the following variables:
|
||||
|
||||
- A `title` that quickly and distinctly describes the document's content.
|
||||
- A `description` that elaborates on the purpose or goal of the document using no less than 100 characters and no more
|
||||
than 155 characters.
|
||||
- A `custom_edit_url` that links directly to the GitHub URL where another user could suggest additional changes to the
|
||||
published document.
|
||||
|
||||
Some documents, like the Ansible guide and others in the `/docs/guides` folder, require an `image` variable as well. In
|
||||
this case, replace `/docs` with `/img/seo`, and then rebuild the remainder of the path to the document in question. End
|
||||
the path with `.png`. A member of the Netdata team will assist in creating the image when publishing the content.
|
||||
|
||||
For example, here is the frontmatter for the guide
|
||||
about [deploying the Netdata Agent with Ansible](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/ansible.md).
|
||||
|
||||
<img width="751" alt="image" src="https://user-images.githubusercontent.com/43294513/217607958-ef0f270d-7947-4d91-a9a5-56b17b4255ee.png"/>
|
||||
|
||||
Questions about frontmatter in
|
||||
documentation? [Ask on our community forum](https://community.netdata.cloud/c/blog-posts-and-articles/6).
|
||||
|
||||
### Linking between documentation
|
||||
|
||||
Documentation should link to relevant pages whenever it's relevant and provides valuable context to the reader.
|
||||
|
|
|
|||
|
|
@ -1,19 +1,6 @@
|
|||
<!--
|
||||
title: "Customize the standard dashboard"
|
||||
description: >-
|
||||
"Netdata's preconfigured dashboard offers many customization options, such as choosing when
|
||||
charts are updated, your preferred theme, and custom text to document processes, and more."
|
||||
type: "how-to"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/dashboard/customize.md"
|
||||
sidebar_label: "Customize the standard dashboard"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Operations"
|
||||
-->
|
||||
|
||||
# Customize the standard dashboard
|
||||
|
||||
While the [Netdata dashboard](https://github.com/netdata/netdata/blob/master/docs/dashboard/how-dashboard-works.md) comes preconfigured with hundreds of charts and
|
||||
While the [Netdata dashboard](https://github.com/netdata/netdata/blob/master/web/gui/README.md) comes preconfigured with hundreds of charts and
|
||||
thousands of metrics, you may want to alter your experience based on a particular use case or preferences.
|
||||
|
||||
## Dashboard settings
|
||||
|
|
|
|||
|
|
@ -67,12 +67,3 @@ names:
|
|||
| `disk.ops` | `disk_ops.sda` | `disk_ops.sdb` |
|
||||
| `disk.backlog` | `disk_backlog.sda` | `disk_backlog.sdb` |
|
||||
| `disk.util` | `disk_util.sda` | `disk_util.sdb` |
|
||||
|
||||
## What's next?
|
||||
|
||||
With an understanding of a chart's dimensions, context, and family, you're now ready to dig even deeper into Netdata's
|
||||
dashboard. We recommend looking into [using the timeframe selector](https://github.com/netdata/netdata/blob/master/docs/dashboard/visualization-date-and-time-controls.md).
|
||||
|
||||
If you feel comfortable with the [dashboard](https://github.com/netdata/netdata/blob/master/docs/dashboard/how-dashboard-works.md) and interacting with charts, we
|
||||
recommend learning about [configuration](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md). While Netdata doesn't _require_ a complicated setup
|
||||
process or a query language to create charts, there are a lot of ways to tweak the experience to match your needs.
|
||||
|
|
|
|||
|
|
@ -1,99 +0,0 @@
|
|||
<!--
|
||||
title: "How the dashboard works"
|
||||
description: >-
|
||||
"Learn how to navigate Netdata's preconfigured dashboard to get started
|
||||
exploring, visualizing, and troubleshooting in real time."
|
||||
type: "explanation"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/dashboard/how-dashboard-works.md"
|
||||
sidebar_label: "How the dashboard works"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Concepts"
|
||||
learn_rel_path: "Concepts"
|
||||
-->
|
||||
|
||||
# How the dashboard works
|
||||
|
||||
Because Netdata is a monitoring and _troubleshooting_ platform, a dashboard with real-time, meaningful, and
|
||||
context-aware charts is essential.
|
||||
|
||||
As soon as you [install Netdata](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md), it autodetects hardware, OS, containers, services, and
|
||||
applications running on your node and builds a dashboard on a single, scrollable webpage. This page features hundreds of
|
||||
charts, which are preconfigured to save you time from learning a query language, all stacked on top of one another. This
|
||||
vertical rhythm is designed to encourage exploration and help you visually identify connections between the metrics
|
||||
visualized in different charts.
|
||||
|
||||
It's essential to understand the core concepts and features of Netdata's dashboard if you want to maximize your Netdata
|
||||
experience right after installation.
|
||||
|
||||
## Open the dashboard
|
||||
|
||||
Access Netdata's dashboard by navigating to `http://NODE:19999` in your browser, replacing `NODE` with either
|
||||
`localhost` or the hostname/IP address of a remote node.
|
||||
|
||||

|
||||
|
||||
Many features of the internal web server that serves the dashboard are [configurable](https://github.com/netdata/netdata/blob/master/web/server/README.md), including
|
||||
the listen port, enforced TLS, and even disabling the dashboard altogether.
|
||||
|
||||
## Sections and menus
|
||||
|
||||
As mentioned in the introduction, Netdata automatically organizes all the metrics it collects from your node, and places
|
||||
them into **sections** of closely related charts.
|
||||
|
||||
The first section on any dashboard is the **System Overview**, followed by **CPUs**, **Memory**, and so on.
|
||||
|
||||
These sections populate the **menu**, which is on the right-hand side of the dashboard. Instead of manually scrolling up
|
||||
and down to explore the dashboard, it's generally faster to click on the relevant menu item to jump to that position on
|
||||
the dashboard.
|
||||
|
||||
Many menu items also contain a **submenu**, with links to additional categories. For example, the **Disks** section is often separated into multiple groups based on the number of disk drives/partitions on your node, which are also known as a family.
|
||||
|
||||
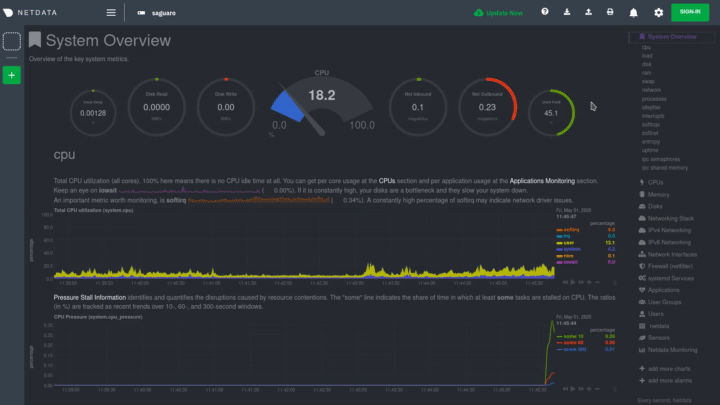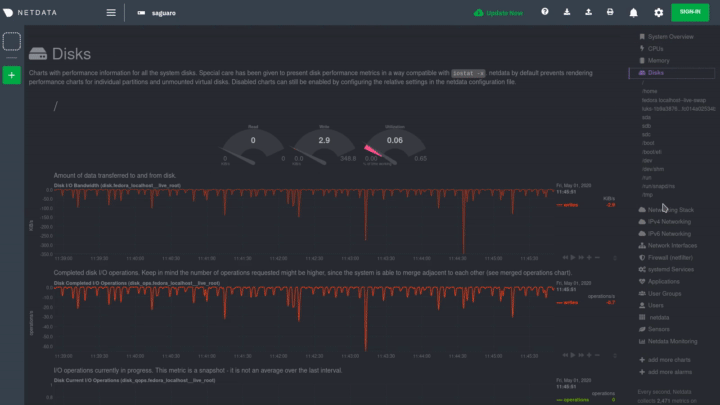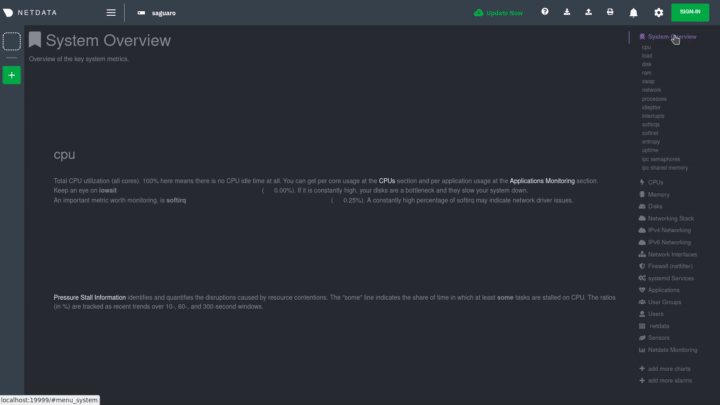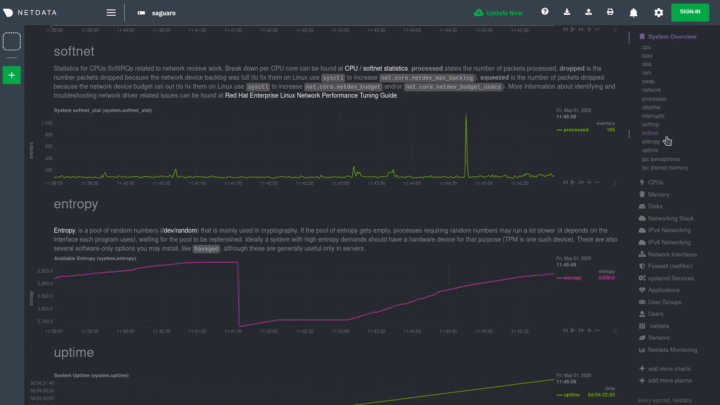
|
||||
|
||||
## Charts
|
||||
|
||||
Every **chart** in the Netdata dashboard is fully interactive. Netdata
|
||||
synchronizes your interactions to help you understand exactly how a node behaved in any timeframe, whether that's
|
||||
seconds or days.
|
||||
|
||||
A chart is an individual, interactive, always-updating graphic displaying one or more collected/calculated metrics,
|
||||
which are generated by [collectors](https://github.com/netdata/netdata/blob/master/collectors/README.md).
|
||||
|
||||
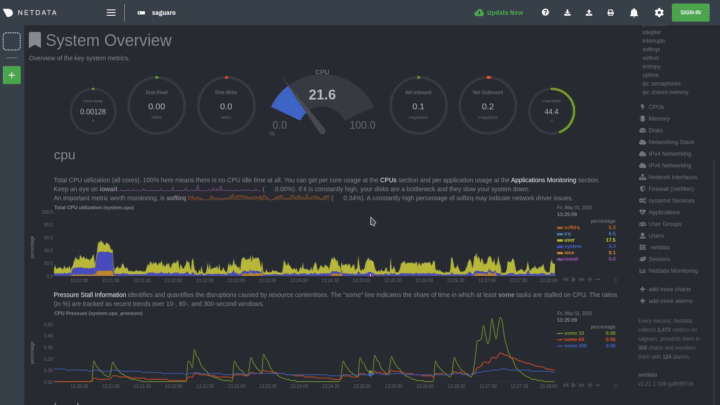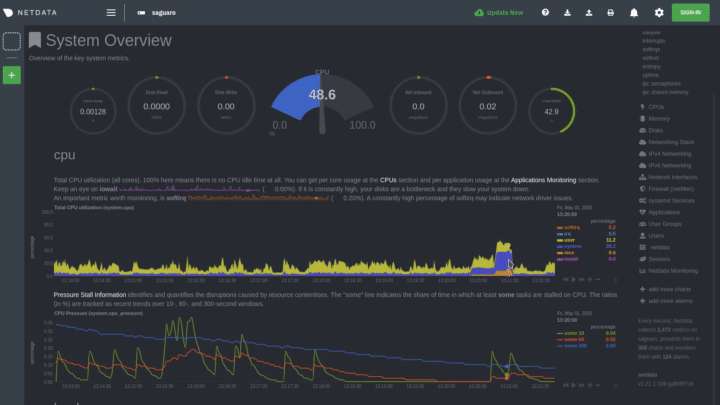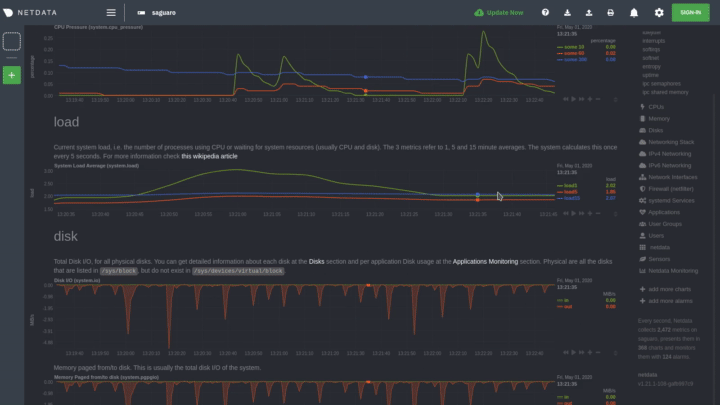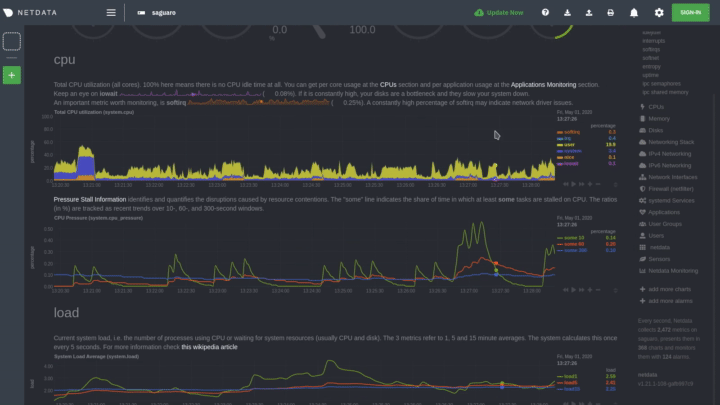
|
||||
|
||||
Hover over any chart to temporarily pause it and see the exact metrics values presented as different dimensions. Click
|
||||
or tap to stop the chart from automatically updating with new metrics, thereby locking it to a single timeframe.
|
||||
Double-click it to resume auto-updating.
|
||||
|
||||
Let's cover two of the most important ways to interact with charts: panning through time and zooming.
|
||||
|
||||
To pan through time, **click and hold** (or touch and hold) on any chart, then **drag your mouse** (or finger) to the
|
||||
left or right. Drag to the right to pan backward through time, or drag to the left to pan forward in time. Think of it
|
||||
like pushing the current timeframe off the screen to see what came before or after.
|
||||
|
||||
To zoom, press and hold `Shift`, then use your mouse's scroll wheel, or a two-finger pinch if you're using a touchpad.
|
||||
|
||||
See [interact with charts](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md) for all the possible ways to interact with the charts on
|
||||
your dashboard.
|
||||
|
||||
## Alarms
|
||||
|
||||
Many of the preconfigured charts on the Netdata dashboard also come with preconfigured alarms. Netdata sends three
|
||||
primary alarm states via alarms: `CLEAR`, `WARNING`, and `CRITICAL`. If an alarm moves from a `CLEAR` state to either
|
||||
`WARNING` or `CRITICAL`, Netdata creates a notification to let you know exactly what's going on. There are [other alarm
|
||||
states](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alarm-statuses) as well.
|
||||
|
||||
The easiest way to see alarms is by clicking on the alarm icon 
|
||||
in the top panel to open the alarms panel, which shows you all the active alarms. The other **All** tab shows every
|
||||
active alarm, and the **Log** tab shows a historical record of exactly when alarms triggered and to which state.
|
||||
|
||||
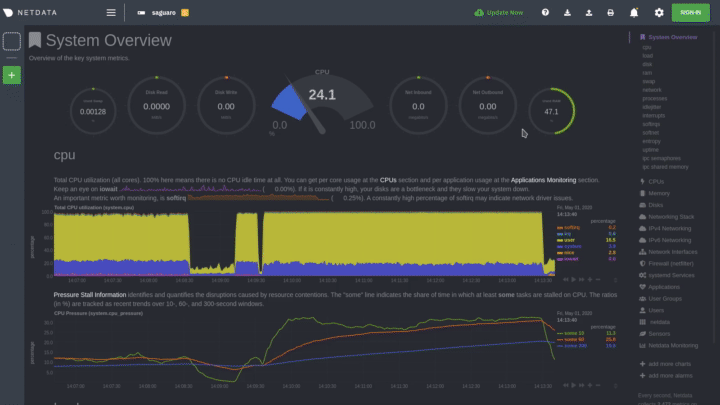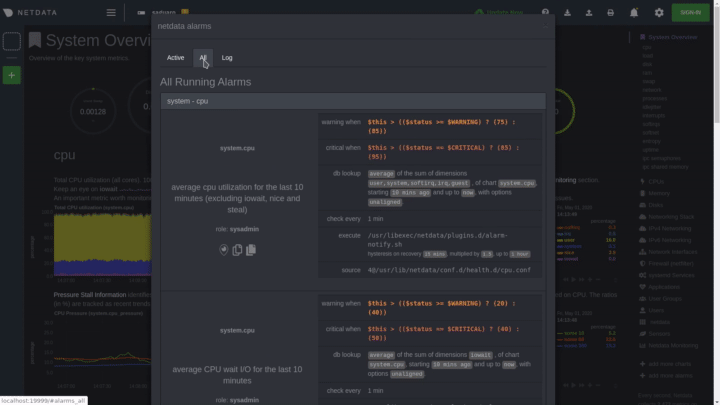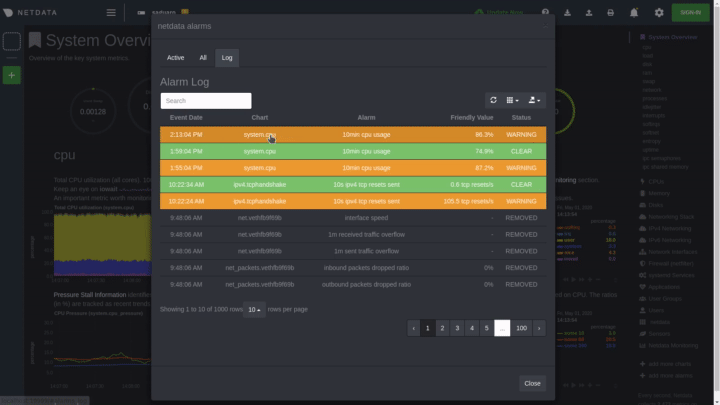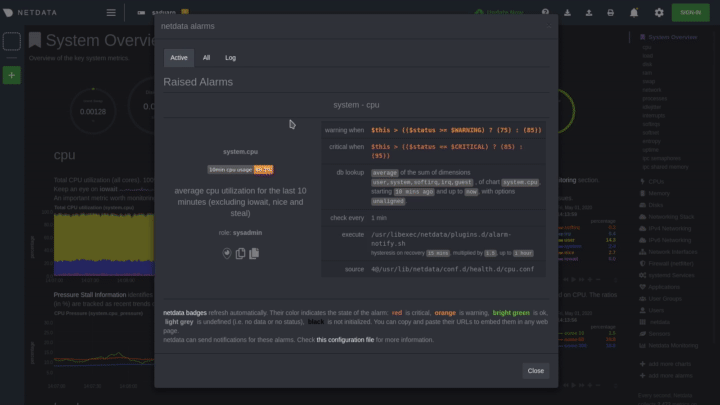
|
||||
|
||||
Learn more about [viewing active alarms](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alarms.md), [configuring
|
||||
alarms](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md), or [enabling a new notification
|
||||
method](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md).
|
||||
179
docs/glossary.md
Normal file
179
docs/glossary.md
Normal file
|
|
@ -0,0 +1,179 @@
|
|||
# Glossary
|
||||
|
||||
The Netdata community welcomes engineers, SREs, admins, etc. of all levels of expertise with engineering and the Netdata tool. And just as a journey of a thousand miles starts with one step, sometimes, the journey to mastery begins with understanding a single term.
|
||||
|
||||
As such, we want to provide a little Glossary as a reference starting point for new users who might be confused about the Netdata vernacular that more familiar users might take for granted.
|
||||
|
||||
If you're here looking for the definition of a term you heard elsewhere in our community or products, or if you just want to learn Netdata from the ground up, you've come to the right page.
|
||||
|
||||
Use the alphabatized list below to find the answer to your single-term questions, and click the bolded list items to explore more on the topics! We'll be sure to keep constantly updating this list, so if you hear a word that you would like for us to cover, just let us know or submit a request!
|
||||
|
||||
[A](#a) | [B](#b) | [C](#c) | [D](#d)| [E](#e) | [F](#f) | [G](#g) | [H](#h) | [I](#i) | [J](#j) | [K](#k) | [L](#l) | [M](#m) | [N](#n) | [O](#o) | [P](#p)
|
||||
| [Q](#q) | [R](#r) | [S](#s) | [T](#t) | [U](#u) | [V](#v) | [W](#w) | [X](#x) | [Y](#y) | [Z](#z)
|
||||
|
||||
## A
|
||||
|
||||
- [**Agent** or **Netdata Agent**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/overview.md): Netdata's distributed monitoring Agent collects thousands of metrics from systems, hardware, and applications with zero configuration. It runs permanently on all your physical/virtual servers, containers, cloud deployments, and edge/IoT devices.
|
||||
|
||||
- [**Agent-cloud link** or **ACLK**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/aclk.md): The Agent-Cloud link (ACLK) is the mechanism responsible for securely connecting a Netdata Agent to your web browser through Netdata Cloud.
|
||||
|
||||
- [**Aggregate Function**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-cloud/netdata-views.md#aggregate-functions-over-data-sources): A function applied When the granularity of the data collected is higher than the plotted points on the chart.
|
||||
|
||||
- [**Alerts** (formerly **Alarms**)](https://github.com/netdata/netdata/blob/master/docs/concepts/health-monitoring/alerts.md): With the information that appears on Netdata Cloud and the local dashboard about active alerts, you can configure alerts to match your infrastructure's needs or your team's goals.
|
||||
|
||||
- [**Alarm Entity Type**](https://github.com/netdata/netdata/blob/master/docs/concepts/health-monitoring/alerts.md#entity-types): Entity types that are attached to specific charts and use the `alarm` label.
|
||||
|
||||
- [**Anomaly Advisor**](https://github.com/netdata/netdata/blob/master/docs/concepts/guided-troubleshooting/machine-learning-powered-anomaly-advisor.md): A Netdata feature that lets you quickly surface potentially anomalous metrics and charts related to a particular highlight window of interest.
|
||||
|
||||
## B
|
||||
|
||||
- [**Bookmarks**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-cloud/rooms.md#bookmarks-for--essential-resources): Netdata Cloud's bookmarks put your tools in one accessible place. Bookmarks are shared between all War Rooms in a Space, so any users in your Space will be able to see and use them.
|
||||
|
||||
## C
|
||||
|
||||
- [**Child**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/metrics-streaming-replication.md#streaming-basics): A node, running Netdata, that streams metric data to one or more parent.
|
||||
|
||||
- [**Cloud** or **Netdata Cloud**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-cloud/overview.md): Netdata Cloud is a web application that gives you real-time visibility for your entire infrastructure. With Netdata Cloud, you can view key metrics, insightful charts, and active alarms from all your nodes in a single web interface.
|
||||
|
||||
- [**Collector**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/metrics-collection.md#collector-architecture-and-terminology): A catch-all term for any Netdata process that gathers metrics from an endpoint.
|
||||
|
||||
- [**Community**](https://github.com/netdata/netdata/blob/master/docs/getting-started/introduction.md#community): As a company with a passion and genesis in open-source, we are not just very proud of our community, but we consider our users, fans, and chatters to be an imperative part of the Netdata experience and culture.
|
||||
|
||||
- [**Composite Charts**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-cloud/netdata-views.md#composite-charts): Charts used by the **Overview** tab which aggregate metrics from all the nodes (or a filtered selection) in a given War Room.
|
||||
|
||||
- [**Context**](https://github.com/netdata/netdata/blob/master/docs/concepts/visualizations/from-raw-metrics-to-visualization.md#context): A way of grouping charts by the types of metrics collected and dimensions displayed. It's kind of like a machine-readable naming and organization scheme.
|
||||
|
||||
- [**Custom dashboards**](https://github.com/netdata/netdata/blob/master/docs/concepts/visualizations/dashboards.md#custom-dashboards) A dashboard that you can create using simple HTML (no javascript is required for basic dashboards).
|
||||
|
||||
## D
|
||||
|
||||
- [**Dashboards**](https://github.com/netdata/netdata/blob/master/docs/concepts/visualizations/dashboards.md): Out-of-the box visual presentation of metrics that allows you to make sense of your infrastructure and its health and performance.
|
||||
|
||||
- [**Definition Bar**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-cloud/netdata-views.md#composite-charts): Bar within a composite chart that provides important information and options about the metrics within the chart.
|
||||
|
||||
- [**Dimension** or **Group by**](https://github.com/netdata/netdata/blob/master/docs/concepts/visualizations/from-raw-metrics-to-visualization.md#dimension): A dimension is a value that gets shown on a chart. The drop-down on the dimension bar of a composite chart that allows you to group metrics by dimension, node, or chart.
|
||||
|
||||
- [**Distributed Architecture**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-architecture/distributed-data-architecture.md): The data architecture mindset with which Netdata was built, where all data are collected and stored on the edge, whenever it's possible, creating countless benefits.
|
||||
|
||||
## E
|
||||
|
||||
- [**External Plugins**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/metrics-collection.md#collector-architecture-and-terminology): These gather metrics from external processes, such as a webserver or database, and run as independent processes that communicate with the Netdata daemon via pipes.
|
||||
|
||||
## F
|
||||
|
||||
- [Family](https://github.com/netdata/netdata/blob/master/docs/concepts/visualizations/from-raw-metrics-to-visualization.md#family): 1. What we consider our Netdata community of users and engineers. 2. A single instance of a hardware or software resource that needs to be displayed separately from similar instances.
|
||||
|
||||
- [**Flood Protection**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-cloud/netdata-views.md#group-by-dimension-node-or-chart): If a node has too many state changes like firing too many alerts or going from reachable to unreachable, Netdata Cloud enables flood protection. As long as a node is in flood protection mode, Netdata Cloud does not send notifications about this node
|
||||
|
||||
- [**Functions** or **Netdata Functions**](https://github.com/netdata/netdata/blob/master/docs/concepts/guided-troubleshooting/netdata-functions.md): Routines exposed by a collector on the Netdata Agent that can bring additional information to support troubleshooting or trigger some action to happen on the node itself.
|
||||
|
||||
## G
|
||||
|
||||
- [**Guided Troubleshooting**](https://github.com/netdata/netdata/blob/master/docs/concepts/guided-troubleshooting/Overview.md): Troubleshooting with our Machine-Learning-powered tools designed to give you a cutting edge advantage in your troubleshooting battles.
|
||||
|
||||
- [**Group by** or **Dimension**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-cloud/netdata-views.md#group-by-dimension-node-or-chart): A dimension is a value that gets shown on a chart. The drop-down on the dimension bar of a composite chart that allows you to group metrics by dimension, node, or chart.
|
||||
|
||||
## H
|
||||
|
||||
- [**Headless Collector Streaming**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/metrics-streaming-replication.md): Streaming configuration where child `A`, _without_ a database or web dashboard, streams metrics to parent `B`.
|
||||
|
||||
- [**Health Configuration Files**](https://github.com/netdata/netdata/blob/master/docs/concepts/health-monitoring/alerts.md#health-configuration-files): Files that you can edit to configure your Agent's health watchdog service.
|
||||
|
||||
- [**Health Entity Reference**](https://github.com/netdata/netdata/blob/master/docs/concepts/health-monitoring/alerts.md#health-entity-reference):
|
||||
|
||||
- [**High Fidelity** or **High Fidelity Architecture**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-architecture/high-fidelity-monitoring.md): We consider Netdata's monitoring solution "high fidelity" because it provides real time metrics so you can view metrics/changes in seconds since their occur, the highest resolution of metrics to allow you to observe changes occur between seconds, gixed step metric collection to allow you to quantify your observation windows, and unlimited data to search for patterns in data that you don't even believe they are correlated.
|
||||
|
||||
- [**Home** tab](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-cloud/netdata-views.md#home): Tab in Netdata Cloud that provides a predefined dashboard of relevant information about entities in the War Room.
|
||||
|
||||
## I
|
||||
|
||||
- [**Internal plugins**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/metrics-collection.md#collector-architecture-and-terminology): These gather metrics from `/proc`, `/sys`, and other Linux kernel sources. They are written in `C` and run as threads within the Netdata daemon.
|
||||
|
||||
## K
|
||||
|
||||
- [**Kickstart** or **Kickstart Script**](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/kickstart.md): An automatic one-line installation script named 'kickstart.sh' that works on all Linux distributions and macOS.
|
||||
|
||||
- [**Kubernetes Dashboard** or **Kubernetes View**](https://github.com/netdata/netdata/blob/master/docs/concepts/visualizations/dashboards.md#kubernetes-dashboard): Netdata Cloud features enhanced visualizations for the resource utilization of Kubernetes (k8s) clusters, embedded in the default Overview dashboard.
|
||||
## M
|
||||
|
||||
- [**Metrics Collection**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/metrics-collection.md): With zero configuration, Netdata auto-detects thousands of data sources upon starting and immediately collects per-second metrics. Netdata can immediately collect metrics from these endpoints thanks to 300+ collectors, which all come pre-installed when you install Netdata.
|
||||
|
||||
- [**Metric Correlations**](https://github.com/netdata/netdata/blob/master/docs/concepts/guided-troubleshooting/metric-correlations.md): A Netdata feature that lets you quickly find metrics and charts related to a particular window of interest that you want to explore further.
|
||||
|
||||
- [**Metrics Exporting**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/metrics-exporting.md): Netdata allows you to export metrics to external time-series databases with the exporting engine. This system uses a number of connectors to initiate connections to more than thirty supported databases, including InfluxDB, Prometheus, Graphite, ElasticSearch, and much more.
|
||||
|
||||
- [**Metrics Storage**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/metrics-storage.md): Upon collection the collected metrics need to be either forwarded, exported or just stored for further treatment. The Agent is capable to store metrics both short and long-term, with or without the usage of non-volatile storage.
|
||||
|
||||
- [**Metrics Streaming Replication**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/metrics-streaming-replication.md): Each node running Netdata can stream the metrics it collects, in real time, to another node. Metric streaming allows you to replicate metrics data across multiple nodes, or centralize all your metrics data into a single time-series database (TSDB).
|
||||
|
||||
- [**Module**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/metrics-collection.md#collector-architecture-and-terminology): A type of collector.
|
||||
|
||||
## N
|
||||
|
||||
- [**Netdata**](https://github.com/netdata/netdata/blob/master/docs/getting-started/introduction.md): Netdata is a monitoring tool designed by system administrators, DevOps engineers, and developers to collect everything, help you visualize
|
||||
metrics, troubleshoot complex performance problems, and make data interoperable with the rest of your monitoring stack.
|
||||
|
||||
- [**Netdata Agent** or **Agent**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/overview.md): Netdata's distributed monitoring Agent collects thousands of metrics from systems, hardware, and applications with zero configuration. It runs permanently on all your physical/virtual servers, containers, cloud deployments, and edge/IoT devices.
|
||||
|
||||
- [**Netdata Cloud** or **Cloud**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/overview.md): Netdata Cloud is a web application that gives you real-time visibility for your entire infrastructure. With Netdata Cloud, you can view key metrics, insightful charts, and active alarms from all your nodes in a single web interface.
|
||||
|
||||
- [**Netdata Functions** or **Functions**](https://github.com/netdata/netdata/blob/master/docs/concepts/guided-troubleshooting/netdata-functions.md): Routines exposed by a collector on the Netdata Agent that can bring additional information to support troubleshooting or trigger some action to happen on the node itself.
|
||||
|
||||
<!-- No link for this keyword - [**Netdata Logs**](https://github.com/netdata/netdata/blob/master/docs/tasks/miscellaneous/check-netdata-logs.md): The three log files - `error.log`, `access.log` and `debug.log` - used by Netdata -->
|
||||
|
||||
- [**Notifications**](https://github.com/netdata/netdata/blob/master/docs/concepts/health-monitoring/notifications.md): Netdata can send centralized alert notifications to your team whenever a node enters a warning, critical, or unreachable state. By enabling notifications, you ensure no alert, on any node in your infrastructure, goes unnoticed by you or your team.
|
||||
|
||||
## O
|
||||
|
||||
- [**Obsoletion**(of nodes)](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-cloud/spaces.md#obsolete-offline-nodes): Removing nodes from a space.
|
||||
|
||||
- [**Orchestrators**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/metrics-collection.md#collector-architecture-and-terminology): External plugins that run and manage one or more modules. They run as independent processes.
|
||||
|
||||
- [**Overview** tab](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-cloud/netdata-views.md#overview): Tab in Netdata Cloud that uses composite charts. These charts display real-time aggregated metrics from all the nodes (or a filtered selection) in a given War Room.
|
||||
|
||||
## P
|
||||
|
||||
- [**Parent**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/metrics-streaming-replication.md#streaming-basics): A node, running Netdata, that receives streamed metric data.
|
||||
|
||||
- [**Proxy**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/metrics-streaming-replication.md#streaming-basics): A node, running Netdata, that receives metric data from a child and "forwards" them on to a separate parent node.
|
||||
|
||||
- [**Proxy Streaming**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/metrics-streaming-replication.md#supported-streaming-configurations): Streaming configuration where child `A`, _with or without_ a database, sends metrics to proxy `C`, also _with or without_ a database. `C` sends metrics to parent `B`
|
||||
|
||||
## R
|
||||
|
||||
- [**Registry**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/registry.md): Registry that allows Netdata to provide unified cross-server dashboards.
|
||||
|
||||
- [**Replication Streaming**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/metrics-streaming-replication.md): Streaming configuration where child `A`, _with_ a database and web dashboard, streams metrics to parent `B`.
|
||||
|
||||
- [**Room** or **War Room**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-cloud/rooms.md): War Rooms organize your connected nodes and provide infrastructure-wide dashboards using real-time metrics and visualizations.
|
||||
|
||||
## S
|
||||
|
||||
- [**Single Node Dashboard**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-cloud/netdata-views.md#jump-to-single-node-dashboards-1): A dashboard pre-configured with every installation of the Netdata agent, with thousand of metrics and hundreds of interactive charts that requires no set up.
|
||||
|
||||
<!-- No link for this file in current structure. - [**Snapshots**](https://github.com/netdata/netdata/blob/master/docs/tasks/miscellaneous/snapshot-data.md): An image of your dashboard at any given time, whicn can be imiported into any other node running Netdata or used to genereated a PDF file for your records. -->
|
||||
|
||||
- [**Space**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-cloud/spaces.md): A high-level container and virtual collaboration area where you can organize team members, access levels,and the nodes you want to monitor.
|
||||
|
||||
## T
|
||||
|
||||
- [**Template Entity Type**](https://github.com/netdata/netdata/blob/master/docs/concepts/health-monitoring/alerts.md#entity-types): Entity type that defines rules that apply to all charts of a specific context, and use the template label. Templates help you apply one entity to all disks, all network interfaces, all MySQL databases, and so on.
|
||||
|
||||
- [**Tiering**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-agent/metrics-storage.md#tiering): Tiering is a mechanism of providing multiple tiers of data with different granularity of metrics (the frequency they are collected and stored, i.e. their resolution).
|
||||
|
||||
## U
|
||||
|
||||
- [**Unlimited Scalability**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-architecture/unlimited-scalability.md): With Netdata's distributed architecture, you can seamless observe a couple, hundreds or
|
||||
even thousands of nodes. There are no actual bottlenecks especially if you retain metrics locally in the Agents.
|
||||
|
||||
## V
|
||||
|
||||
- [**Visualizations**](https://github.com/netdata/netdata/blob/master/docs/concepts/visualizations/from-raw-metrics-to-visualization.md): Netdata uses dimensions, contexts, and families to sort your metric data into graphs, charts, and alerts that maximize your understand of your infrastructure and your ability to troubleshoot it, along or on a team.
|
||||
|
||||
## W
|
||||
|
||||
- [**War Room** or **Room**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-cloud/rooms.md): War Rooms organize your connected nodes and provide infrastructure-wide dashboards using real-time metrics and visualizations.
|
||||
|
||||
## Z
|
||||
|
||||
- [**Zero Configuration**](https://github.com/netdata/netdata/blob/master/docs/concepts/netdata-architecture/zero-configuration.md): Netdata is preconfigured and capable to autodetect and monitor any well known application that runs on your system. You just deploy and claim Netdata Agents in your Netdata space, and monitor them in seconds.
|
||||
|
|
@ -1,12 +1,4 @@
|
|||
<!--
|
||||
title: "Contribute to the documentation"
|
||||
sidebar_label: "Contribute to the documentation"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/guidelines.md"
|
||||
sidebar_position: "10"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Custom"
|
||||
learn_rel_path: "Contribute"
|
||||
-->
|
||||
# Contribute to the documentation
|
||||
|
||||
import Tabs from '@theme/Tabs'; import TabItem from '@theme/TabItem';
|
||||
|
||||
|
|
@ -17,750 +9,59 @@ docs (**learn.netdata.cloud**)
|
|||
|
||||
## Documentation architecture
|
||||
|
||||
Netdata docs follows has two principals.
|
||||
Our documentation in https://learn.netdata.cloud is generated by markdown documents in the public
|
||||
Github repositories of the "netdata" organization.
|
||||
|
||||
1. Keep the documentation of each component _as close as you can to the codebase_
|
||||
2. Every component is analyzed via topic related docs.
|
||||
|
||||
To this end:
|
||||
|
||||
1. Documentation lives in every possible repo in the netdata organization. At the moment we contribute to:
|
||||
- netdata/netdata
|
||||
- netdata/learn (final site)
|
||||
- netdata/go.d.plugin
|
||||
- netdata/agent-service-discovery
|
||||
|
||||
In each of these repos you will find markdown files. These markdown files may or not be part of the final docs. You
|
||||
understand what documents are part of the final docs in the following section:[_How to update documentation of
|
||||
learn.netdata.cloud_](#how-to-update-documentation-of-learn-netdata-cloud)
|
||||
|
||||
2. Netdata docs processes are inspired from
|
||||
the [DITA 1.2 guidelines](http://docs.oasis-open.org/dita/v1.2/os/spec/archSpec/dita-1.2_technicalContent_overview.html)
|
||||
for Technical content.
|
||||
|
||||
## Topic types
|
||||
|
||||
### Concepts
|
||||
|
||||
A concept introduces a single feature or concept. A concept should answer the questions:
|
||||
|
||||
- What is this?
|
||||
- Why would I use it?
|
||||
|
||||
Concept topics:
|
||||
|
||||
- Are abstract ideas
|
||||
- Explain meaning or benefit
|
||||
- Can stay when specifications change
|
||||
- Provide background information
|
||||
|
||||
### Tasks
|
||||
|
||||
Concept and reference topics exist to support tasks. _The goal for users … is not to understand a concept but to
|
||||
complete a task_. A task gives instructions for how to complete a procedure.
|
||||
|
||||
Much of the uncertainty whether a topic is a concept or a reference disappears, when you have strong, solid task topics
|
||||
in place, furthermore topics directly address your users and their daily tasks and help them to get their job done. A
|
||||
task **must give an answer** to the **following questions**:
|
||||
|
||||
- How do I create cool espresso drinks with my new coffee machine?
|
||||
- How do I clean the milk steamer?
|
||||
|
||||
For the title text, use the structure active verb + noun. For example, for instance _Deploy the Agent_.
|
||||
|
||||
### References
|
||||
|
||||
The reference document and information types provide for the separation of fact-based information from concepts and
|
||||
tasks. \
|
||||
Factual information may include tables and lists of specifications, parameters, parts, commands, edit-files and other
|
||||
information that the users are likely to look up. The reference information type allows fact-based content to be
|
||||
maintained by those responsible for its accuracy and consistency.
|
||||
|
||||
## Contribute to the documentation of learn.netdata.cloud
|
||||
|
||||
### Encapsulate topics into markdown files.
|
||||
|
||||
Netdata uses markdown files to document everything. To implement concrete sections of these [Topic types](#topic-types)
|
||||
we encapsulate this logic as follows. Every document is characterized by its topic type ('learn_topic_type' metadata
|
||||
field). To avoid breaking every single netdata concept into numerous small markdown files each document can be either a
|
||||
single `Reference` or `Concept` or `Task` or a group of `References`, `Concepts`, `Tasks`.
|
||||
|
||||
To this end, every single topic is encapsulated into a `Heading 3 (###)` section. That means, when you have a single
|
||||
file you only make use of `Headings 4` and lower (`4, 5, 6`, for templated section or subsection). In case you want to
|
||||
includ multiple (`Concepts` let's say) in a single document, you use `Headings 3` to seperate each concept. `Headings 2`
|
||||
are used only in case you want to logically group topics inside a document.
|
||||
|
||||
For instance:
|
||||
|
||||
```markdown
|
||||
|
||||
Small introduction of the document.
|
||||
|
||||
### Concept A
|
||||
|
||||
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna
|
||||
aliqua.
|
||||
|
||||
#### Field from template 1
|
||||
|
||||
Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
|
||||
|
||||
#### Field from template 1
|
||||
|
||||
Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
|
||||
|
||||
##### Subsection 1
|
||||
|
||||
. . .
|
||||
|
||||
### Concept A
|
||||
|
||||
Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
|
||||
|
||||
#### Field from template 1
|
||||
|
||||
. . .
|
||||
|
||||
|
||||
```
|
||||
|
||||
This approach gives a clean and readable outlook in each document from a single sidebar.
|
||||
|
||||
Here you can find the preferred templates for each topic type:
|
||||
|
||||
|
||||
<Tabs>
|
||||
<TabItem value="Concept" label="Concept" default>
|
||||
|
||||
```markdown
|
||||
Small intro, give some context to the user of what you will cover on this document
|
||||
|
||||
### concept title (omit if the document describes only one concept)
|
||||
|
||||
A concept introduces a single feature or concept. A concept should answer the questions:
|
||||
|
||||
1. What is this?
|
||||
2. Why would I use it?
|
||||
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="Task" label="Tasks">
|
||||
|
||||
```markdown
|
||||
Small intro, give some context to the user of what you will cover on this document
|
||||
|
||||
### Task title (omit if the document describes only one task)
|
||||
|
||||
#### Prerequisite
|
||||
|
||||
Unordered list of what you will need.
|
||||
|
||||
#### Steps
|
||||
|
||||
Exact list of step the user must follow
|
||||
|
||||
#### Expected result
|
||||
|
||||
What you expect to see when you complete the steps above
|
||||
|
||||
#### Example
|
||||
|
||||
Example configuration/actions of the task
|
||||
|
||||
#### Related reference documentation
|
||||
|
||||
List of reference docs user needs to be aware of.
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="Reference-collectors" label="Reference-collectors">
|
||||
|
||||
```markdown
|
||||
Small intro, give some context to the user of what you will cover on this document
|
||||
|
||||
### Reference name (omit if the document describes only one reference)
|
||||
|
||||
#### Requirements
|
||||
|
||||
Document any dependencies needed to run this module
|
||||
|
||||
#### Requirements on the monitored component
|
||||
|
||||
Document any steps user must take to sucessful monitor application,
|
||||
for instance (create a user)
|
||||
|
||||
#### Configuration files
|
||||
|
||||
table with path and configuration files purpose
|
||||
Columns: File name | Description (Purpose in a nutshell)
|
||||
|
||||
#### Data collection
|
||||
|
||||
To make changes, see `the ./edit-config task <link>`
|
||||
|
||||
#### Auto discovery
|
||||
|
||||
##### Single node installation
|
||||
|
||||
. . . we autodetect localhost:port and what configurations are defaults
|
||||
|
||||
##### Kubernetes installations
|
||||
|
||||
. . . Service discovery, click here
|
||||
|
||||
#### Metrics
|
||||
|
||||
Columns: Metric (Context) | Scope | description (of the context) | dimensions | units (of the context) | Alert triggered
|
||||
|
||||
|
||||
#### Alerts
|
||||
|
||||
Collapsible content for every alert, just like the alert guides
|
||||
|
||||
#### Configuration options
|
||||
|
||||
Table with all the configuration options available.
|
||||
|
||||
Columns: name | description | default | file_name
|
||||
|
||||
#### Configuration example
|
||||
|
||||
Default configuration example
|
||||
|
||||
#### Troubleshoot
|
||||
|
||||
backlink to the task to run this module in debug mode (here you provide the debug flags)
|
||||
|
||||
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
### Metadata fields
|
||||
|
||||
All Docs that are supposed to be part of learn.netdata.cloud have **hidden** sections in the begining of document. These
|
||||
sections are plain lines of text and we call them metadata. Their represented as `key : "Value"` pairs. Some of them are
|
||||
needed from our statice website builder (docusaurus) others are needed for our internal pipelines to build docs
|
||||
(have prefix `learn_`).
|
||||
|
||||
So let's go through the different necessary metadata tags to get a document properly published on Learn:
|
||||
|
||||
| metadata_key | Value(s) | Frontmatter effect | Mandatory | Limitations |
|
||||
|:---------------------:|---------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------------------------------------:|:---------:|:---------------------------------------:|
|
||||
| `title` | `String` | Title in each document | yes | |
|
||||
| `custom_edit_url` | `String` | The source GH link of the file | yes | |
|
||||
| `description` | `String or multiline String` | - | yes | |
|
||||
| `sidebar_label` | `String or multiline String` | Name in the TOC tree | yes | |
|
||||
| `sidebar_position` | `String or multiline String` | Global position in the TOC tree (local for per folder) | yes | |
|
||||
| `learn_status` | [`Published`, `Unpublished`, `Hidden`] | `Published`: Document visible in learn,<br/> `Unpublished`: Document archived in learn, <br/>`Hidden`: Documentplaced under learn_rel_path but it's hidden] | yes | |
|
||||
| `learn_topic_type` | [`Concepts`, `Tasks`, `References`, `Getting Started`] | | yes | |
|
||||
| `learn_rel_path` | `Path` (the path you want this file to appear in learn<br/> without the /docs prefix and the name of the file | | yes | |
|
||||
| `learn_autogenerated` | `Dictionary` (for internal use) | | no | Keys in the dictionary must be in `' '` |
|
||||
|
||||
:::important
|
||||
|
||||
1. In case any mandatory tags are missing or falsely inputted the file will remain unpublished. This is by design to
|
||||
prevent non-properly tagged files from getting published.
|
||||
2. All metadata values must be included in `" "`. From `string` noted text inside the fields use `' ''`
|
||||
|
||||
|
||||
While Docusaurus can make use of more metadata tags than the above, these are the minimum we require to publish the file
|
||||
on Learn.
|
||||
|
||||
:::
|
||||
|
||||
### Placing a document in learn
|
||||
|
||||
Here you can see how the metadata are parsed and create a markdown file in learn.
|
||||
|
||||

|
||||
|
||||
### Before you get started
|
||||
|
||||
Anyone interested in contributing to documentation should first read the [Netdata style guide](#styling-guide) further
|
||||
down below and the [Netdata Community Code of Conduct](https://github.com/netdata/.github/blob/main/CODE_OF_CONDUCT.md).
|
||||
|
||||
Netdata's documentation uses Markdown syntax. If you're not familiar with Markdown, read
|
||||
the [Mastering Markdown](https://guides.github.com/features/mastering-markdown/) guide from GitHub for the basics on
|
||||
creating paragraphs, styled text, lists, tables, and more, and read further down about some special
|
||||
occasions [while writing in MDX](#mdx-and-markdown).
|
||||
|
||||
### Making your first contribution
|
||||
### Improve existing documentation
|
||||
|
||||
The easiest way to contribute to Netdata's documentation is to edit a file directly on GitHub. This is perfect for small
|
||||
fixes to a single document, such as fixing a typo or clarifying a confusing sentence.
|
||||
|
||||
Click on the **Edit this page** button on any published document on [Netdata Learn](https://learn.netdata.cloud). Each
|
||||
page has two of these buttons: One beneath the table of contents, and another at the end of the document, which take you
|
||||
to GitHub's code editor. Make your suggested changes, keeping the [Netdata style guide](#styling-guide)
|
||||
in mind, and use the ***Preview changes*** button to ensure your Markdown syntax works as expected.
|
||||
Each published document on [Netdata Learn](https://learn.netdata.cloud) includes at the bottom a link to
|
||||
**Edit this page**. Clicking on that link is the recommended way to improve our documentation, as it
|
||||
leads you directly to GitHub's code editor.
|
||||
Make your suggested changes, and use the ***Preview changes*** button to ensure your Markdown syntax works as expected.
|
||||
|
||||
Under the **Commit changes** header, write descriptive title for your requested change. Click the **Commit changes**
|
||||
button to initiate your pull request (PR).
|
||||
|
||||
Jump down to our instructions on [PRs](#making-a-pull-request) for your next steps.
|
||||
|
||||
**Note**: If you wish to contribute documentation that is more tailored from your specific infrastructure
|
||||
monitoring/troubleshooting experience, please consider submitting a blog post about your experience. Check out our [blog](https://github.com/netdata/blog#readme) repo! Any blog submissions that have
|
||||
### Create a new document
|
||||
|
||||
You can create a pull request to add a completely new markdown document in any of our public repositories.
|
||||
After the Github pull request is merged, our documentation team will decide where in the documentation hierarchy to publish
|
||||
that document.
|
||||
|
||||
If you wish to contribute documentation that is tailored to your specific infrastructure
|
||||
monitoring/troubleshooting experience, please consider submitting a blog post about your experience.
|
||||
Check out our [blog](https://github.com/netdata/blog#readme) repo! Any blog submissions that have
|
||||
widespread or universal application will be integrated into our permanent documentation.
|
||||
|
||||
### Edit locally
|
||||
#### Before you get started
|
||||
|
||||
Editing documentation locally is the preferred method for complex changes that span multiple documents or change the
|
||||
documentation's style or structure.
|
||||
Anyone interested in contributing significantly to documentation should first read the
|
||||
[Netdata style guide](https://github.com/netdata/netdata/blob/master/docs/contributing/style-guide.md)
|
||||
and the [Netdata Community Code of Conduct](https://github.com/netdata/.github/blob/main/CODE_OF_CONDUCT.md).
|
||||
|
||||
Create a fork of the Netdata Agent repository by visit the [Netdata repository](https://github.com/netdata/netdata) and
|
||||
clicking on the **Fork** button.
|
||||
Netdata's documentation uses Markdown syntax. If you're not familiar with Markdown, read
|
||||
the [Mastering Markdown](https://guides.github.com/features/mastering-markdown/) guide from GitHub for the basics on
|
||||
creating paragraphs, styled text, lists, tables, and more.
|
||||
|
||||
GitHub will ask you where you want to clone the repository. When finished, you end up at the index of your forked
|
||||
Netdata Agent repository. Clone your fork to your local machine:
|
||||
#### Edit locally
|
||||
|
||||
```bash
|
||||
git clone https://github.com/YOUR-GITHUB-USERNAME/netdata.git
|
||||
```
|
||||
|
||||
Create a new branch using `git checkout -b BRANCH-NAME`. Use your favorite text editor to make your changes, keeping
|
||||
the [Netdata style guide](https://github.com/netdata/netdata/blob/master/docs/contributing/style-guide.md) in mind. Add, commit, and push changes to your fork. When you're
|
||||
finished, visit the [Netdata Agent Pull requests](https://github.com/netdata/netdata/pulls) to create a new pull request
|
||||
based on the changes you made in the new branch of your fork.
|
||||
Editing documentation locally is the preferred method for completely new documents, or complex changes that span multiple
|
||||
documents. Clone the repository where you wish to make your changes, work on a new branch and create a pull request
|
||||
with that branch.
|
||||
|
||||
### Making a pull request
|
||||
|
||||
Pull requests (PRs) should be concise and informative. See our [PR guidelines](/contribute/handbook#pr-guidelines) for
|
||||
Pull requests (PRs) should be concise and informative. See our
|
||||
[PR guidelines](https://github.com/netdata/.github/blob/main/CONTRIBUTING.md#pr-guidelines) for
|
||||
specifics.
|
||||
|
||||
- The title must follow the [imperative mood](https://en.wikipedia.org/wiki/Imperative_mood) and be no more than ~50
|
||||
characters.
|
||||
- The description should explain what was changed and why. Verify that you tested any code or processes that you are
|
||||
trying to change.
|
||||
|
||||
The Netdata team will review your PR and assesses it for correctness, conciseness, and overall quality. We may point to
|
||||
specific sections and ask for additional information or other fixes.
|
||||
|
||||
After merging your PR, the Netdata team rebuilds the [documentation site](https://learn.netdata.cloud) to publish the
|
||||
changed documentation.
|
||||
|
||||
## Styling guide
|
||||
|
||||
The *Netdata style guide* establishes editorial guidelines for any writing produced by the Netdata team or the Netdata
|
||||
community, including documentation, articles, in-product UX copy, and more. Both internal Netdata teams and external
|
||||
contributors to any of Netdata's open-source projects should reference and adhere to this style guide as much as
|
||||
possible.
|
||||
|
||||
Netdata's writing should **empower** and **educate**. You want to help people understand Netdata's value, encourage them
|
||||
to learn more, and ultimately use Netdata's products to democratize monitoring in their organizations. To achieve these
|
||||
goals, your writing should be:
|
||||
|
||||
- **Clear**. Use simple words and sentences. Use strong, direct, and active language that encourages readers to action.
|
||||
- **Concise**. Provide solutions and answers as quickly as possible. Give users the information they need right now,
|
||||
along with opportunities to learn more.
|
||||
- **Universal**. Think of yourself as a guide giving a tour of Netdata's products, features, and capabilities to a
|
||||
diverse group of users. Write to reach the widest possible audience.
|
||||
|
||||
You can achieve these goals by reading and adhering to the principles outlined below.
|
||||
|
||||
If you're not familiar with Markdown, read
|
||||
the [Mastering Markdown](https://guides.github.com/features/mastering-markdown/) guide from GitHub for the basics on
|
||||
creating paragraphs, styled text, lists, tables, and more.
|
||||
|
||||
The following sections describe situations in which a specific syntax is required.
|
||||
|
||||
#### Syntax standards (`remark-lint`)
|
||||
|
||||
The Netdata team uses [`remark-lint`](https://github.com/remarkjs/remark-lint) for Markdown code styling.
|
||||
|
||||
- Use a maximum of 120 characters per line.
|
||||
- Begin headings with hashes, such as `# H1 heading`, `## H2 heading`, and so on.
|
||||
- Use `_` for italics/emphasis.
|
||||
- Use `**` for bold.
|
||||
- Use dashes `-` to begin an unordered list, and put a single space after the dash.
|
||||
- Tables should be padded so that pipes line up vertically with added whitespace.
|
||||
|
||||
If you want to see all the settings, open the
|
||||
[`remarkrc.js`](https://github.com/netdata/netdata/blob/master/.remarkrc.js) file in the `netdata/netdata` repository.
|
||||
|
||||
#### MDX and markdown
|
||||
|
||||
While writing in Docusaurus, you might want to take leverage of it's features that are supported in MDX formatted files.
|
||||
One of those that we use is [Tabs](https://docusaurus.io/docs/next/markdown-features/tabs). They use an HTML syntax,
|
||||
which requires some changes in the way we write markdown inside them.
|
||||
|
||||
In detail:
|
||||
|
||||
Due to a bug with docusaurus, we prefer to use `<h1>heading</h1> instead of # H1` so that docusaurus doesn't render the
|
||||
contents of all Tabs on the right hand side, while not being able to navigate
|
||||
them [relative link](https://github.com/facebook/docusaurus/issues/7008).
|
||||
|
||||
You can use markdown syntax for every other styling you want to do except Admonitions:
|
||||
For admonitions, follow [this](https://docusaurus.io/docs/markdown-features/admonitions#usage-in-jsx) guide to use
|
||||
admonitions inside JSX. While writing in JSX, all the markdown stylings have to be in HTML format to be rendered
|
||||
properly.
|
||||
|
||||
#### Admonitions
|
||||
|
||||
Use admonitions cautiously. Admonitions may draw user's attention, to that end we advise you to use them only for side
|
||||
content/info, without significantly interrupting the document flow.
|
||||
|
||||
You can find the supported admonitions in the docusaurus's [documentation](https://docusaurus.io/docs/markdown-features/admonitions).
|
||||
|
||||
#### Images
|
||||
|
||||
Don't rely on images to convey features, ideas, or instructions. Accompany every image with descriptive alt text.
|
||||
|
||||
In Markdown, use the standard image syntax, ``, and place the alt text between the
|
||||
brackets `[]`. Here's an example using our logo:
|
||||
|
||||
```markdown
|
||||

|
||||
```
|
||||
|
||||
Reference in-product text, code samples, and terminal output with actual text content, not screen captures or other
|
||||
images. Place the text in an appropriate element, such as a blockquote or code block, so all users can parse the
|
||||
information.
|
||||
|
||||
#### Syntax highlighting
|
||||
|
||||
Our documentation site at [learn.netdata.cloud](https://learn.netdata.cloud) uses
|
||||
[Prism](https://v2.docusaurus.io/docs/markdown-features#syntax-highlighting) for syntax highlighting. Netdata can use
|
||||
any of
|
||||
the [supported languages by prism-react-renderer](https://github.com/FormidableLabs/prism-react-renderer/blob/master/src/vendor/prism/includeLangs.js)
|
||||
.
|
||||
|
||||
If no language is specified, Prism tries to guess the language based on its content.
|
||||
|
||||
Include the language directly after the three backticks (```` ``` ````) that start the code block. For highlighting C
|
||||
code, for example:
|
||||
|
||||
````c
|
||||
```c
|
||||
inline char *health_stock_config_dir(void) {
|
||||
char buffer[FILENAME_MAX + 1];
|
||||
snprintfz(buffer, FILENAME_MAX, "%s/health.d", netdata_configured_stock_config_dir);
|
||||
return config_get(CONFIG_SECTION_DIRECTORIES, "stock health config", buffer);
|
||||
}
|
||||
```
|
||||
````
|
||||
|
||||
And the prettified result:
|
||||
|
||||
```c
|
||||
inline char *health_stock_config_dir(void) {
|
||||
char buffer[FILENAME_MAX + 1];
|
||||
snprintfz(buffer, FILENAME_MAX, "%s/health.d", netdata_configured_stock_config_dir);
|
||||
return config_get(CONFIG_SECTION_DIRECTORIES, "stock health config", buffer);
|
||||
}
|
||||
```
|
||||
|
||||
Prism also supports titles and line highlighting. See
|
||||
the [Docusaurus documentation](https://v2.docusaurus.io/docs/markdown-features#code-blocks) for more information.
|
||||
|
||||
## Language, grammar, and mechanics
|
||||
|
||||
#### Voice and tone
|
||||
|
||||
One way we write empowering, educational content is by using a consistent voice and an appropriate tone.
|
||||
|
||||
*Voice* is like your personality, which doesn't really change day to day.
|
||||
|
||||
*Tone* is how you express your personality. Your expression changes based on your attitude or mood, or based on who
|
||||
you're around. In writing, your reflect tone in your word choice, punctuation, sentence structure, or even the use of
|
||||
emoji.
|
||||
|
||||
The same idea about voice and tone applies to organizations, too. Our voice shouldn't change much between two pieces of
|
||||
content, no matter who wrote each, but the tone might be quite different based on who we think is reading.
|
||||
|
||||
For example, a [blog post](https://www.netdata.cloud/blog/) and a [press release](https://www.netdata.cloud/news/)
|
||||
should have a similar voice, despite most often being written by different people. However, blog posts are relaxed and
|
||||
witty, while press releases are focused and academic. You won't see any emoji in a press release.
|
||||
|
||||
##### Voice
|
||||
|
||||
Netdata's voice is authentic, passionate, playful, and respectful.
|
||||
|
||||
- **Authentic** writing is honest and fact-driven. Focus on Netdata's strength while accurately communicating what
|
||||
Netdata can and cannot do, and emphasize technical accuracy over hard sells and marketing jargon.
|
||||
- **Passionate** writing is strong and direct. Be a champion for the product or feature you're writing about, and let
|
||||
your unique personality and writing style shine.
|
||||
- **Playful** writing is friendly, thoughtful, and engaging. Don't take yourself too seriously, as long as it's not at
|
||||
the expense of Netdata or any of its users.
|
||||
- **Respectful** writing treats people the way you want to be treated. Prioritize giving solutions and answers as
|
||||
quickly as possible.
|
||||
|
||||
##### Tone
|
||||
|
||||
Netdata's tone is fun and playful, but clarity and conciseness comes first. We also tend to be informal, and aren't
|
||||
afraid of a playful joke or two.
|
||||
|
||||
While we have general standards for voice and tone, we do want every individual's unique writing style to reflect in
|
||||
published content.
|
||||
|
||||
#### Universal communication
|
||||
|
||||
Netdata is a global company in every sense, with employees, contributors, and users from around the world. We strive to
|
||||
communicate in a way that is clear and easily understood by everyone.
|
||||
|
||||
Here are some guidelines, pointers, and questions to be aware of as you write to ensure your writing is universal. Some
|
||||
of these are expanded into individual sections in
|
||||
the [language, grammar, and mechanics](#language-grammar-and-mechanics) section below.
|
||||
|
||||
- Would this language make sense to someone who doesn't work here?
|
||||
- Could someone quickly scan this document and understand the material?
|
||||
- Create an information hierarchy with key information presented first and clearly called out to improve scannability.
|
||||
- Avoid directional language like "sidebar on the right of the page" or "header at the top of the page" since
|
||||
presentation elements may adapt for devices.
|
||||
- Use descriptive links rather than "click here" or "learn more".
|
||||
- Include alt text for images and image links.
|
||||
- Ensure any information contained within a graphic element is also available as plain text.
|
||||
- Avoid idioms that may not be familiar to the user or that may not make sense when translated.
|
||||
- Avoid local, cultural, or historical references that may be unfamiliar to users.
|
||||
- Prioritize active, direct language.
|
||||
- Avoid referring to someone's age unless it is directly relevant; likewise, avoid referring to people with age-related
|
||||
descriptors like "young" or "elderly."
|
||||
- Avoid disability-related idioms like "lame" or "falling on deaf ears." Don't refer to a person's disability unless
|
||||
it’s directly relevant to what you're writing.
|
||||
- Don't call groups of people "guys." Don't call women "girls."
|
||||
- Avoid gendered terms in favor of neutral alternatives, like "server" instead of "waitress" and "businessperson"
|
||||
instead of "businessman."
|
||||
- When writing about a person, use their communicated pronouns. When in doubt, just ask or use their name. It's OK to
|
||||
use "they" as a singular pronoun.
|
||||
|
||||
> Some of these guidelines were adapted from MailChimp under the Creative Commons license.
|
||||
|
||||
To ensure Netdata's writing is clear, concise, and universal, we have established standards for language, grammar, and
|
||||
certain writing mechanics. However, if you're writing about Netdata for an external publication, such as a guest blog
|
||||
post, follow that publication's style guide or standards, while keeping
|
||||
the [preferred spelling of Netdata terms](#netdata-specific-terms) in mind.
|
||||
|
||||
#### Active voice
|
||||
|
||||
Active voice is more concise and easier to understand compared to passive voice. When using active voice, the subject of
|
||||
the sentence is action. In passive voice, the subject is acted upon. A famous example of passive voice is the phrase
|
||||
"mistakes were made."
|
||||
|
||||
| | |
|
||||
| --------------- | ----------------------------------------------------------------------------------------- |
|
||||
| Not recommended | When an alarm is triggered by a metric, a notification is sent by Netdata. |
|
||||
| **Recommended** | When a metric triggers an alarm, Netdata sends a notification to your preferred endpoint. |
|
||||
|
||||
#### Second person
|
||||
|
||||
Use the second person ("you") to give instructions or "talk" directly to users.
|
||||
|
||||
In these situations, avoid "we," "I," "let's," and "us," particularly in documentation. The "you" pronoun can also be
|
||||
implied, depending on your sentence structure.
|
||||
|
||||
One valid exception is when a member of the Netdata team or community wants to write about said team or community.
|
||||
|
||||
| | |
|
||||
| ------------------------------ | ------------------------------------------------------------ |
|
||||
| Not recommended | To install Netdata, we should try the one-line installer... |
|
||||
| **Recommended** | To install Netdata, you should try the one-line installer... |
|
||||
| **Recommended**, implied "you" | To install Netdata, try the one-line installer... |
|
||||
|
||||
#### "Easy" or "simple"
|
||||
|
||||
Using words that imply the complexity of a task or feature goes against our policy
|
||||
of [universal communication](#universal-communication). If you claim that a task is easy and the reader struggles to
|
||||
complete it, you may inadvertently discourage them.
|
||||
|
||||
However, if you give users two options and want to relay that one option is genuinely less complex than another, be
|
||||
specific about how and why.
|
||||
|
||||
For example, don't write, "Netdata's one-line installer is the easiest way to install Netdata." Instead, you might want
|
||||
to say, "Netdata's one-line installer requires fewer steps than manually installing from source."
|
||||
|
||||
#### Slang, metaphors, and jargon
|
||||
|
||||
A particular word, phrase, or metaphor you're familiar with might not translate well to the other cultures featured
|
||||
among Netdata's global community. We recommended you avoid slang or colloquialisms in your writing.
|
||||
|
||||
In addition, don't use abbreviations that have not yet been defined in the content. See our section on
|
||||
[abbreviations](#abbreviations-acronyms-and-initialisms) for additional guidance.
|
||||
|
||||
If you must use industry jargon, such as "mean time to resolution," define the term as clearly and concisely as you can.
|
||||
|
||||
> Netdata helps you reduce your organization's mean time to resolution (MTTR), which is the average time the responsible
|
||||
> team requires to repair a system and resolve an ongoing incident.
|
||||
|
||||
#### Spelling
|
||||
|
||||
While the Netdata team is mostly *not* American, we still aspire to use American spelling whenever possible, as it is
|
||||
the standard for the monitoring industry.
|
||||
|
||||
See the [word list](#word-list) for spellings of specific words.
|
||||
|
||||
#### Capitalization
|
||||
|
||||
Follow the general [English standards](https://owl.purdue.edu/owl/general_writing/mechanics/help_with_capitals.html) for
|
||||
capitalization. In summary:
|
||||
|
||||
- Capitalize the first word of every new sentence.
|
||||
- Don't use uppercase for emphasis. (Netdata is the BEST!)
|
||||
- Capitalize the names of brands, software, products, and companies according to their official guidelines. (Netdata,
|
||||
Docker, Apache, NGINX)
|
||||
- Avoid camel case (NetData) or all caps (NETDATA).
|
||||
|
||||
Whenever you refer to the company Netdata, Inc., or the open-source monitoring agent the company develops, capitalize
|
||||
**Netdata**.
|
||||
|
||||
However, if you are referring to a process, user, or group on a Linux system, use lowercase and fence the word in an
|
||||
inline code block: `` `netdata` ``.
|
||||
|
||||
| | |
|
||||
| --------------- | ---------------------------------------------------------------------------------------------- |
|
||||
| Not recommended | The netdata agent, which spawns the netdata process, is actively maintained by netdata, inc. |
|
||||
| **Recommended** | The Netdata Agent, which spawns the `netdata` process, is actively maintained by Netdata, Inc. |
|
||||
|
||||
##### Capitalization of document titles and page headings
|
||||
|
||||
Document titles and page headings should use sentence case. That means you should only capitalize the first word.
|
||||
|
||||
If you need to use the name of a brand, software, product, and company, capitalize it according to their official
|
||||
guidelines.
|
||||
|
||||
Also, don't put a period (`.`) or colon (`:`) at the end of a title or header.
|
||||
|
||||
| | |
|
||||
| --------------- | --------------------------------------------------------------------------------------------------- |
|
||||
| Not recommended | Getting Started Guide <br />Service Discovery and Auto-Detection: <br />Install netdata with docker |
|
||||
| **
|
||||
Recommended** | Getting started guide <br />Service discovery and auto-detection <br />Install Netdata with Docker |
|
||||
|
||||
#### Abbreviations (acronyms and initialisms)
|
||||
|
||||
Use abbreviations (including [acronyms and initialisms](https://www.dictionary.com/e/acronym-vs-abbreviation/)) in
|
||||
documentation when one exists, when it's widely accepted within the monitoring/sysadmin community, and when it improves
|
||||
the readability of a document.
|
||||
|
||||
When introducing an abbreviation to a document for the first time, give the reader both the spelled-out version and the
|
||||
shortened version at the same time. For example:
|
||||
|
||||
> Use Netdata to monitor Extended Berkeley Packet Filter (eBPF) metrics in real-time. After you define an abbreviation, don't switch back and forth. Use only the abbreviation for the rest of the document.
|
||||
|
||||
You can also use abbreviations in a document's title to keep the title short and relevant. If you do this, you should
|
||||
still introduce the spelled-out name alongside the abbreviation as soon as possible.
|
||||
|
||||
#### Clause order
|
||||
|
||||
When instructing users to take action, give them the context first. By placing the context in an initial clause at the
|
||||
beginning of the sentence, users can immediately know if they want to read more, follow a link, or skip ahead.
|
||||
|
||||
| | |
|
||||
| --------------- | ------------------------------------------------------------------------------ |
|
||||
| Not recommended | Read the reference guide if you'd like to learn more about custom dashboards. |
|
||||
| **Recommended** | If you'd like to learn more about custom dashboards, read the reference guide. |
|
||||
|
||||
#### Oxford comma
|
||||
|
||||
The Oxford comma is the comma used after the second-to-last item in a list of three or more items. It appears just
|
||||
before "and" or "or."
|
||||
|
||||
| | |
|
||||
| --------------- | ---------------------------------------------------------------------------- |
|
||||
| Not recommended | Netdata can monitor RAM, disk I/O, MySQL queries per second and lm-sensors. |
|
||||
| **Recommended** | Netdata can monitor RAM, disk I/O, MySQL queries per second, and lm-sensors. |
|
||||
|
||||
#### Future releases or features
|
||||
|
||||
Do not mention future releases or upcoming features in writing unless they have been previously communicated via a
|
||||
public roadmap.
|
||||
|
||||
In particular, documentation must describe, as accurately as possible, the Netdata Agent _as of
|
||||
the [latest commit](https://github.com/netdata/netdata/commits/master) in the GitHub repository_. For Netdata Cloud,
|
||||
documentation must reflect the *current state* of [production](https://app.netdata.cloud).
|
||||
|
||||
#### Informational links
|
||||
|
||||
Every link should clearly state its destination. Don't use words like "here" to describe where a link will take your
|
||||
reader.
|
||||
|
||||
| | |
|
||||
| --------------- | ------------------------------------------------------------------------------------------ |
|
||||
| Not recommended | To install Netdata, click [here](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md). |
|
||||
| **Recommended** | To install Netdata, read the [installation instructions](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md). |
|
||||
|
||||
Use links as often as required to provide necessary context. Blog posts and guides require less hyperlinks than
|
||||
documentation. See the section on [linking between documentation](#linking-between-documentation) for guidance on the
|
||||
Markdown syntax and path structure of inter-documentation links.
|
||||
|
||||
#### Contractions
|
||||
|
||||
Contractions like "you'll" or "they're" are acceptable in most Netdata writing. They're both authentic and playful, and
|
||||
reinforce the idea that you, as a writer, are guiding users through a particular idea, process, or feature.
|
||||
|
||||
Contractions are generally not used in press releases or other media engagements.
|
||||
|
||||
#### Emoji
|
||||
|
||||
Emoji can add fun and character to your writing, but should be used sparingly and only if it matches the content's tone
|
||||
and desired audience.
|
||||
|
||||
#### Switching Linux users
|
||||
|
||||
Netdata documentation often suggests that users switch from their normal user to the `netdata` user to run specific
|
||||
commands. Use the following command to instruct users to make the switch:
|
||||
|
||||
```bash
|
||||
sudo su -s /bin/bash netdata
|
||||
```
|
||||
|
||||
#### Hostname/IP address of a node
|
||||
|
||||
Use `NODE` instead of an actual or example IP address/hostname when referencing the process of navigating to a dashboard
|
||||
or API endpoint in a browser.
|
||||
|
||||
| | |
|
||||
| --------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Not recommended | Navigate to `http://example.com:19999` in your browser to see Netdata's dashboard. <br />Navigate to `http://203.0.113.0:19999` in your browser to see Netdata's dashboard. |
|
||||
| **
|
||||
Recommended** | Navigate to `http://NODE:19999` in your browser to see Netdata's dashboard. |
|
||||
|
||||
If you worry that `NODE` doesn't provide enough context for the user, particularly in documentation or guides designed
|
||||
for beginners, you can provide an explanation:
|
||||
|
||||
> With the Netdata Agent running, visit `http://NODE:19999/api/v1/info` in your browser, replacing `NODE` with the IP
|
||||
> address or hostname of your Agent.
|
||||
|
||||
#### Paths and running commands
|
||||
|
||||
When instructing users to run a Netdata-specific command, don't assume the path to said command, because not every
|
||||
Netdata Agent installation will have commands under the same paths. When applicable, help them navigate to the correct
|
||||
path, providing a recommendation or instructions on how to view the running configuration, which includes the correct
|
||||
paths.
|
||||
|
||||
For example, the [configuration](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md) doc first teaches users how to find the Netdata config directory
|
||||
and navigate to it, then runs commands from the `/etc/netdata` path so that the instructions are more universal.
|
||||
|
||||
Don't include full paths, beginning from the system's root (`/`), as these might not work on certain systems.
|
||||
|
||||
| | |
|
||||
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Not recommended | Use `edit-config` to edit Netdata's configuration: `sudo /etc/netdata/edit-config netdata.conf`. |
|
||||
| **
|
||||
Recommended** | Use `edit-config` to edit Netdata's configuration by first navigating to your [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#the-netdata-config-directory), which is typically at `/etc/netdata`, then running `sudo edit-config netdata.conf`. |
|
||||
|
||||
#### `sudo`
|
||||
|
||||
Include `sudo` before a command if you believe most Netdata users will need to elevate privileges to run it. This makes
|
||||
our writing more universal, and users on `sudo`-less systems are generally already aware that they need to run commands
|
||||
differently.
|
||||
|
||||
For example, most users need to use `sudo` with the `edit-config` script, because the Netdata config directory is owned
|
||||
by the `netdata` user. Same goes for restarting the Netdata Agent with `systemctl`.
|
||||
|
||||
| | |
|
||||
| --------------- | -------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Not recommended | Run `edit-config netdata.conf` to configure the Netdata Agent. <br />Run `systemctl restart netdata` to restart the Netdata Agent. |
|
||||
| **
|
||||
Recommended** | Run `sudo edit-config netdata.conf` to configure the Netdata Agent. <br />Run `sudo systemctl restart netdata` to restart the Netdata Agent. |
|
||||
|
||||
## Deploy and test docs
|
||||
|
||||
<!--
|
||||
TODO: Update this section after implemeting a _docker-compose_ for builting and testing learn
|
||||
-->
|
||||
|
||||
The Netdata team aggregates and publishes all documentation at [learn.netdata.cloud](/) using
|
||||
[Docusaurus](https://v2.docusaurus.io/) over at the [`netdata/learn` repository](https://github.com/netdata/learn).
|
||||
|
|
|
|||
|
|
@ -243,7 +243,7 @@ You can also read how to [monitor your infrastructure with Netdata Cloud](https:
|
|||
|
||||
Once you've added one or more nodes to a Space in Netdata Cloud, you can see aggregated eBPF metrics in the [Overview
|
||||
dashboard](https://github.com/netdata/netdata/blob/master/docs/visualize/overview-infrastructure.md) under the same **Applications** or **eBPF** sections that you
|
||||
find on the local Agent dashboard. Or, [create new dashboards](https://github.com/netdata/netdata/blob/master/docs/visualize/create-dashboards.md) using eBPF metrics
|
||||
find on the local Agent dashboard. Or, [create new dashboards](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md) using eBPF metrics
|
||||
from any number of distributed nodes to see how your application interacts with multiple Linux kernels on multiple Linux
|
||||
systems.
|
||||
|
||||
|
|
|
|||
|
|
@ -59,6 +59,34 @@ Here are a few example streaming configurations:
|
|||
metrics to parent `B`.
|
||||
- Any node with a database can generate alarms.
|
||||
|
||||
### A basic auto-scaling setup
|
||||
|
||||
If your nodes are ephemeral, a Netdata parent with persistent storage outside your production infrastructure can be used to
|
||||
store all the metrics from the Netdata children running on the ephemeral nodes.
|
||||
|
||||

|
||||
|
||||
### Archiving to a time-series database
|
||||
|
||||
The parent Netdata node can also archive metrics, for all its child nodes, to an external time-series database.
|
||||
|
||||
Check the Netdata [exporting documentation](https://github.com/netdata/netdata/blob/master/docs/export/external-databases.md) for configuring this.
|
||||
|
||||
This is how such a solution will work:
|
||||
|
||||

|
||||
|
||||
### An advanced setup
|
||||
|
||||
Netdata also supports `proxies` with and without a local database, and data retention can be different between all nodes.
|
||||
|
||||
This means a setup like the following is also possible:
|
||||
|
||||
<p align="center">
|
||||
<img src="https://cloud.githubusercontent.com/assets/2662304/23629551/bb1fd9c2-02c0-11e7-90f5-cab5a3ed4c53.png"/>
|
||||
</p>
|
||||
|
||||
## Enable streaming between nodes
|
||||
|
||||
The simplest streaming configuration is **replication**, in which a child node streams its metrics in real time to a
|
||||
|
|
@ -190,3 +218,4 @@ separate parent and child dashboards.
|
|||
|
||||
The child dashboard is also available directly at `http://PARENT-NODE:19999/host/CHILD-HOSTNAME`, which in this example
|
||||
is `http://203.0.113.0:19999/host/netdata-child`.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,489 +0,0 @@
|
|||
<!--
|
||||
title: "Streaming reference"
|
||||
description: "Each node running Netdata can stream the metrics it collects, in real time, to another node. See all of the available settings in this reference document."
|
||||
type: "reference"
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/metrics-storage-management/reference-streaming.md"
|
||||
sidebar_label: "Streaming reference"
|
||||
learn_status: "Published"
|
||||
learn_rel_path: "Configuration"
|
||||
-->
|
||||
|
||||
# Streaming reference
|
||||
|
||||
Each node running Netdata can stream the metrics it collects, in real time, to another node. To learn more, read about
|
||||
[how streaming works](https://github.com/netdata/netdata/blob/master/docs/metrics-storage-management/enable-streaming.md).
|
||||
|
||||
For a quickstart guide for enabling a simple `parent-child` streaming relationship, see our [stream metrics between
|
||||
nodes](https://github.com/netdata/netdata/blob/master/docs/metrics-storage-management/enable-streaming.md) doc. All other configuration options and scenarios are
|
||||
covered in the sections below.
|
||||
|
||||
## Configuration
|
||||
|
||||
There are two files responsible for configuring Netdata's streaming capabilities: `stream.conf` and `netdata.conf`.
|
||||
|
||||
From within your Netdata config directory (typically `/etc/netdata`), [use `edit-config`](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md) to
|
||||
open either `stream.conf` or `netdata.conf`.
|
||||
|
||||
```
|
||||
sudo ./edit-config stream.conf
|
||||
sudo ./edit-config netdata.conf
|
||||
```
|
||||
|
||||
## Settings
|
||||
|
||||
As mentioned above, both `stream.conf` and `netdata.conf` contain settings relevant to streaming.
|
||||
|
||||
### `stream.conf`
|
||||
|
||||
The `stream.conf` file contains three sections. The `[stream]` section is for configuring child nodes.
|
||||
|
||||
The `[API_KEY]` and `[MACHINE_GUID]` sections are both for configuring parent nodes, and share the same settings.
|
||||
`[API_KEY]` settings affect every child node using that key, whereas `[MACHINE_GUID]` settings affect only the child
|
||||
node with a matching GUID.
|
||||
|
||||
The file `/var/lib/netdata/registry/netdata.public.unique.id` contains a random GUID that **uniquely identifies each
|
||||
node**. This file is automatically generated by Netdata the first time it is started and remains unaltered forever.
|
||||
|
||||
#### `[stream]` section
|
||||
|
||||
| Setting | Default | Description |
|
||||
| :---------------------------------------------- | :------------------------ | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| `enabled` | `no` | Whether this node streams metrics to any parent. Change to `yes` to enable streaming. |
|
||||
| [`destination`](#destination) | ` ` | A space-separated list of parent nodes to attempt to stream to, with the first available parent receiving metrics, using the following format: `[PROTOCOL:]HOST[%INTERFACE][:PORT][:SSL]`. [Read more →](#destination) |
|
||||
| `ssl skip certificate verification` | `yes` | If you want to accept self-signed or expired certificates, set to `yes` and uncomment. |
|
||||
| `CApath` | `/etc/ssl/certs/` | The directory where known certificates are found. Defaults to OpenSSL's default path. |
|
||||
| `CAfile` | `/etc/ssl/certs/cert.pem` | Add a parent node certificate to the list of known certificates in `CAPath`. |
|
||||
| `api key` | ` ` | The `API_KEY` to use as the child node. |
|
||||
| `timeout seconds` | `60` | The timeout to connect and send metrics to a parent. |
|
||||
| `default port` | `19999` | The port to use if `destination` does not specify one. |
|
||||
| [`send charts matching`](#send-charts-matching) | `*` | A space-separated list of [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) to filter which charts are streamed. [Read more →](#send-charts-matching) |
|
||||
| `buffer size bytes` | `10485760` | The size of the buffer to use when sending metrics. The default `10485760` equals a buffer of 10MB, which is good for 60 seconds of data. Increase this if you expect latencies higher than that. The buffer is flushed on reconnect. |
|
||||
| `reconnect delay seconds` | `5` | How long to wait until retrying to connect to the parent node. |
|
||||
| `initial clock resync iterations` | `60` | Sync the clock of charts for how many seconds when starting. |
|
||||
|
||||
### `[API_KEY]` and `[MACHINE_GUID]` sections
|
||||
|
||||
| Setting | Default | Description |
|
||||
| :---------------------------------------------- | :------------------------ | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| `enabled` | `no` | Whether this API KEY enabled or disabled. |
|
||||
| [`allow from`](#allow-from) | `*` | A space-separated list of [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) matching the IPs of nodes that will stream metrics using this API key. [Read more →](#allow-from) |
|
||||
| `default history` | `3600` | The default amount of child metrics history to retain when using the `save`, `map`, or `ram` memory modes. |
|
||||
| [`default memory mode`](#default-memory-mode) | `ram` | The [database](https://github.com/netdata/netdata/blob/master/database/README.md) to use for all nodes using this `API_KEY`. Valid settings are `dbengine`, `map`, `save`, `ram`, or `none`. [Read more →](#default-memory-mode) |
|
||||
| `health enabled by default` | `auto` | Whether alarms and notifications should be enabled for nodes using this `API_KEY`. `auto` enables alarms when the child is connected. `yes` enables alarms always, and `no` disables alarms. |
|
||||
| `default postpone alarms on connect seconds` | `60` | Postpone alarms and notifications for a period of time after the child connects. |
|
||||
| `default proxy enabled` | ` ` | Route metrics through a proxy. |
|
||||
| `default proxy destination` | ` ` | Space-separated list of `IP:PORT` for proxies. |
|
||||
| `default proxy api key` | ` ` | The `API_KEY` of the proxy. |
|
||||
| `default send charts matching` | `*` | See [`send charts matching`](#send-charts-matching). |
|
||||
|
||||
#### `destination`
|
||||
|
||||
A space-separated list of parent nodes to attempt to stream to, with the first available parent receiving metrics, using
|
||||
the following format: `[PROTOCOL:]HOST[%INTERFACE][:PORT][:SSL]`.
|
||||
|
||||
- `PROTOCOL`: `tcp`, `udp`, or `unix`. (only tcp and unix are supported by parent nodes)
|
||||
- `HOST`: A IPv4, IPv6 IP, or a hostname, or a unix domain socket path. IPv6 IPs should be given with brackets
|
||||
`[ip:address]`.
|
||||
- `INTERFACE` (IPv6 only): The network interface to use.
|
||||
- `PORT`: The port number or service name (`/etc/services`) to use.
|
||||
- `SSL`: To enable TLS/SSL encryption of the streaming connection.
|
||||
|
||||
To enable TCP streaming to a parent node at `203.0.113.0` on port `20000` and with TLS/SSL encryption:
|
||||
|
||||
```conf
|
||||
[stream]
|
||||
destination = tcp:203.0.113.0:20000:SSL
|
||||
```
|
||||
|
||||
#### `send charts matching`
|
||||
|
||||
A space-separated list of [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) to filter which charts are streamed.
|
||||
|
||||
The default is a single wildcard `*`, which streams all charts.
|
||||
|
||||
To send only a few charts, list them explicitly, or list a group using a wildcard. To send _only_ the `apps.cpu` chart
|
||||
and charts with contexts beginning with `system.`:
|
||||
|
||||
```conf
|
||||
[stream]
|
||||
send charts matching = apps.cpu system.*
|
||||
```
|
||||
|
||||
To send all but a few charts, use `!` to create a negative match. To send _all_ charts _but_ `apps.cpu`:
|
||||
|
||||
```conf
|
||||
[stream]
|
||||
send charts matching = !apps.cpu *
|
||||
```
|
||||
|
||||
#### `allow from`
|
||||
|
||||
A space-separated list of [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) matching the IPs of nodes that
|
||||
will stream metrics using this API key. The order is important, left to right, as the first positive or negative match is used.
|
||||
|
||||
The default is `*`, which accepts all requests including the `API_KEY`.
|
||||
|
||||
To allow from only a specific IP address:
|
||||
|
||||
```conf
|
||||
[API_KEY]
|
||||
allow from = 203.0.113.10
|
||||
```
|
||||
|
||||
To allow all IPs starting with `10.*`, except `10.1.2.3`:
|
||||
|
||||
```conf
|
||||
[API_KEY]
|
||||
allow from = !10.1.2.3 10.*
|
||||
```
|
||||
|
||||
> If you set specific IP addresses here, and also use the `allow connections` setting in the `[web]` section of
|
||||
> `netdata.conf`, be sure to add the IP address there so that it can access the API port.
|
||||
|
||||
#### `default memory mode`
|
||||
|
||||
The [database](https://github.com/netdata/netdata/blob/master/database/README.md) to use for all nodes using this `API_KEY`. Valid settings are `dbengine`, `ram`,
|
||||
`save`, `map`, or `none`.
|
||||
|
||||
- `dbengine`: The default, recommended time-series database (TSDB) for Netdata. Stores recent metrics in memory, then
|
||||
efficiently spills them to disk for long-term storage.
|
||||
- `ram`: Stores metrics _only_ in memory, which means metrics are lost when Netdata stops or restarts. Ideal for
|
||||
streaming configurations that use ephemeral nodes.
|
||||
- `save`: Stores metrics in memory, but saves metrics to disk when Netdata stops or restarts, and loads historical
|
||||
metrics on start.
|
||||
- `map`: Stores metrics in memory-mapped files, like swap, with constant disk write.
|
||||
- `none`: No database.
|
||||
|
||||
When using `default memory mode = dbengine`, the parent node creates a separate instance of the TSDB to store metrics
|
||||
from child nodes. The [size of _each_ instance is configurable](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md) with the `page
|
||||
cache size` and `dbengine multihost disk space` settings in the `[global]` section in `netdata.conf`.
|
||||
|
||||
### `netdata.conf`
|
||||
|
||||
| Setting | Default | Description |
|
||||
| :----------------------------------------- | :---------------- | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| **`[global]` section** | | |
|
||||
| `memory mode` | `dbengine` | Determines the [database type](https://github.com/netdata/netdata/blob/master/database/README.md) to be used on that node. Other options settings include `none`, `ram`, `save`, and `map`. `none` disables the database at this host. This also disables alarms and notifications, as those can't run without a database. |
|
||||
| **`[web]` section** | | |
|
||||
| `mode` | `static-threaded` | Determines the [web server](https://github.com/netdata/netdata/blob/master/web/server/README.md) type. The other option is `none`, which disables the dashboard, API, and registry. |
|
||||
| `accept a streaming request every seconds` | `0` | Set a limit on how often a parent node accepts streaming requests from child nodes. `0` equals no limit. If this is set, you may see `... too busy to accept new streaming request. Will be allowed in X secs` in Netdata's `error.log`. |
|
||||
|
||||
## Examples
|
||||
|
||||
### Per-child settings
|
||||
|
||||
While the `[API_KEY]` section applies settings for any child node using that key, you can also use per-child settings
|
||||
with the `[MACHINE_GUID]` section.
|
||||
|
||||
For example, the metrics streamed from only the child node with `MACHINE_GUID` are saved in memory, not using the
|
||||
default `dbengine` as specified by the `API_KEY`, and alarms are disabled.
|
||||
|
||||
```conf
|
||||
[API_KEY]
|
||||
enabled = yes
|
||||
default memory mode = dbengine
|
||||
health enabled by default = auto
|
||||
allow from = *
|
||||
|
||||
[MACHINE_GUID]
|
||||
enabled = yes
|
||||
memory mode = save
|
||||
health enabled = no
|
||||
```
|
||||
|
||||
### Securing streaming with TLS/SSL
|
||||
|
||||
Netdata does not activate TLS encryption by default. To encrypt streaming connections, you first need to [enable TLS
|
||||
support](https://github.com/netdata/netdata/blob/master/web/server/README.md#enabling-tls-support) on the parent. With encryption enabled on the receiving side, you
|
||||
need to instruct the child to use TLS/SSL as well. On the child's `stream.conf`, configure the destination as follows:
|
||||
|
||||
```
|
||||
[stream]
|
||||
destination = host:port:SSL
|
||||
```
|
||||
|
||||
The word `SSL` appended to the end of the destination tells the child that connections must be encrypted.
|
||||
|
||||
> While Netdata uses Transport Layer Security (TLS) 1.2 to encrypt communications rather than the obsolete SSL protocol,
|
||||
> it's still common practice to refer to encrypted web connections as `SSL`. Many vendors, like Nginx and even Netdata
|
||||
> itself, use `SSL` in configuration files, whereas documentation will always refer to encrypted communications as `TLS`
|
||||
> or `TLS/SSL`.
|
||||
|
||||
#### Certificate verification
|
||||
|
||||
When TLS/SSL is enabled on the child, the default behavior will be to not connect with the parent unless the server's
|
||||
certificate can be verified via the default chain. In case you want to avoid this check, add the following to the
|
||||
child's `stream.conf` file:
|
||||
|
||||
```
|
||||
[stream]
|
||||
ssl skip certificate verification = yes
|
||||
```
|
||||
|
||||
#### Trusted certificate
|
||||
|
||||
If you've enabled [certificate verification](#certificate-verification), you might see errors from the OpenSSL library
|
||||
when there's a problem with checking the certificate chain (`X509_V_ERR_UNABLE_TO_GET_ISSUER_CERT_LOCALLY`). More
|
||||
importantly, OpenSSL will reject self-signed certificates.
|
||||
|
||||
Given these known issues, you have two options. If you trust your certificate, you can set the options `CApath` and
|
||||
`CAfile` to inform Netdata where your certificates, and the certificate trusted file, are stored.
|
||||
|
||||
For more details about these options, you can read about [verify
|
||||
locations](https://www.openssl.org/docs/man1.1.1/man3/SSL_CTX_load_verify_locations.html).
|
||||
|
||||
Before you changed your streaming configuration, you need to copy your trusted certificate to your child system and add
|
||||
the certificate to OpenSSL's list.
|
||||
|
||||
On most Linux distributions, the `update-ca-certificates` command searches inside the `/usr/share/ca-certificates`
|
||||
directory for certificates. You should double-check by reading the `update-ca-certificate` manual (`man
|
||||
update-ca-certificate`), and then change the directory in the below commands if needed.
|
||||
|
||||
If you have `sudo` configured on your child system, you can use that to run the following commands. If not, you'll have
|
||||
to log in as `root` to complete them.
|
||||
|
||||
```
|
||||
# mkdir /usr/share/ca-certificates/netdata
|
||||
# cp parent_cert.pem /usr/share/ca-certificates/netdata/parent_cert.crt
|
||||
# chown -R netdata.netdata /usr/share/ca-certificates/netdata/
|
||||
```
|
||||
|
||||
First, you create a new directory to store your certificates for Netdata. Next, you need to change the extension on your
|
||||
certificate from `.pem` to `.crt` so it's compatible with `update-ca-certificate`. Finally, you need to change
|
||||
permissions so the user that runs Netdata can access the directory where you copied in your certificate.
|
||||
|
||||
Next, edit the file `/etc/ca-certificates.conf` and add the following line:
|
||||
|
||||
```
|
||||
netdata/parent_cert.crt
|
||||
```
|
||||
|
||||
Now you update the list of certificates running the following, again either as `sudo` or `root`:
|
||||
|
||||
```
|
||||
# update-ca-certificates
|
||||
```
|
||||
|
||||
> Some Linux distributions have different methods of updating the certificate list. For more details, please read this
|
||||
> guide on [adding trusted root certificates](https://github.com/Busindre/How-to-Add-trusted-root-certificates).
|
||||
|
||||
Once you update your certificate list, you can set the stream parameters for Netdata to trust the parent certificate.
|
||||
Open `stream.conf` for editing and change the following lines:
|
||||
|
||||
```
|
||||
[stream]
|
||||
CApath = /etc/ssl/certs/
|
||||
CAfile = /etc/ssl/certs/parent_cert.pem
|
||||
```
|
||||
|
||||
With this configuration, the `CApath` option tells Netdata to search for trusted certificates inside `/etc/ssl/certs`.
|
||||
The `CAfile` option specifies the Netdata parent certificate is located at `/etc/ssl/certs/parent_cert.pem`. With this
|
||||
configuration, you can skip using the system's entire list of certificates and use Netdata's parent certificate instead.
|
||||
|
||||
#### Expected behaviors
|
||||
|
||||
With the introduction of TLS/SSL, the parent-child communication behaves as shown in the table below, depending on the
|
||||
following configurations:
|
||||
|
||||
- **Parent TLS (Yes/No)**: Whether the `[web]` section in `netdata.conf` has `ssl key` and `ssl certificate`.
|
||||
- **Parent port TLS (-/force/optional)**: Depends on whether the `[web]` section `bind to` contains a `^SSL=force` or
|
||||
`^SSL=optional` directive on the port(s) used for streaming.
|
||||
- **Child TLS (Yes/No)**: Whether the destination in the child's `stream.conf` has `:SSL` at the end.
|
||||
- **Child TLS Verification (yes/no)**: Value of the child's `stream.conf` `ssl skip certificate verification`
|
||||
parameter (default is no).
|
||||
|
||||
| Parent TLS enabled | Parent port SSL | Child TLS | Child SSL Ver. | Behavior |
|
||||
| :----------------- | :--------------- | :-------- | :------------- | :--------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| No | - | No | no | Legacy behavior. The parent-child stream is unencrypted. |
|
||||
| Yes | force | No | no | The parent rejects the child connection. |
|
||||
| Yes | -/optional | No | no | The parent-child stream is unencrypted (expected situation for legacy child nodes and newer parent nodes) |
|
||||
| Yes | -/force/optional | Yes | no | The parent-child stream is encrypted, provided that the parent has a valid TLS/SSL certificate. Otherwise, the child refuses to connect. |
|
||||
| Yes | -/force/optional | Yes | yes | The parent-child stream is encrypted. |
|
||||
|
||||
### Proxy
|
||||
|
||||
A proxy is a node that receives metrics from a child, then streams them onward to a parent. To configure a proxy,
|
||||
configure it as a receiving and a sending Netdata at the same time.
|
||||
|
||||
Netdata proxies may or may not maintain a database for the metrics passing through them. When they maintain a database,
|
||||
they can also run health checks (alarms and notifications) for the remote host that is streaming the metrics.
|
||||
|
||||
In the following example, the proxy receives metrics from a child node using the `API_KEY` of
|
||||
`66666666-7777-8888-9999-000000000000`, then stores metrics using `dbengine`. It then uses the `API_KEY` of
|
||||
`11111111-2222-3333-4444-555555555555` to proxy those same metrics on to a parent node at `203.0.113.0`.
|
||||
|
||||
```conf
|
||||
[stream]
|
||||
enabled = yes
|
||||
destination = 203.0.113.0
|
||||
api key = 11111111-2222-3333-4444-555555555555
|
||||
|
||||
[66666666-7777-8888-9999-000000000000]
|
||||
enabled = yes
|
||||
default memory mode = dbengine
|
||||
```
|
||||
|
||||
### Ephemeral nodes
|
||||
|
||||
Netdata can help you monitor ephemeral nodes, such as containers in an auto-scaling infrastructure, by always streaming
|
||||
metrics to any number of permanently-running parent nodes.
|
||||
|
||||
On the parent, set the following in `stream.conf`:
|
||||
|
||||
```conf
|
||||
[11111111-2222-3333-4444-555555555555]
|
||||
# enable/disable this API key
|
||||
enabled = yes
|
||||
|
||||
# one hour of data for each of the child nodes
|
||||
default history = 3600
|
||||
|
||||
# do not save child metrics on disk
|
||||
default memory = ram
|
||||
|
||||
# alarms checks, only while the child is connected
|
||||
health enabled by default = auto
|
||||
```
|
||||
|
||||
On the child nodes, set the following in `stream.conf`:
|
||||
|
||||
```bash
|
||||
[stream]
|
||||
# stream metrics to another Netdata
|
||||
enabled = yes
|
||||
|
||||
# the IP and PORT of the parent
|
||||
destination = 10.11.12.13:19999
|
||||
|
||||
# the API key to use
|
||||
api key = 11111111-2222-3333-4444-555555555555
|
||||
```
|
||||
|
||||
In addition, edit `netdata.conf` on each child node to disable the database and alarms.
|
||||
|
||||
```bash
|
||||
[global]
|
||||
# disable the local database
|
||||
memory mode = none
|
||||
|
||||
[health]
|
||||
# disable health checks
|
||||
enabled = no
|
||||
```
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
Both parent and child nodes log information at `/var/log/netdata/error.log`.
|
||||
|
||||
If the child manages to connect to the parent you will see something like (on the parent):
|
||||
|
||||
```
|
||||
2017-03-09 09:38:52: netdata: INFO : STREAM [receive from [10.11.12.86]:38564]: new client connection.
|
||||
2017-03-09 09:38:52: netdata: INFO : STREAM xxx [10.11.12.86]:38564: receive thread created (task id 27721)
|
||||
2017-03-09 09:38:52: netdata: INFO : STREAM xxx [receive from [10.11.12.86]:38564]: client willing to stream metrics for host 'xxx' with machine_guid '1234567-1976-11e6-ae19-7cdd9077342a': update every = 1, history = 3600, memory mode = ram, health auto
|
||||
2017-03-09 09:38:52: netdata: INFO : STREAM xxx [receive from [10.11.12.86]:38564]: initializing communication...
|
||||
2017-03-09 09:38:52: netdata: INFO : STREAM xxx [receive from [10.11.12.86]:38564]: receiving metrics...
|
||||
```
|
||||
|
||||
and something like this on the child:
|
||||
|
||||
```
|
||||
2017-03-09 09:38:28: netdata: INFO : STREAM xxx [send to box:19999]: connecting...
|
||||
2017-03-09 09:38:28: netdata: INFO : STREAM xxx [send to box:19999]: initializing communication...
|
||||
2017-03-09 09:38:28: netdata: INFO : STREAM xxx [send to box:19999]: waiting response from remote netdata...
|
||||
2017-03-09 09:38:28: netdata: INFO : STREAM xxx [send to box:19999]: established communication - sending metrics...
|
||||
```
|
||||
|
||||
The following sections describe the most common issues you might encounter when connecting parent and child nodes.
|
||||
|
||||
### Slow connections between parent and child
|
||||
|
||||
When you have a slow connection between parent and child, Netdata raises a few different errors. Most of the
|
||||
errors will appear in the child's `error.log`.
|
||||
|
||||
```bash
|
||||
netdata ERROR : STREAM_SENDER[CHILD HOSTNAME] : STREAM CHILD HOSTNAME [send to PARENT IP:PARENT PORT]: too many data pending - buffer is X bytes long,
|
||||
Y unsent - we have sent Z bytes in total, W on this connection. Closing connection to flush the data.
|
||||
```
|
||||
|
||||
On the parent side, you may see various error messages, most commonly the following:
|
||||
|
||||
```
|
||||
netdata ERROR : STREAM_PARENT[CHILD HOSTNAME,[CHILD IP]:CHILD PORT] : read failed: end of file
|
||||
```
|
||||
|
||||
Another common problem in slow connections is the child sending a partial message to the parent. In this case, the
|
||||
parent will write the following to its `error.log`:
|
||||
|
||||
```
|
||||
ERROR : STREAM_RECEIVER[CHILD HOSTNAME,[CHILD IP]:CHILD PORT] : sent command 'B' which is not known by netdata, for host 'HOSTNAME'. Disabling it.
|
||||
```
|
||||
|
||||
In this example, `B` was part of a `BEGIN` message that was cut due to connection problems.
|
||||
|
||||
Slow connections can also cause problems when the parent misses a message and then receives a command related to the
|
||||
missed message. For example, a parent might miss a message containing the child's charts, and then doesn't know
|
||||
what to do with the `SET` message that follows. When that happens, the parent will show a message like this:
|
||||
|
||||
```
|
||||
ERROR : STREAM_RECEIVER[CHILD HOSTNAME,[CHILD IP]:CHILD PORT] : requested a SET on chart 'CHART NAME' of host 'HOSTNAME', without a dimension. Disabling it.
|
||||
```
|
||||
|
||||
### Child cannot connect to parent
|
||||
|
||||
When the child can't connect to a parent for any reason (misconfiguration, networking, firewalls, parent
|
||||
down), you will see the following in the child's `error.log`.
|
||||
|
||||
```
|
||||
ERROR : STREAM_SENDER[HOSTNAME] : Failed to connect to 'PARENT IP', port 'PARENT PORT' (errno 113, No route to host)
|
||||
```
|
||||
|
||||
### 'Is this a Netdata?'
|
||||
|
||||
This question can appear when Netdata starts the stream and receives an unexpected response. This error can appear when
|
||||
the parent is using SSL and the child tries to connect using plain text. You will also see this message when
|
||||
Netdata connects to another server that isn't Netdata. The complete error message will look like this:
|
||||
|
||||
```
|
||||
ERROR : STREAM_SENDER[CHILD HOSTNAME] : STREAM child HOSTNAME [send to PARENT HOSTNAME:PARENT PORT]: server is not replying properly (is it a netdata?).
|
||||
```
|
||||
|
||||
### Stream charts wrong
|
||||
|
||||
Chart data needs to be consistent between child and parent nodes. If there are differences between chart data on
|
||||
a parent and a child, such as gaps in metrics collection, it most often means your child's `memory mode`
|
||||
does not match the parent's. To learn more about the different ways Netdata can store metrics, and thus keep chart
|
||||
data consistent, read our [memory mode documentation](https://github.com/netdata/netdata/blob/master/database/README.md).
|
||||
|
||||
### Forbidding access
|
||||
|
||||
You may see errors about "forbidding access" for a number of reasons. It could be because of a slow connection between
|
||||
the parent and child nodes, but it could also be due to other failures. Look in your parent's `error.log` for errors
|
||||
that look like this:
|
||||
|
||||
```
|
||||
STREAM [receive from [child HOSTNAME]:child IP]: `MESSAGE`. Forbidding access."
|
||||
```
|
||||
|
||||
`MESSAGE` will have one of the following patterns:
|
||||
|
||||
- `request without KEY` : The message received is incomplete and the KEY value can be API, hostname, machine GUID.
|
||||
- `API key 'VALUE' is not valid GUID`: The UUID received from child does not have the format defined in [RFC
|
||||
4122](https://tools.ietf.org/html/rfc4122)
|
||||
- `machine GUID 'VALUE' is not GUID.`: This error with machine GUID is like the previous one.
|
||||
- `API key 'VALUE' is not allowed`: This stream has a wrong API key.
|
||||
- `API key 'VALUE' is not permitted from this IP`: The IP is not allowed to use STREAM with this parent.
|
||||
- `machine GUID 'VALUE' is not allowed.`: The GUID that is trying to send stream is not allowed.
|
||||
- `Machine GUID 'VALUE' is not permitted from this IP. `: The IP does not match the pattern or IP allowed to connect to
|
||||
use stream.
|
||||
|
||||
### Netdata could not create a stream
|
||||
|
||||
The connection between parent and child is a stream. When the parent can't convert the initial connection into
|
||||
a stream, it will write the following message inside `error.log`:
|
||||
|
||||
```
|
||||
file descriptor given is not a valid stream
|
||||
```
|
||||
|
||||
After logging this error, Netdata will close the stream.
|
||||
|
|
@ -94,7 +94,7 @@ from every node in your infrastructure on a single dashboard.
|
|||
|
||||
|
||||
Read more about [creating new dashboards](https://github.com/netdata/netdata/blob/master/docs/visualize/create-dashboards.md) for more details about the process and
|
||||
Read more about [creating new dashboards](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md) for more details about the process and
|
||||
additional tips on best leveraging the feature to help you troubleshoot complex performance problems.
|
||||
|
||||
## Set up your nodes
|
||||
|
|
|
|||
|
|
@ -1,73 +0,0 @@
|
|||
<!--
|
||||
title: "Create new dashboards"
|
||||
description: "Create new dashboards in Netdata Cloud, with any number of metrics from any node on your infrastructure, for targeted troubleshooting."
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/visualize/create-dashboards.md
|
||||
sidebar_label: "Create new dashboards"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Tasks"
|
||||
learn_rel_path: "Operations/Netdata Cloud Visualizations"
|
||||
-->
|
||||
|
||||
# Create new dashboards
|
||||
|
||||
With Netdata Cloud, you can build new dashboards that put key metrics from any number of distributed systems in one
|
||||
place for a bird's eye view of your infrastructure. You can create more meaningful visualizations for troubleshooting or
|
||||
keep a watchful eye on your infrastructure's most meaningful metrics without moving from node to node.
|
||||
|
||||
In the War Room you want to monitor with this dashboard, click on your War Room's dropdown, then click on the green **+
|
||||
Add** button next to **Dashboards**. In the panel, give your new dashboard a name, and click **+ Add**.
|
||||
|
||||
Click the **Add Chart** button to add your first chart card. From the dropdown, select the node you want to add the
|
||||
chart from, then the context. Netdata Cloud shows you a preview of the chart before you finish adding it.
|
||||
|
||||
The **Add Text** button creates a new card with user-defined text, which you can use to describe or document a
|
||||
particular dashboard's meaning and purpose. Enrich the dashboards you create with documentation or procedures on how to
|
||||
respond
|
||||
|
||||
|
||||
|
||||
Charts in dashboards
|
||||
are [fully interactive](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md) and
|
||||
synchronized. You can
|
||||
pan through time, zoom, highlight specific timeframes, and more.
|
||||
|
||||
Move any card by clicking on their top panel and dragging them to a new location. Other cards re-sort to the grid system
|
||||
automatically. You can also resize any card by grabbing the bottom-right corner and dragging it to its new size.
|
||||
|
||||
Hit the **Save** button to finalize your dashboard. Any other member of the War Room can now access it and make changes.
|
||||
|
||||
## Jump to single-node Cloud dashboards
|
||||
|
||||
While dashboards help you associate essential charts from distributed nodes on a single pane of glass, you might need
|
||||
more detail when troubleshooting an issue. Quickly jump to any node's dashboard by clicking the 3-dot icon in the corner
|
||||
of any card to open a menu. Hit the **Go to Chart** item.
|
||||
|
||||
Netdata Cloud takes you to the same chart on that node's dashboard. You can now navigate all that node's metrics and
|
||||
[interact with charts](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md) to
|
||||
further investigate anomalies or troubleshoot
|
||||
complex performance problems.
|
||||
|
||||
When viewing a single-node Cloud dashboard, you can also click on the add to dashboard icon <img
|
||||
src="https://user-images.githubusercontent.com/1153921/87587846-827fdb00-c697-11ea-9f31-aed0b8c6afba.png" alt="Dashboard
|
||||
icon" class="image-inline" /> to quickly add that chart to a new or existing dashboard. You might find this useful when
|
||||
investigating an anomaly and want to quickly populate a dashboard with potentially correlated metrics.
|
||||
|
||||
## Pin dashboards and navigate through Netdata Cloud
|
||||
|
||||
Click on the **Pin** button in any dashboard to put those charts into a separate panel at the bottom of the screen. You
|
||||
can now navigate through Netdata Cloud freely, individual Cloud dashboards, the Nodes view, different War Rooms, or even
|
||||
different Spaces, and have those valuable metrics follow you.
|
||||
|
||||
Pinning dashboards helps you correlate potentially related charts across your infrastructure and discover root causes
|
||||
faster.
|
||||
|
||||
## What's next?
|
||||
|
||||
While it's useful to see real-time metrics on flexible dashboards, you need ways to know precisely when an anomaly
|
||||
strikes. Every Netdata Agent comes with a health watchdog that
|
||||
uses [alarms](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) and
|
||||
[notifications](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md) to notify you of
|
||||
issues seconds after they strike.
|
||||
|
||||
|
||||
|
|
@ -85,7 +85,7 @@ given node to quickly _jump to the same chart in that node's single-node dashboa
|
|||
You can use single-node dashboards in Netdata Cloud to drill down on specific issues, scrub backward in time to
|
||||
investigate historical data, and see like metrics presented meaningfully to help you troubleshoot performance problems.
|
||||
All of the familiar [interactions](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md) are available, as is adding any chart
|
||||
to a [new dashboard](https://github.com/netdata/netdata/blob/master/docs/visualize/create-dashboards.md).
|
||||
to a [new dashboard](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md).
|
||||
|
||||
## Nodes view
|
||||
|
||||
|
|
|
|||
|
|
@ -1,13 +1,3 @@
|
|||
<!--
|
||||
title: "User guide: Exporting to Netdata, Prometheus, Grafana stack"
|
||||
description: "Using Netdata in conjunction with Prometheus and Grafana."
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/exporting/WALKTHROUGH.md"
|
||||
sidebar_label: "User guide: Netdata, Prometheus, Grafana stack"
|
||||
learn_status: "Published"
|
||||
learn_rel_path: "Integrations/Export"
|
||||
sidebar_position: 100
|
||||
-->
|
||||
|
||||
# Netdata, Prometheus, Grafana stack
|
||||
|
||||
## Intro
|
||||
|
|
|
|||
|
|
@ -1,225 +1,21 @@
|
|||
<!--
|
||||
title: "Export metrics to Prometheus"
|
||||
description: "Export Netdata metrics to Prometheus for archiving and further analysis."
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/exporting/prometheus/README.md"
|
||||
sidebar_label: "Using Netdata with Prometheus"
|
||||
learn_status: "Published"
|
||||
learn_rel_path: "Integrations/Export"
|
||||
-->
|
||||
|
||||
import { OneLineInstallWget, OneLineInstallCurl } from '@site/src/components/OneLineInstall/'
|
||||
|
||||
# Using Netdata with Prometheus
|
||||
|
||||
Prometheus is a distributed monitoring system which offers a very simple setup along with a robust data model. Recently
|
||||
Netdata added support for Prometheus. I'm going to quickly show you how to install both Netdata and Prometheus on the
|
||||
same server. We can then use Grafana pointed at Prometheus to obtain long term metrics Netdata offers. I'm assuming we
|
||||
are starting at a fresh ubuntu shell (whether you'd like to follow along in a VM or a cloud instance is up to you).
|
||||
Netdata supports exporting metrics to Prometheus in two ways:
|
||||
|
||||
## Installing Netdata and Prometheus
|
||||
- You can [configure Prometheus to scrape Netdata metrics](#configure-prometheus-to-scrape-netdata-metrics).
|
||||
|
||||
### Installing Netdata
|
||||
|
||||
There are number of ways to install Netdata according to
|
||||
[Installation](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md). The suggested way
|
||||
of installing the latest Netdata and keep it upgrade automatically.
|
||||
|
||||
<!-- candidate for reuse -->
|
||||
|
||||
To install Netdata, run the following as your normal user:
|
||||
|
||||
<OneLineInstallWget/>
|
||||
|
||||
Or, if you have cURL but not wget (such as on macOS):
|
||||
|
||||
<OneLineInstallCurl/>
|
||||
|
||||
At this point we should have Netdata listening on port 19999. Attempt to take your browser here:
|
||||
|
||||
```sh
|
||||
http://your.netdata.ip:19999
|
||||
```
|
||||
|
||||
_(replace `your.netdata.ip` with the IP or hostname of the server running Netdata)_
|
||||
|
||||
### Installing Prometheus
|
||||
|
||||
In order to install Prometheus we are going to introduce our own systemd startup script along with an example of
|
||||
prometheus.yaml configuration. Prometheus needs to be pointed to your server at a specific target url for it to scrape
|
||||
Netdata's api. Prometheus is always a pull model meaning Netdata is the passive client within this architecture.
|
||||
Prometheus always initiates the connection with Netdata.
|
||||
|
||||
#### Download Prometheus
|
||||
|
||||
```sh
|
||||
cd /tmp && curl -s https://api.github.com/repos/prometheus/prometheus/releases/latest \
|
||||
| grep "browser_download_url.*linux-amd64.tar.gz" \
|
||||
| cut -d '"' -f 4 \
|
||||
| wget -qi -
|
||||
```
|
||||
|
||||
#### Create prometheus system user
|
||||
|
||||
```sh
|
||||
sudo useradd -r prometheus
|
||||
```
|
||||
|
||||
#### Create prometheus directory
|
||||
|
||||
```sh
|
||||
sudo mkdir /opt/prometheus
|
||||
sudo chown prometheus:prometheus /opt/prometheus
|
||||
```
|
||||
|
||||
#### Untar prometheus directory
|
||||
|
||||
```sh
|
||||
sudo tar -xvf /tmp/prometheus-*linux-amd64.tar.gz -C /opt/prometheus --strip=1
|
||||
```
|
||||
|
||||
#### Install prometheus.yml
|
||||
|
||||
We will use the following `prometheus.yml` file. Save it at `/opt/prometheus/prometheus.yml`.
|
||||
|
||||
Make sure to replace `your.netdata.ip` with the IP or hostname of the host running Netdata.
|
||||
|
||||
```yaml
|
||||
# my global config
|
||||
global:
|
||||
scrape_interval: 5s # Set the scrape interval to every 5 seconds. Default is every 1 minute.
|
||||
evaluation_interval: 5s # Evaluate rules every 5 seconds. The default is every 1 minute.
|
||||
# scrape_timeout is set to the global default (10s).
|
||||
|
||||
# Attach these labels to any time series or alerts when communicating with
|
||||
# external systems (federation, remote storage, Alertmanager).
|
||||
external_labels:
|
||||
monitor: 'codelab-monitor'
|
||||
|
||||
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
|
||||
rule_files:
|
||||
# - "first.rules"
|
||||
# - "second.rules"
|
||||
|
||||
# A scrape configuration containing exactly one endpoint to scrape:
|
||||
# Here it's Prometheus itself.
|
||||
scrape_configs:
|
||||
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
|
||||
- job_name: 'prometheus'
|
||||
|
||||
# metrics_path defaults to '/metrics'
|
||||
# scheme defaults to 'http'.
|
||||
|
||||
static_configs:
|
||||
- targets: [ '0.0.0.0:9090' ]
|
||||
|
||||
- job_name: 'netdata-scrape'
|
||||
|
||||
metrics_path: '/api/v1/allmetrics'
|
||||
params:
|
||||
# format: prometheus | prometheus_all_hosts
|
||||
# You can use `prometheus_all_hosts` if you want Prometheus to set the `instance` to your hostname instead of IP
|
||||
format: [ prometheus ]
|
||||
#
|
||||
# sources: as-collected | raw | average | sum | volume
|
||||
# default is: average
|
||||
#source: [as-collected]
|
||||
#
|
||||
# server name for this prometheus - the default is the client IP
|
||||
# for Netdata to uniquely identify it
|
||||
#server: ['prometheus1']
|
||||
honor_labels: true
|
||||
|
||||
static_configs:
|
||||
- targets: [ '{your.netdata.ip}:19999' ]
|
||||
```
|
||||
|
||||
#### Install nodes.yml
|
||||
|
||||
The following is completely optional, it will enable Prometheus to generate alerts from some Netdata sources. Tweak the
|
||||
values to your own needs. We will use the following `nodes.yml` file below. Save it at `/opt/prometheus/nodes.yml`, and
|
||||
add a _- "nodes.yml"_ entry under the _rule_files:_ section in the example prometheus.yml file above.
|
||||
|
||||
```yaml
|
||||
groups:
|
||||
- name: nodes
|
||||
|
||||
rules:
|
||||
- alert: node_high_cpu_usage_70
|
||||
expr: sum(sum_over_time(netdata_system_cpu_percentage_average{dimension=~"(user|system|softirq|irq|guest)"}[10m])) by (job) / sum(count_over_time(netdata_system_cpu_percentage_average{dimension="idle"}[10m])) by (job) > 70
|
||||
for: 1m
|
||||
annotations:
|
||||
description: '{{ $labels.job }} on ''{{ $labels.job }}'' CPU usage is at {{ humanize $value }}%.'
|
||||
summary: CPU alert for container node '{{ $labels.job }}'
|
||||
|
||||
- alert: node_high_memory_usage_70
|
||||
expr: 100 / sum(netdata_system_ram_MB_average) by (job)
|
||||
* sum(netdata_system_ram_MB_average{dimension=~"free|cached"}) by (job) < 30
|
||||
for: 1m
|
||||
annotations:
|
||||
description: '{{ $labels.job }} memory usage is {{ humanize $value}}%.'
|
||||
summary: Memory alert for container node '{{ $labels.job }}'
|
||||
|
||||
- alert: node_low_root_filesystem_space_20
|
||||
expr: 100 / sum(netdata_disk_space_GB_average{family="/"}) by (job)
|
||||
* sum(netdata_disk_space_GB_average{family="/",dimension=~"avail|cached"}) by (job) < 20
|
||||
for: 1m
|
||||
annotations:
|
||||
description: '{{ $labels.job }} root filesystem space is {{ humanize $value}}%.'
|
||||
summary: Root filesystem alert for container node '{{ $labels.job }}'
|
||||
|
||||
- alert: node_root_filesystem_fill_rate_6h
|
||||
expr: predict_linear(netdata_disk_space_GB_average{family="/",dimension=~"avail|cached"}[1h], 6 * 3600) < 0
|
||||
for: 1h
|
||||
labels:
|
||||
severity: critical
|
||||
annotations:
|
||||
description: Container node {{ $labels.job }} root filesystem is going to fill up in 6h.
|
||||
summary: Disk fill alert for Swarm node '{{ $labels.job }}'
|
||||
```
|
||||
|
||||
#### Install prometheus.service
|
||||
|
||||
Save this service file as `/etc/systemd/system/prometheus.service`:
|
||||
|
||||
```sh
|
||||
[Unit]
|
||||
Description=Prometheus Server
|
||||
AssertPathExists=/opt/prometheus
|
||||
|
||||
[Service]
|
||||
Type=simple
|
||||
WorkingDirectory=/opt/prometheus
|
||||
User=prometheus
|
||||
Group=prometheus
|
||||
ExecStart=/opt/prometheus/prometheus --config.file=/opt/prometheus/prometheus.yml --log.level=info
|
||||
ExecReload=/bin/kill -SIGHUP $MAINPID
|
||||
ExecStop=/bin/kill -SIGINT $MAINPID
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
```
|
||||
|
||||
##### Start Prometheus
|
||||
|
||||
```sh
|
||||
sudo systemctl start prometheus
|
||||
sudo systemctl enable prometheus
|
||||
```
|
||||
|
||||
Prometheus should now start and listen on port 9090. Attempt to head there with your browser.
|
||||
|
||||
If everything is working correctly when you fetch `http://your.prometheus.ip:9090` you will see a 'Status' tab. Click
|
||||
this and click on 'targets' We should see the Netdata host as a scraped target.
|
||||
|
||||
---
|
||||
- You can [configure Netdata to push metrics to Prometheus](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md)
|
||||
, using the Prometheus remote write API.
|
||||
|
||||
## Netdata support for Prometheus
|
||||
|
||||
Before explaining the changes, we have to understand the key differences between Netdata and Prometheus.
|
||||
Regardless of the methodology, you first need to understand how Netdata structures the metrics it exports to Prometheus
|
||||
and the capabilities it provides. The examples provided in this document assume that you will be using Netdata as
|
||||
a metrics endpoint, but the concepts apply as well to the remote write API method.
|
||||
|
||||
### understanding Netdata metrics
|
||||
### Understanding Netdata metrics
|
||||
|
||||
#### charts
|
||||
#### Charts
|
||||
|
||||
Each chart in Netdata has several properties (common to all its metrics):
|
||||
|
||||
|
|
@ -234,7 +30,7 @@ Each chart in Netdata has several properties (common to all its metrics):
|
|||
|
||||
- `units` is the units for all the metrics attached to the chart.
|
||||
|
||||
#### dimensions
|
||||
#### Dimensions
|
||||
|
||||
Then each Netdata chart contains metrics called `dimensions`. All the dimensions of a chart have the same units of
|
||||
measurement, and are contextually in the same category (ie. the metrics for disk bandwidth are `read` and `write` and
|
||||
|
|
@ -465,4 +261,101 @@ through a web proxy, or when multiple Prometheus servers are NATed to a single I
|
|||
`&server=NAME` to the URL. This `NAME` is used by Netdata to uniquely identify each Prometheus server and keep track of
|
||||
its last access time.
|
||||
|
||||
## Configure Prometheus to scrape Netdata metrics
|
||||
|
||||
The following `prometheus.yml` file will scrape all netdata metrics "as collected".
|
||||
|
||||
Make sure to replace `your.netdata.ip` with the IP or hostname of the host running Netdata.
|
||||
|
||||
```yaml
|
||||
# my global config
|
||||
global:
|
||||
scrape_interval: 5s # Set the scrape interval to every 5 seconds. Default is every 1 minute.
|
||||
evaluation_interval: 5s # Evaluate rules every 5 seconds. The default is every 1 minute.
|
||||
# scrape_timeout is set to the global default (10s).
|
||||
|
||||
# Attach these labels to any time series or alerts when communicating with
|
||||
# external systems (federation, remote storage, Alertmanager).
|
||||
external_labels:
|
||||
monitor: 'codelab-monitor'
|
||||
|
||||
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
|
||||
rule_files:
|
||||
# - "first.rules"
|
||||
# - "second.rules"
|
||||
|
||||
# A scrape configuration containing exactly one endpoint to scrape:
|
||||
# Here it's Prometheus itself.
|
||||
scrape_configs:
|
||||
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
|
||||
- job_name: 'prometheus'
|
||||
|
||||
# metrics_path defaults to '/metrics'
|
||||
# scheme defaults to 'http'.
|
||||
|
||||
static_configs:
|
||||
- targets: [ '0.0.0.0:9090' ]
|
||||
|
||||
- job_name: 'netdata-scrape'
|
||||
|
||||
metrics_path: '/api/v1/allmetrics'
|
||||
params:
|
||||
# format: prometheus | prometheus_all_hosts
|
||||
# You can use `prometheus_all_hosts` if you want Prometheus to set the `instance` to your hostname instead of IP
|
||||
format: [ prometheus ]
|
||||
#
|
||||
# sources: as-collected | raw | average | sum | volume
|
||||
# default is: average
|
||||
#source: [as-collected]
|
||||
#
|
||||
# server name for this prometheus - the default is the client IP
|
||||
# for Netdata to uniquely identify it
|
||||
#server: ['prometheus1']
|
||||
honor_labels: true
|
||||
|
||||
static_configs:
|
||||
- targets: [ '{your.netdata.ip}:19999' ]
|
||||
```
|
||||
|
||||
### Prometheus alerts for Netdata metrics
|
||||
|
||||
The following is an example of a `nodes.yml` file that will allow Prometheus to generate alerts from some Netdata sources.
|
||||
Save it at `/opt/prometheus/nodes.yml`, and add a _- "nodes.yml"_ entry under the _rule_files:_ section in the example prometheus.yml file above.
|
||||
|
||||
```yaml
|
||||
groups:
|
||||
- name: nodes
|
||||
|
||||
rules:
|
||||
- alert: node_high_cpu_usage_70
|
||||
expr: sum(sum_over_time(netdata_system_cpu_percentage_average{dimension=~"(user|system|softirq|irq|guest)"}[10m])) by (job) / sum(count_over_time(netdata_system_cpu_percentage_average{dimension="idle"}[10m])) by (job) > 70
|
||||
for: 1m
|
||||
annotations:
|
||||
description: '{{ $labels.job }} on ''{{ $labels.job }}'' CPU usage is at {{ humanize $value }}%.'
|
||||
summary: CPU alert for container node '{{ $labels.job }}'
|
||||
|
||||
- alert: node_high_memory_usage_70
|
||||
expr: 100 / sum(netdata_system_ram_MB_average) by (job)
|
||||
* sum(netdata_system_ram_MB_average{dimension=~"free|cached"}) by (job) < 30
|
||||
for: 1m
|
||||
annotations:
|
||||
description: '{{ $labels.job }} memory usage is {{ humanize $value}}%.'
|
||||
summary: Memory alert for container node '{{ $labels.job }}'
|
||||
|
||||
- alert: node_low_root_filesystem_space_20
|
||||
expr: 100 / sum(netdata_disk_space_GB_average{family="/"}) by (job)
|
||||
* sum(netdata_disk_space_GB_average{family="/",dimension=~"avail|cached"}) by (job) < 20
|
||||
for: 1m
|
||||
annotations:
|
||||
description: '{{ $labels.job }} root filesystem space is {{ humanize $value}}%.'
|
||||
summary: Root filesystem alert for container node '{{ $labels.job }}'
|
||||
|
||||
- alert: node_root_filesystem_fill_rate_6h
|
||||
expr: predict_linear(netdata_disk_space_GB_average{family="/",dimension=~"avail|cached"}[1h], 6 * 3600) < 0
|
||||
for: 1h
|
||||
labels:
|
||||
severity: critical
|
||||
annotations:
|
||||
description: Container node {{ $labels.job }} root filesystem is going to fill up in 6h.
|
||||
summary: Disk fill alert for Swarm node '{{ $labels.job }}'
|
||||
```
|
||||
|
|
|
|||
|
|
@ -1,13 +1,4 @@
|
|||
<!--
|
||||
title: "Health monitoring"
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/health/README.md
|
||||
sidebar_label: "Health monitoring"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "Concepts"
|
||||
learn_rel_path: "Concepts"
|
||||
-->
|
||||
|
||||
# Health monitoring
|
||||
# Alerts and notifications
|
||||
|
||||
The Netdata Agent is a health watchdog for the health and performance of your systems, services, and applications. We've
|
||||
worked closely with our community of DevOps engineers, SREs, and developers to define hundreds of production-ready
|
||||
|
|
|
|||
|
|
@ -37,7 +37,8 @@ for the [single line installer](#install-on-linux-with-one-line-installer), or [
|
|||
#### Agent user interface
|
||||
|
||||
To access the UI provided by the locally installed agent, open a browser and navigate to `http://NODE:19999`, replacing `NODE` with either `localhost` or
|
||||
the hostname/IP address of the remote node. You can also read more about [how the agent dashboard works](https://github.com/netdata/netdata/blob/master/docs/dashboard/how-dashboard-works.md).
|
||||
the hostname/IP address of the remote node. You can also read more about
|
||||
[the agent dashboard](https://github.com/netdata/netdata/blob/master/web/gui/README.md).
|
||||
|
||||
#### Configuration
|
||||
|
||||
|
|
|
|||
|
|
@ -1,145 +1,160 @@
|
|||
# Streaming and replication reference
|
||||
|
||||
Each Netdata node is able to replicate/mirror its database to another Netdata node, by streaming the collected
|
||||
metrics in real-time. This is quite different to
|
||||
[data archiving to third party time-series databases](https://github.com/netdata/netdata/blob/master/exporting/README.md).
|
||||
The nodes that send metrics are called **child** nodes, and the nodes that receive metrics are called **parent** nodes.
|
||||
|
||||
There are also **proxy** nodes, which collect metrics from a child and sends it to a parent.
|
||||
|
||||
When one Netdata node streams metrics another, the receiving instance can use the data for all features of a typical Netdata node, for example:
|
||||
|
||||
- Visualize metrics with a dashboard
|
||||
- Run health checks that trigger alarms and send alarm notifications
|
||||
- Export metrics to an external time-series database
|
||||
|
||||
This document contains advanced streaming options and suggested deployment options for production.
|
||||
If you haven't already done so, we suggest you first go through the
|
||||
[quick introduction to streaming](https://github.com/netdata/netdata/blob/master/docs/metrics-storage-management/enable-streaming.md)
|
||||
, for your first, basic parent child setup.
|
||||
|
||||
## Supported configurations
|
||||
|
||||
### Netdata without a database or web API (headless collector)
|
||||
|
||||
A local Netdata Agent (child), **without any database or alarms**, collects metrics and sends them to another Netdata node
|
||||
(parent).
|
||||
The same parent can collect data for any number of child nodes and serves alerts for each child.
|
||||
|
||||
The node menu shows a list of all "databases streamed to" the parent. Clicking one of those links allows the user to
|
||||
view the full dashboard of the child node. The URL has the form
|
||||
`http://parent-host:parent-port/host/child-host/`.
|
||||
|
||||
|
||||
In a headless setup, the child acts as a plain data collector. It spawns all external plugins, but instead of maintaining a
|
||||
local database and accepting dashboard requests, it streams all metrics to the parent.
|
||||
|
||||
This setup works great to reduce the memory footprint. Depending on the enabled plugins, memory usage is between 6 MiB and 40 MiB. To reduce the memory usage as much as
|
||||
possible, refer to the [performance optimization guide](https://github.com/netdata/netdata/blob/master/docs/guides/configure/performance.md).
|
||||
|
||||
|
||||
### Database Replication
|
||||
|
||||
The local Netdata Agent (child), **with a local database (and possibly alarms)**, collects metrics and
|
||||
sends them to another Netdata node (parent).
|
||||
|
||||
The user can use all the functions **at both** `http://child-ip:child-port/` and
|
||||
`http://parent-host:parent-port/host/child-host/`.
|
||||
|
||||
The child and the parent may have different data retention policies for the same metrics.
|
||||
|
||||
Alerts for the child are triggered by **both** the child and the parent.
|
||||
It is possible to enable different alert configurations on the parent and the child.
|
||||
|
||||
In order for custom chart names on the child to work correctly, follow the form `type.name`. The parent will truncate the `type` part and substitute the original chart `type` to store the name in the database.
|
||||
|
||||
### Netdata proxies
|
||||
|
||||
The local Netdata Agent(child), with or without a database, collects metrics and sends them to another
|
||||
Netdata node(**proxy**), which may or may not maintain a database, which forwards them to another
|
||||
Netdata (parent).
|
||||
|
||||
Alerts for the child can be triggered by any of the involved hosts that maintains a database.
|
||||
|
||||
You can daisy-chain any number of Netdata, each with or without a database and
|
||||
with or without alerts for the child metrics.
|
||||
|
||||
### Mix and match with exporting engine
|
||||
|
||||
All nodes that maintain a database can also send their data to an external database.
|
||||
This allows quite complex setups.
|
||||
|
||||
Example:
|
||||
|
||||
1. Netdata nodes `A` and `B` do not maintain a database and stream metrics to Netdata node `C`(live streaming functionality).
|
||||
2. Netdata node `C` maintains a database for `A`, `B`, `C` and archives all metrics to `graphite` with 10 second detail (exporting functionality).
|
||||
3. Netdata node `C` also streams data for `A`, `B`, `C` to Netdata `D`, which also collects data from `E`, `F` and `G` from another DMZ (live streaming functionality).
|
||||
4. Netdata node `D` is just a proxy, without a database, that streams all data to a remote site at Netdata `H`.
|
||||
5. Netdata node `H` maintains a database for `A`, `B`, `C`, `D`, `E`, `F`, `G`, `H` and sends all data to `opentsdb` with 5 seconds detail (exporting functionality)
|
||||
6. Alerts are triggered by `H` for all hosts.
|
||||
7. Users can use all Netdata nodes that maintain a database to view metrics (i.e. at `H` all hosts can be viewed).
|
||||
|
||||
## Configuration
|
||||
|
||||
The following options affect how Netdata streams:
|
||||
There are two files responsible for configuring Netdata's streaming capabilities: `stream.conf` and `netdata.conf`.
|
||||
|
||||
From within your Netdata config directory (typically `/etc/netdata`), [use `edit-config`](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md) to
|
||||
open either `stream.conf` or `netdata.conf`.
|
||||
|
||||
```
|
||||
[global]
|
||||
memory mode = none | ram | save | map | dbengine
|
||||
sudo ./edit-config stream.conf
|
||||
sudo ./edit-config netdata.conf
|
||||
```
|
||||
|
||||
`[global].memory mode = none` disables the database at this host. This also disables health
|
||||
monitoring because a node can't have health monitoring without a database.
|
||||
### `stream.conf`
|
||||
|
||||
```
|
||||
[web]
|
||||
mode = none | static-threaded
|
||||
accept a streaming request every seconds = 0
|
||||
```
|
||||
The `stream.conf` file contains three sections. The `[stream]` section is for configuring child nodes.
|
||||
|
||||
`[web].mode = none` disables the API (Netdata will not listen to any ports).
|
||||
This also disables the registry (there cannot be a registry without an API).
|
||||
The `[API_KEY]` and `[MACHINE_GUID]` sections are both for configuring parent nodes, and share the same settings.
|
||||
`[API_KEY]` settings affect every child node using that key, whereas `[MACHINE_GUID]` settings affect only the child
|
||||
node with a matching GUID.
|
||||
|
||||
`accept a streaming request every seconds` can be used to set a limit on how often a parent node will accept streaming
|
||||
requests from its child nodes. 0 sets no limit, 1 means maximum once every second. If this is set, you may see error log
|
||||
entries "... too busy to accept new streaming request. Will be allowed in X secs".
|
||||
The file `/var/lib/netdata/registry/netdata.public.unique.id` contains a random GUID that **uniquely identifies each
|
||||
node**. This file is automatically generated by Netdata the first time it is started and remains unaltered forever.
|
||||
|
||||
You can [use](https://github.com/netdata/netdata/blob/master/exporting/README.md#configuration) the exporting engine to configure data archiving to an external database (it archives all databases maintained on
|
||||
this host).
|
||||
#### `[stream]` section
|
||||
|
||||
### Streaming configuration
|
||||
| Setting | Default | Description |
|
||||
| :---------------------------------------------- | :------------------------ | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| `enabled` | `no` | Whether this node streams metrics to any parent. Change to `yes` to enable streaming. |
|
||||
| [`destination`](#destination) | ` ` | A space-separated list of parent nodes to attempt to stream to, with the first available parent receiving metrics, using the following format: `[PROTOCOL:]HOST[%INTERFACE][:PORT][:SSL]`. [Read more →](#destination) |
|
||||
| `ssl skip certificate verification` | `yes` | If you want to accept self-signed or expired certificates, set to `yes` and uncomment. |
|
||||
| `CApath` | `/etc/ssl/certs/` | The directory where known certificates are found. Defaults to OpenSSL's default path. |
|
||||
| `CAfile` | `/etc/ssl/certs/cert.pem` | Add a parent node certificate to the list of known certificates in `CAPath`. |
|
||||
| `api key` | ` ` | The `API_KEY` to use as the child node. |
|
||||
| `timeout seconds` | `60` | The timeout to connect and send metrics to a parent. |
|
||||
| `default port` | `19999` | The port to use if `destination` does not specify one. |
|
||||
| [`send charts matching`](#send-charts-matching) | `*` | A space-separated list of [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) to filter which charts are streamed. [Read more →](#send-charts-matching) |
|
||||
| `buffer size bytes` | `10485760` | The size of the buffer to use when sending metrics. The default `10485760` equals a buffer of 10MB, which is good for 60 seconds of data. Increase this if you expect latencies higher than that. The buffer is flushed on reconnect. |
|
||||
| `reconnect delay seconds` | `5` | How long to wait until retrying to connect to the parent node. |
|
||||
| `initial clock resync iterations` | `60` | Sync the clock of charts for how many seconds when starting. |
|
||||
|
||||
The new file `stream.conf` contains streaming configuration for a sending and a receiving Netdata node.
|
||||
### `[API_KEY]` and `[MACHINE_GUID]` sections
|
||||
|
||||
To configure streaming on your system:
|
||||
1. Generate an API key using `uuidgen`. Note: API keys are just random GUIDs. You can use the same API key on all your Netdata, or use a different API key for any pair of sending-receiving Netdata nodes.
|
||||
| Setting | Default | Description |
|
||||
| :---------------------------------------------- | :------------------------ | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| `enabled` | `no` | Whether this API KEY enabled or disabled. |
|
||||
| [`allow from`](#allow-from) | `*` | A space-separated list of [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) matching the IPs of nodes that will stream metrics using this API key. [Read more →](#allow-from) |
|
||||
| `default history` | `3600` | The default amount of child metrics history to retain when using the `save`, `map`, or `ram` memory modes. |
|
||||
| [`default memory mode`](#default-memory-mode) | `ram` | The [database](https://github.com/netdata/netdata/blob/master/database/README.md) to use for all nodes using this `API_KEY`. Valid settings are `dbengine`, `map`, `save`, `ram`, or `none`. [Read more →](#default-memory-mode) |
|
||||
| `health enabled by default` | `auto` | Whether alarms and notifications should be enabled for nodes using this `API_KEY`. `auto` enables alarms when the child is connected. `yes` enables alarms always, and `no` disables alarms. |
|
||||
| `default postpone alarms on connect seconds` | `60` | Postpone alarms and notifications for a period of time after the child connects. |
|
||||
| `default proxy enabled` | ` ` | Route metrics through a proxy. |
|
||||
| `default proxy destination` | ` ` | Space-separated list of `IP:PORT` for proxies. |
|
||||
| `default proxy api key` | ` ` | The `API_KEY` of the proxy. |
|
||||
| `default send charts matching` | `*` | See [`send charts matching`](#send-charts-matching). |
|
||||
|
||||
2. Authorize the communication between a pair of sending-receiving Netdata nodes using the generated API key.
|
||||
Once the communication is authorized, the sending Netdata node can push metrics for any number of hosts.
|
||||
#### `destination`
|
||||
|
||||
3. To edit `stream.conf`, run `/etc/netdata/edit-config stream.conf`
|
||||
A space-separated list of parent nodes to attempt to stream to, with the first available parent receiving metrics, using
|
||||
the following format: `[PROTOCOL:]HOST[%INTERFACE][:PORT][:SSL]`.
|
||||
|
||||
The following sections describe how you can configure sending and receiving Netdata nodes.
|
||||
- `PROTOCOL`: `tcp`, `udp`, or `unix`. (only tcp and unix are supported by parent nodes)
|
||||
- `HOST`: A IPv4, IPv6 IP, or a hostname, or a unix domain socket path. IPv6 IPs should be given with brackets
|
||||
`[ip:address]`.
|
||||
- `INTERFACE` (IPv6 only): The network interface to use.
|
||||
- `PORT`: The port number or service name (`/etc/services`) to use.
|
||||
- `SSL`: To enable TLS/SSL encryption of the streaming connection.
|
||||
|
||||
##### Options for the sending node
|
||||
To enable TCP streaming to a parent node at `203.0.113.0` on port `20000` and with TLS/SSL encryption:
|
||||
|
||||
This is the section for the sending Netdata node. On the receiving node, `[stream].enabled` can be `no`.
|
||||
If it is `yes`, the receiving node will also stream the metrics to another node (i.e. it will be
|
||||
a proxy).
|
||||
|
||||
```
|
||||
```conf
|
||||
[stream]
|
||||
enabled = yes | no
|
||||
destination = IP:PORT[:SSL] ...
|
||||
api key = XXXXXXXXXXX
|
||||
|
||||
[API_KEY]
|
||||
enabled = yes | no
|
||||
|
||||
[MACHINE_GUID]
|
||||
enabled = yes | no
|
||||
destination = tcp:203.0.113.0:20000:SSL
|
||||
```
|
||||
This is an overview of how these options can be combined:
|
||||
|
||||
#### `send charts matching`
|
||||
|
||||
A space-separated list of [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) to filter which charts are streamed.
|
||||
|
||||
The default is a single wildcard `*`, which streams all charts.
|
||||
|
||||
To send only a few charts, list them explicitly, or list a group using a wildcard. To send _only_ the `apps.cpu` chart
|
||||
and charts with contexts beginning with `system.`:
|
||||
|
||||
```conf
|
||||
[stream]
|
||||
send charts matching = apps.cpu system.*
|
||||
```
|
||||
|
||||
To send all but a few charts, use `!` to create a negative match. To send _all_ charts _but_ `apps.cpu`:
|
||||
|
||||
```conf
|
||||
[stream]
|
||||
send charts matching = !apps.cpu *
|
||||
```
|
||||
|
||||
#### `allow from`
|
||||
|
||||
A space-separated list of [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) matching the IPs of nodes that
|
||||
will stream metrics using this API key. The order is important, left to right, as the first positive or negative match is used.
|
||||
|
||||
The default is `*`, which accepts all requests including the `API_KEY`.
|
||||
|
||||
To allow from only a specific IP address:
|
||||
|
||||
```conf
|
||||
[API_KEY]
|
||||
allow from = 203.0.113.10
|
||||
```
|
||||
|
||||
To allow all IPs starting with `10.*`, except `10.1.2.3`:
|
||||
|
||||
```conf
|
||||
[API_KEY]
|
||||
allow from = !10.1.2.3 10.*
|
||||
```
|
||||
|
||||
> If you set specific IP addresses here, and also use the `allow connections` setting in the `[web]` section of
|
||||
> `netdata.conf`, be sure to add the IP address there so that it can access the API port.
|
||||
|
||||
#### `default memory mode`
|
||||
|
||||
The [database](https://github.com/netdata/netdata/blob/master/database/README.md) to use for all nodes using this `API_KEY`. Valid settings are `dbengine`, `ram`,
|
||||
`save`, `map`, or `none`.
|
||||
|
||||
- `dbengine`: The default, recommended time-series database (TSDB) for Netdata. Stores recent metrics in memory, then
|
||||
efficiently spills them to disk for long-term storage.
|
||||
- `ram`: Stores metrics _only_ in memory, which means metrics are lost when Netdata stops or restarts. Ideal for
|
||||
streaming configurations that use ephemeral nodes.
|
||||
- `save`: Stores metrics in memory, but saves metrics to disk when Netdata stops or restarts, and loads historical
|
||||
metrics on start.
|
||||
- `map`: Stores metrics in memory-mapped files, like swap, with constant disk write.
|
||||
- `none`: No database.
|
||||
|
||||
When using `default memory mode = dbengine`, the parent node creates a separate instance of the TSDB to store metrics
|
||||
from child nodes. The [size of _each_ instance is configurable](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md) with the `page
|
||||
cache size` and `dbengine multihost disk space` settings in the `[global]` section in `netdata.conf`.
|
||||
|
||||
### `netdata.conf`
|
||||
|
||||
| Setting | Default | Description |
|
||||
| :----------------------------------------- | :---------------- | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| **`[global]` section** | | |
|
||||
| `memory mode` | `dbengine` | Determines the [database type](https://github.com/netdata/netdata/blob/master/database/README.md) to be used on that node. Other options settings include `none`, `ram`, `save`, and `map`. `none` disables the database at this host. This also disables alarms and notifications, as those can't run without a database. |
|
||||
| **`[web]` section** | | |
|
||||
| `mode` | `static-threaded` | Determines the [web server](https://github.com/netdata/netdata/blob/master/web/server/README.md) type. The other option is `none`, which disables the dashboard, API, and registry. |
|
||||
| `accept a streaming request every seconds` | `0` | Set a limit on how often a parent node accepts streaming requests from child nodes. `0` equals no limit. If this is set, you may see `... too busy to accept new streaming request. Will be allowed in X secs` in Netdata's `error.log`. |
|
||||
|
||||
### Basic use cases
|
||||
|
||||
This is an overview of how the main options can be combined:
|
||||
|
||||
| target|memory<br/>mode|web<br/>mode|stream<br/>enabled|exporting|alarms|dashboard|
|
||||
|------|:-------------:|:----------:|:----------------:|:-----:|:----:|:-------:|
|
||||
|
|
@ -148,171 +163,27 @@ This is an overview of how these options can be combined:
|
|||
| proxy with db|not `none`|not `none`|`yes`|possible|possible|yes|
|
||||
| central netdata|not `none`|not `none`|`no`|possible|possible|yes|
|
||||
|
||||
For the options to encrypt the data stream between the child and the parent, refer to [securing the communication](#securing-streaming-communications)
|
||||
### Per-child settings
|
||||
|
||||
While the `[API_KEY]` section applies settings for any child node using that key, you can also use per-child settings
|
||||
with the `[MACHINE_GUID]` section.
|
||||
|
||||
##### Options for the receiving node
|
||||
For example, the metrics streamed from only the child node with `MACHINE_GUID` are saved in memory, not using the
|
||||
default `dbengine` as specified by the `API_KEY`, and alarms are disabled.
|
||||
|
||||
For a receiving Netdata node, the `stream.conf` looks like this:
|
||||
|
||||
```sh
|
||||
# replace API_KEY with your uuidgen generated GUID
|
||||
```conf
|
||||
[API_KEY]
|
||||
enabled = yes
|
||||
default history = 3600
|
||||
default memory mode = save
|
||||
default memory mode = dbengine
|
||||
health enabled by default = auto
|
||||
allow from = *
|
||||
```
|
||||
|
||||
You can add many such sections, one for each API key. The above are used as default values for
|
||||
all hosts pushed with this API key.
|
||||
|
||||
You can also add sections like this:
|
||||
|
||||
```sh
|
||||
# replace MACHINE_GUID with the child /var/lib/netdata/registry/netdata.public.unique.id
|
||||
[MACHINE_GUID]
|
||||
enabled = yes
|
||||
history = 3600
|
||||
memory mode = save
|
||||
health enabled = yes
|
||||
allow from = *
|
||||
health enabled = no
|
||||
```
|
||||
|
||||
The above is the parent configuration of a single host, at the parent end. `MACHINE_GUID` is
|
||||
the unique id the Netdata generating the metrics (i.e. the Netdata that originally collects
|
||||
them `/var/lib/netdata/registry/netdata.unique.id`). So, metrics for Netdata `A` that pass through
|
||||
any number of other Netdata, will have the same `MACHINE_GUID`.
|
||||
|
||||
You can also use `default memory mode = dbengine` for an API key or `memory mode = dbengine` for
|
||||
a single host. The additional `page cache size` and `dbengine multihost disk space` configuration options
|
||||
are inherited from the global Netdata configuration.
|
||||
|
||||
##### Allow from
|
||||
|
||||
`allow from` settings are [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md): string matches
|
||||
that use `*` as wildcard (any number of times) and a `!` prefix for a negative match.
|
||||
So: `allow from = !10.1.2.3 10.*` will allow all IPs in `10.*` except `10.1.2.3`. The order is
|
||||
important: left to right, the first positive or negative match is used.
|
||||
|
||||
##### Tracing
|
||||
|
||||
When a child is trying to push metrics to a parent or proxy, it logs entries like these:
|
||||
|
||||
```
|
||||
2017-02-25 01:57:44: netdata: ERROR: Failed to connect to '10.11.12.1', port '19999' (errno 111, Connection refused)
|
||||
2017-02-25 01:57:44: netdata: ERROR: STREAM costa-pc [send to 10.11.12.1:19999]: failed to connect
|
||||
2017-02-25 01:58:04: netdata: INFO : STREAM costa-pc [send to 10.11.12.1:19999]: initializing communication...
|
||||
2017-02-25 01:58:04: netdata: INFO : STREAM costa-pc [send to 10.11.12.1:19999]: waiting response from remote netdata...
|
||||
2017-02-25 01:58:14: netdata: INFO : STREAM costa-pc [send to 10.11.12.1:19999]: established communication - sending metrics...
|
||||
2017-02-25 01:58:14: netdata: ERROR: STREAM costa-pc [send]: discarding 1900 bytes of metrics already in the buffer.
|
||||
2017-02-25 01:58:14: netdata: INFO : STREAM costa-pc [send]: ready - sending metrics...
|
||||
```
|
||||
|
||||
The receiving end (proxy or parent) logs entries like these:
|
||||
|
||||
```
|
||||
2017-02-25 01:58:04: netdata: INFO : STREAM [receive from [10.11.12.11]:33554]: new client connection.
|
||||
2017-02-25 01:58:04: netdata: INFO : STREAM costa-pc [10.11.12.11]:33554: receive thread created (task id 7698)
|
||||
2017-02-25 01:58:14: netdata: INFO : Host 'costa-pc' with guid '12345678-b5a6-11e6-8a50-00508db7e9c9' initialized, os: linux, update every: 1, memory mode: ram, history entries: 3600, streaming: disabled, health: enabled, cache_dir: '/var/cache/netdata/12345678-b5a6-11e6-8a50-00508db7e9c9', varlib_dir: '/var/lib/netdata/12345678-b5a6-11e6-8a50-00508db7e9c9', health_log: '/var/lib/netdata/12345678-b5a6-11e6-8a50-00508db7e9c9/health/health-log.db', alarms default handler: '/usr/libexec/netdata/plugins.d/alarm-notify.sh', alarms default recipient: 'root'
|
||||
2017-02-25 01:58:14: netdata: INFO : STREAM costa-pc [receive from [10.11.12.11]:33554]: initializing communication...
|
||||
2017-02-25 01:58:14: netdata: INFO : STREAM costa-pc [receive from [10.11.12.11]:33554]: receiving metrics...
|
||||
```
|
||||
|
||||
For Netdata v1.9+, streaming can also be monitored via `access.log`.
|
||||
|
||||
### Securing streaming communications
|
||||
|
||||
Netdata does not activate TLS encryption by default. To encrypt streaming connections:
|
||||
1. On the parent node (receiving node), [enable TLS support](https://github.com/netdata/netdata/blob/master/web/server/README.md#enabling-tls-support).
|
||||
2. On the child's `stream.conf`, configure the destination as follows:
|
||||
|
||||
```
|
||||
[stream]
|
||||
destination = host:port:SSL
|
||||
```
|
||||
|
||||
The word `SSL` appended to the end of the destination tells the child that connections must be encrypted.
|
||||
|
||||
> While Netdata uses Transport Layer Security (TLS) 1.2 to encrypt communications rather than the obsolete SSL protocol,
|
||||
> it's still common practice to refer to encrypted web connections as `SSL`. Many vendors, like Nginx and even Netdata
|
||||
> itself, use `SSL` in configuration files, whereas documentation will always refer to encrypted communications as `TLS`
|
||||
> or `TLS/SSL`.
|
||||
|
||||
#### Certificate verification
|
||||
|
||||
When TLS/SSL is enabled on the child, the default behavior will be to not connect with the parent unless the server's certificate can be verified via the default chain. In case you want to avoid this check, add the following to the child's `stream.conf` file:
|
||||
|
||||
```
|
||||
[stream]
|
||||
ssl skip certificate verification = yes
|
||||
```
|
||||
|
||||
#### Trusted certificate
|
||||
|
||||
If you've enabled [certificate verification](#certificate-verification), you might see errors from the OpenSSL library when there's a problem with checking the certificate chain (`X509_V_ERR_UNABLE_TO_GET_ISSUER_CERT_LOCALLY`). More importantly, OpenSSL will reject self-signed certificates.
|
||||
|
||||
Given these known issues, you have two options. If you trust your certificate, you can set the options `CApath` and `CAfile` to inform Netdata where your certificates, and the certificate trusted file, are stored.
|
||||
|
||||
For more details about these options, you can read about [verify locations](https://www.openssl.org/docs/man1.1.1/man3/SSL_CTX_load_verify_locations.html).
|
||||
|
||||
Before you changed your streaming configuration, you need to copy your trusted certificate to your child system and add the certificate to OpenSSL's list.
|
||||
|
||||
On most Linux distributions, the `update-ca-certificates` command searches inside the `/usr/share/ca-certificates` directory for certificates. You should double-check by reading the `update-ca-certificate` manual (`man update-ca-certificate`), and then change the directory in the below commands if needed.
|
||||
|
||||
If you have `sudo` configured on your child system, you can use that to run the following commands. If not, you'll have to log in as `root` to complete them.
|
||||
|
||||
```
|
||||
# mkdir /usr/share/ca-certificates/netdata
|
||||
# cp parent_cert.pem /usr/share/ca-certificates/netdata/parent_cert.crt
|
||||
# chown -R netdata.netdata /usr/share/ca-certificates/netdata/
|
||||
```
|
||||
|
||||
First, you create a new directory to store your certificates for Netdata. Next, you need to change the extension on your certificate from `.pem` to `.crt` so it's compatible with `update-ca-certificate`. Finally, you need to change permissions so the user that runs Netdata can access the directory where you copied in your certificate.
|
||||
|
||||
Next, edit the file `/etc/ca-certificates.conf` and add the following line:
|
||||
|
||||
```
|
||||
netdata/parent_cert.crt
|
||||
```
|
||||
|
||||
Now you update the list of certificates running the following, again either as `sudo` or `root`:
|
||||
|
||||
```
|
||||
# update-ca-certificates
|
||||
```
|
||||
|
||||
> Some Linux distributions have different methods of updating the certificate list. For more details, please read this
|
||||
> guide on [adding trusted root certificates](https://github.com/Busindre/How-to-Add-trusted-root-certificates).
|
||||
|
||||
Once you update your certificate list, you can set the stream parameters for Netdata to trust the parent certificate. Open `stream.conf` for editing and change the following lines:
|
||||
|
||||
```
|
||||
[stream]
|
||||
CApath = /etc/ssl/certs/
|
||||
CAfile = /etc/ssl/certs/parent_cert.pem
|
||||
```
|
||||
|
||||
With this configuration, the `CApath` option tells Netdata to search for trusted certificates inside `/etc/ssl/certs`. The `CAfile` option specifies the Netdata parent certificate is located at `/etc/ssl/certs/parent_cert.pem`. With this configuration, you can skip using the system's entire list of certificates and use Netdata's parent certificate instead.
|
||||
|
||||
#### Expected behaviors
|
||||
|
||||
With the introduction of TLS/SSL, the parent-child communication behaves as shown in the table below, depending on the following configurations:
|
||||
|
||||
- **Parent TLS (Yes/No)**: Whether the `[web]` section in `netdata.conf` has `ssl key` and `ssl certificate`.
|
||||
- **Parent port TLS (-/force/optional)**: Depends on whether the `[web]` section `bind to` contains a `^SSL=force` or `^SSL=optional` directive on the port(s) used for streaming.
|
||||
- **Child TLS (Yes/No)**: Whether the destination in the child's `stream.conf` has `:SSL` at the end.
|
||||
- **Child TLS Verification (yes/no)**: Value of the child's `stream.conf` `ssl skip certificate verification` parameter (default is no).
|
||||
|
||||
| Parent TLS enabled|Parent port SSL|Child TLS|Child SSL Ver.|Behavior|
|
||||
|:----------------:|:-------------:|:-------:|:------------:|:-------|
|
||||
| No|-|No|no|Legacy behavior. The parent-child stream is unencrypted.|
|
||||
| Yes|force|No|no|The parent rejects the child connection.|
|
||||
| Yes|-/optional|No|no|The parent-child stream is unencrypted (expected situation for legacy child nodes and newer parent nodes)|
|
||||
| Yes|-/force/optional|Yes|no|The parent-child stream is encrypted, provided that the parent has a valid TLS/SSL certificate. Otherwise, the child refuses to connect.|
|
||||
| Yes|-/force/optional|Yes|yes|The parent-child stream is encrypted.|
|
||||
|
||||
### Streaming compression
|
||||
|
||||
[](https://github.com/netdata/netdata/releases/latest)
|
||||
|
|
@ -408,83 +279,147 @@ Same thing applies with the `[MACHINE_GUID]` configuration.
|
|||
[MACHINE_GUID]
|
||||
enable compression = yes | no
|
||||
```
|
||||
## Viewing remote host dashboards, using mirrored databases
|
||||
|
||||
On any receiving Netdata, that maintains remote databases and has its web server enabled,
|
||||
The node menu will include a list of the mirrored databases.
|
||||
### Securing streaming with TLS/SSL
|
||||
|
||||

|
||||
Netdata does not activate TLS encryption by default. To encrypt streaming connections, you first need to [enable TLS
|
||||
support](https://github.com/netdata/netdata/blob/master/web/server/README.md#enabling-tls-support) on the parent. With encryption enabled on the receiving side, you
|
||||
need to instruct the child to use TLS/SSL as well. On the child's `stream.conf`, configure the destination as follows:
|
||||
|
||||
Selecting any of these, the server will offer a dashboard using the mirrored metrics.
|
||||
```
|
||||
[stream]
|
||||
destination = host:port:SSL
|
||||
```
|
||||
|
||||
## Monitoring ephemeral nodes
|
||||
The word `SSL` appended to the end of the destination tells the child that connections must be encrypted.
|
||||
|
||||
Auto-scaling is probably the most trendy service deployment strategy these days.
|
||||
> While Netdata uses Transport Layer Security (TLS) 1.2 to encrypt communications rather than the obsolete SSL protocol,
|
||||
> it's still common practice to refer to encrypted web connections as `SSL`. Many vendors, like Nginx and even Netdata
|
||||
> itself, use `SSL` in configuration files, whereas documentation will always refer to encrypted communications as `TLS`
|
||||
> or `TLS/SSL`.
|
||||
|
||||
Auto-scaling detects the need for additional resources and boots VMs on demand, based on a template. Soon after they start running the applications, a load balancer starts distributing traffic to them, allowing the service to grow horizontally to the scale needed to handle the load. When demands falls, auto-scaling starts shutting down VMs that are no longer needed.
|
||||
#### Certificate verification
|
||||
|
||||

|
||||
When TLS/SSL is enabled on the child, the default behavior will be to not connect with the parent unless the server's
|
||||
certificate can be verified via the default chain. In case you want to avoid this check, add the following to the
|
||||
child's `stream.conf` file:
|
||||
|
||||
What a fantastic feature for controlling infrastructure costs! Pay only for what you need for the time you need it!
|
||||
```
|
||||
[stream]
|
||||
ssl skip certificate verification = yes
|
||||
```
|
||||
|
||||
In auto-scaling, all servers are ephemeral, they live for just a few hours. Every VM is a brand new instance of the application, that was automatically created based on a template.
|
||||
#### Trusted certificate
|
||||
|
||||
So, how can we monitor them? How can we be sure that everything is working as expected on all of them?
|
||||
If you've enabled [certificate verification](#certificate-verification), you might see errors from the OpenSSL library
|
||||
when there's a problem with checking the certificate chain (`X509_V_ERR_UNABLE_TO_GET_ISSUER_CERT_LOCALLY`). More
|
||||
importantly, OpenSSL will reject self-signed certificates.
|
||||
|
||||
### The Netdata way
|
||||
Given these known issues, you have two options. If you trust your certificate, you can set the options `CApath` and
|
||||
`CAfile` to inform Netdata where your certificates, and the certificate trusted file, are stored.
|
||||
|
||||
We recently made a significant improvement at the core of Netdata to support monitoring such setups.
|
||||
For more details about these options, you can read about [verify
|
||||
locations](https://www.openssl.org/docs/man1.1.1/man3/SSL_CTX_load_verify_locations.html).
|
||||
|
||||
Following the Netdata way of monitoring, we wanted:
|
||||
Before you changed your streaming configuration, you need to copy your trusted certificate to your child system and add
|
||||
the certificate to OpenSSL's list.
|
||||
|
||||
1. **real-time performance monitoring**, collecting ***thousands of metrics per server per second***, visualized in interactive, automatically created dashboards.
|
||||
2. **real-time alarms**, for all nodes.
|
||||
3. **zero configuration**, all ephemeral servers should have exactly the same configuration, and nothing should be configured at any system for each of the ephemeral nodes. We shouldn't care if 10 or 100 servers are spawned to handle the load.
|
||||
4. **self-cleanup**, so that nothing needs to be done for cleaning up the monitoring infrastructure from the hundreds of nodes that may have been monitored through time.
|
||||
On most Linux distributions, the `update-ca-certificates` command searches inside the `/usr/share/ca-certificates`
|
||||
directory for certificates. You should double-check by reading the `update-ca-certificate` manual (`man
|
||||
update-ca-certificate`), and then change the directory in the below commands if needed.
|
||||
|
||||
### How it works
|
||||
If you have `sudo` configured on your child system, you can use that to run the following commands. If not, you'll have
|
||||
to log in as `root` to complete them.
|
||||
|
||||
All monitoring solutions, including Netdata, work like this:
|
||||
```
|
||||
# mkdir /usr/share/ca-certificates/netdata
|
||||
# cp parent_cert.pem /usr/share/ca-certificates/netdata/parent_cert.crt
|
||||
# chown -R netdata.netdata /usr/share/ca-certificates/netdata/
|
||||
```
|
||||
|
||||
1. Collect metrics from the system and the running applications
|
||||
2. Store metrics in a time-series database
|
||||
3. Examine metrics periodically, for triggering alarms and sending alarm notifications
|
||||
4. Visualize metrics so that users can see what exactly is happening
|
||||
First, you create a new directory to store your certificates for Netdata. Next, you need to change the extension on your
|
||||
certificate from `.pem` to `.crt` so it's compatible with `update-ca-certificate`. Finally, you need to change
|
||||
permissions so the user that runs Netdata can access the directory where you copied in your certificate.
|
||||
|
||||
Netdata used to be self-contained, so that all these functions were handled entirely by each server. The changes we made, allow each Netdata to be configured independently for each function. So, each Netdata can now act as:
|
||||
Next, edit the file `/etc/ca-certificates.conf` and add the following line:
|
||||
|
||||
- A self-contained system, much like it used to be.
|
||||
- A data collector that collects metrics from a host and pushes them to another Netdata (with or without a local database and alarms).
|
||||
- A proxy, which receives metrics from other hosts and pushes them immediately to other Netdata servers. Netdata proxies can also be `store and forward proxies` meaning that they are able to maintain a local database for all metrics passing through them (with or without alarms).
|
||||
- A time-series database node, where data are kept, alarms are run and queries are served to visualise the metrics.
|
||||
```
|
||||
netdata/parent_cert.crt
|
||||
```
|
||||
|
||||
### Configuring an auto-scaling setup
|
||||
Now you update the list of certificates running the following, again either as `sudo` or `root`:
|
||||
|
||||

|
||||
```
|
||||
# update-ca-certificates
|
||||
```
|
||||
|
||||
You need a Netdata parent. This node should not be ephemeral. It will be the node where all ephemeral child
|
||||
nodes will send their metrics.
|
||||
> Some Linux distributions have different methods of updating the certificate list. For more details, please read this
|
||||
> guide on [adding trusted root certificates](https://github.com/Busindre/How-to-Add-trusted-root-certificates).
|
||||
|
||||
The parent will need to authorize child nodes to receive their metrics. This is done with an API key.
|
||||
Once you update your certificate list, you can set the stream parameters for Netdata to trust the parent certificate.
|
||||
Open `stream.conf` for editing and change the following lines:
|
||||
|
||||
#### API keys
|
||||
```
|
||||
[stream]
|
||||
CApath = /etc/ssl/certs/
|
||||
CAfile = /etc/ssl/certs/parent_cert.pem
|
||||
```
|
||||
|
||||
API keys are just random GUIDs. Use the Linux command `uuidgen` to generate one. You can use the same API key for all your child nodes, or you can configure one API for each of them. This is entirely your decision.
|
||||
With this configuration, the `CApath` option tells Netdata to search for trusted certificates inside `/etc/ssl/certs`.
|
||||
The `CAfile` option specifies the Netdata parent certificate is located at `/etc/ssl/certs/parent_cert.pem`. With this
|
||||
configuration, you can skip using the system's entire list of certificates and use Netdata's parent certificate instead.
|
||||
|
||||
We suggest to use the same API key for each ephemeral node template you have, so that all replicas of the same ephemeral node will have exactly the same configuration.
|
||||
#### Expected behaviors
|
||||
|
||||
I will use this API_KEY: `11111111-2222-3333-4444-555555555555`. Replace it with your own.
|
||||
With the introduction of TLS/SSL, the parent-child communication behaves as shown in the table below, depending on the
|
||||
following configurations:
|
||||
|
||||
#### Configuring the parent
|
||||
- **Parent TLS (Yes/No)**: Whether the `[web]` section in `netdata.conf` has `ssl key` and `ssl certificate`.
|
||||
- **Parent port TLS (-/force/optional)**: Depends on whether the `[web]` section `bind to` contains a `^SSL=force` or
|
||||
`^SSL=optional` directive on the port(s) used for streaming.
|
||||
- **Child TLS (Yes/No)**: Whether the destination in the child's `stream.conf` has `:SSL` at the end.
|
||||
- **Child TLS Verification (yes/no)**: Value of the child's `stream.conf` `ssl skip certificate verification`
|
||||
parameter (default is no).
|
||||
|
||||
To configure the parent node:
|
||||
| Parent TLS enabled | Parent port SSL | Child TLS | Child SSL Ver. | Behavior |
|
||||
| :----------------- | :--------------- | :-------- | :------------- | :--------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| No | - | No | no | Legacy behavior. The parent-child stream is unencrypted. |
|
||||
| Yes | force | No | no | The parent rejects the child connection. |
|
||||
| Yes | -/optional | No | no | The parent-child stream is unencrypted (expected situation for legacy child nodes and newer parent nodes) |
|
||||
| Yes | -/force/optional | Yes | no | The parent-child stream is encrypted, provided that the parent has a valid TLS/SSL certificate. Otherwise, the child refuses to connect. |
|
||||
| Yes | -/force/optional | Yes | yes | The parent-child stream is encrypted. |
|
||||
|
||||
1. On the parent node, edit `stream.conf` by using the `edit-config` script:
|
||||
`/etc/netdata/edit-config stream.conf`
|
||||
### Proxy
|
||||
|
||||
2. Set the following parameters:
|
||||
A proxy is a node that receives metrics from a child, then streams them onward to a parent. To configure a proxy,
|
||||
configure it as a receiving and a sending Netdata at the same time.
|
||||
|
||||
```bash
|
||||
Netdata proxies may or may not maintain a database for the metrics passing through them. When they maintain a database,
|
||||
they can also run health checks (alarms and notifications) for the remote host that is streaming the metrics.
|
||||
|
||||
In the following example, the proxy receives metrics from a child node using the `API_KEY` of
|
||||
`66666666-7777-8888-9999-000000000000`, then stores metrics using `dbengine`. It then uses the `API_KEY` of
|
||||
`11111111-2222-3333-4444-555555555555` to proxy those same metrics on to a parent node at `203.0.113.0`.
|
||||
|
||||
```conf
|
||||
[stream]
|
||||
enabled = yes
|
||||
destination = 203.0.113.0
|
||||
api key = 11111111-2222-3333-4444-555555555555
|
||||
|
||||
[66666666-7777-8888-9999-000000000000]
|
||||
enabled = yes
|
||||
default memory mode = dbengine
|
||||
```
|
||||
|
||||
### Ephemeral nodes
|
||||
|
||||
Netdata can help you monitor ephemeral nodes, such as containers in an auto-scaling infrastructure, by always streaming
|
||||
metrics to any number of permanently-running parent nodes.
|
||||
|
||||
On the parent, set the following in `stream.conf`:
|
||||
|
||||
```conf
|
||||
[11111111-2222-3333-4444-555555555555]
|
||||
# enable/disable this API key
|
||||
enabled = yes
|
||||
|
|
@ -499,24 +434,7 @@ To configure the parent node:
|
|||
health enabled by default = auto
|
||||
```
|
||||
|
||||
_`stream.conf` on the parent, to enable receiving metrics from its child nodes using the API key._
|
||||
|
||||
If you used many API keys, you can add one such section for each API key.
|
||||
|
||||
When done, restart Netdata on the parent node. It is now ready to receive metrics.
|
||||
|
||||
Note that `health enabled by default = auto` will still trigger `last_collected` alarms, if a connected child does not exit gracefully. If the `netdata` process running on the child is
|
||||
stopped, it will close the connection to the parent, ensuring that no `last_collected` alarms are triggered. For example, a proper container restart would first terminate
|
||||
the `netdata` process, but a system power issue would leave the connection open on the parent side. In the second case, you will still receive alarms.
|
||||
|
||||
#### Configuring the child nodes
|
||||
|
||||
To configure the child node:
|
||||
|
||||
1. On the child node, edit `stream.conf` by using the `edit-config` script:
|
||||
`/etc/netdata/edit-config stream.conf`
|
||||
|
||||
2. Set the following parameters:
|
||||
On the child nodes, set the following in `stream.conf`:
|
||||
|
||||
```bash
|
||||
[stream]
|
||||
|
|
@ -526,44 +444,26 @@ To configure the child node:
|
|||
# the IP and PORT of the parent
|
||||
destination = 10.11.12.13:19999
|
||||
|
||||
# the API key to use
|
||||
# the API key to use
|
||||
api key = 11111111-2222-3333-4444-555555555555
|
||||
```
|
||||
|
||||
_`stream.conf` on child nodes, to enable pushing metrics to their parent at `10.11.12.13:19999`._
|
||||
|
||||
Using just the above configuration, the child nodes will be pushing their metrics to the parent Netdata, but they will still maintain a local database of the metrics and run health checks. To disable them, edit `/etc/netdata/netdata.conf` and set:
|
||||
In addition, edit `netdata.conf` on each child node to disable the database and alarms.
|
||||
|
||||
```bash
|
||||
[global]
|
||||
# disable the local database
|
||||
memory mode = none
|
||||
memory mode = none
|
||||
|
||||
[health]
|
||||
# disable health checks
|
||||
enabled = no
|
||||
```
|
||||
|
||||
_`netdata.conf` configuration on child nodes, to disable the local database and health checks._
|
||||
|
||||
Keep in mind that setting `memory mode = none` will also force `[health].enabled = no` (health checks require access to a local database). But you can keep the database and disable health checks if you need to. You are however sending all the metrics to the parent node, which can handle the health checking (`[health].enabled = yes`)
|
||||
|
||||
#### Netdata unique ID
|
||||
|
||||
The file `/var/lib/netdata/registry/netdata.public.unique.id` contains a random GUID that **uniquely identifies each Netdata Agent**. This file is automatically generated, by Netdata, the first time it is started and remains unaltered forever.
|
||||
|
||||
> If you are building an image to be used for automated provisioning of autoscaled VMs, it important to delete that file from the image, so that each instance of your image will generate its own.
|
||||
|
||||
#### Troubleshooting metrics streaming
|
||||
## Troubleshooting
|
||||
|
||||
Both parent and child nodes log information at `/var/log/netdata/error.log`.
|
||||
|
||||
To obtain the error logs, run the following on both the parent and child nodes:
|
||||
|
||||
```
|
||||
tail -f /var/log/netdata/error.log | grep STREAM
|
||||
```
|
||||
|
||||
If the child manages to connect to the parent you will see something like (on the parent):
|
||||
|
||||
```
|
||||
|
|
@ -583,53 +483,7 @@ and something like this on the child:
|
|||
2017-03-09 09:38:28: netdata: INFO : STREAM xxx [send to box:19999]: established communication - sending metrics...
|
||||
```
|
||||
|
||||
### Archiving to a time-series database
|
||||
|
||||
The parent Netdata node can also archive metrics, for all its child nodes, to a time-series database. At the time of
|
||||
this writing, Netdata supports:
|
||||
|
||||
- graphite
|
||||
- opentsdb
|
||||
- prometheus
|
||||
- json document DBs
|
||||
- all the compatibles to the above (e.g. kairosdb, influxdb, etc)
|
||||
|
||||
Check the Netdata [exporting documentation](https://github.com/netdata/netdata/blob/master/docs/export/external-databases.md) for configuring this.
|
||||
|
||||
This is how such a solution will work:
|
||||
|
||||

|
||||
|
||||
### An advanced setup
|
||||
|
||||
Netdata also supports `proxies` with and without a local database, and data retention can be different between all nodes.
|
||||
|
||||
This means a setup like the following is also possible:
|
||||
|
||||
<p align="center">
|
||||
<img src="https://cloud.githubusercontent.com/assets/2662304/23629551/bb1fd9c2-02c0-11e7-90f5-cab5a3ed4c53.png"/>
|
||||
</p>
|
||||
|
||||
## Proxies
|
||||
|
||||
A proxy is a Netdata node that is receiving metrics from a Netdata node, and streams them to another Netdata node.
|
||||
|
||||
Netdata proxies may or may not maintain a database for the metrics passing through them.
|
||||
When they maintain a database, they can also run health checks (alarms and notifications)
|
||||
for the remote host that is streaming the metrics.
|
||||
|
||||
To configure a proxy, configure it as a receiving and a sending Netdata at the same time,
|
||||
using `stream.conf`.
|
||||
|
||||
The sending side of a Netdata proxy, connects and disconnects to the final destination of the
|
||||
metrics, following the same pattern of the receiving side.
|
||||
|
||||
For a practical example see [Monitoring ephemeral nodes](#monitoring-ephemeral-nodes).
|
||||
|
||||
## Troubleshooting streaming connections
|
||||
|
||||
This section describes the most common issues you might encounter when connecting parent and child nodes.
|
||||
The following sections describe the most common issues you might encounter when connecting parent and child nodes.
|
||||
|
||||
### Slow connections between parent and child
|
||||
|
||||
|
|
@ -647,8 +501,8 @@ On the parent side, you may see various error messages, most commonly the follow
|
|||
netdata ERROR : STREAM_PARENT[CHILD HOSTNAME,[CHILD IP]:CHILD PORT] : read failed: end of file
|
||||
```
|
||||
|
||||
Another common problem in slow connections is the CHILD sending a partial message to the parent. In this case,
|
||||
the parent will write the following in its `error.log`:
|
||||
Another common problem in slow connections is the child sending a partial message to the parent. In this case, the
|
||||
parent will write the following to its `error.log`:
|
||||
|
||||
```
|
||||
ERROR : STREAM_RECEIVER[CHILD HOSTNAME,[CHILD IP]:CHILD PORT] : sent command 'B' which is not known by netdata, for host 'HOSTNAME'. Disabling it.
|
||||
|
|
@ -673,11 +527,11 @@ down), you will see the following in the child's `error.log`.
|
|||
ERROR : STREAM_SENDER[HOSTNAME] : Failed to connect to 'PARENT IP', port 'PARENT PORT' (errno 113, No route to host)
|
||||
```
|
||||
|
||||
### 'Is this a Netdata node?'
|
||||
### 'Is this a Netdata?'
|
||||
|
||||
This question can appear when Netdata starts the stream and receives an unexpected response. This error can appear when
|
||||
the parent is using SSL and the child tries to connect using plain text. You will also see this message when
|
||||
Netdata connects to another server that isn't a Netdata node. The complete error message will look like this:
|
||||
Netdata connects to another server that isn't Netdata. The complete error message will look like this:
|
||||
|
||||
```
|
||||
ERROR : STREAM_SENDER[CHILD HOSTNAME] : STREAM child HOSTNAME [send to PARENT HOSTNAME:PARENT PORT]: server is not replying properly (is it a netdata?).
|
||||
|
|
@ -702,15 +556,15 @@ STREAM [receive from [child HOSTNAME]:child IP]: `MESSAGE`. Forbidding access."
|
|||
|
||||
`MESSAGE` will have one of the following patterns:
|
||||
|
||||
- `request without KEY` : The message received is incomplete and the KEY value can be API, hostname, machine GUID.
|
||||
- `API key 'VALUE' is not valid GUID`: The UUID received from child does not have the format defined in [RFC 4122]
|
||||
(https://tools.ietf.org/html/rfc4122)
|
||||
- `machine GUID 'VALUE' is not GUID.`: This error with machine GUID is like the previous one.
|
||||
- `API key 'VALUE' is not allowed`: This stream has a wrong API key.
|
||||
- `API key 'VALUE' is not permitted from this IP`: The IP is not allowed to use STREAM with this parent.
|
||||
- `machine GUID 'VALUE' is not allowed.`: The GUID that is trying to send stream is not allowed.
|
||||
- `Machine GUID 'VALUE' is not permitted from this IP. `: The IP does not match the pattern or IP allowed to connect
|
||||
to use stream.
|
||||
- `request without KEY` : The message received is incomplete and the KEY value can be API, hostname, machine GUID.
|
||||
- `API key 'VALUE' is not valid GUID`: The UUID received from child does not have the format defined in [RFC
|
||||
4122](https://tools.ietf.org/html/rfc4122)
|
||||
- `machine GUID 'VALUE' is not GUID.`: This error with machine GUID is like the previous one.
|
||||
- `API key 'VALUE' is not allowed`: This stream has a wrong API key.
|
||||
- `API key 'VALUE' is not permitted from this IP`: The IP is not allowed to use STREAM with this parent.
|
||||
- `machine GUID 'VALUE' is not allowed.`: The GUID that is trying to send stream is not allowed.
|
||||
- `Machine GUID 'VALUE' is not permitted from this IP. `: The IP does not match the pattern or IP allowed to connect to
|
||||
use stream.
|
||||
|
||||
### Netdata could not create a stream
|
||||
|
||||
|
|
@ -722,5 +576,3 @@ file descriptor given is not a valid stream
|
|||
```
|
||||
|
||||
After logging this error, Netdata will close the stream.
|
||||
|
||||
|
||||
|
|
|
|||
196
web/README.md
196
web/README.md
|
|
@ -1,14 +1,4 @@
|
|||
<!--
|
||||
title: "Dashboards"
|
||||
description: "Every Netdata Agent comes bundled with hundreds of interactive, customizable charts designed by monitoring and troubleshooting experts."
|
||||
custom_edit_url: https://github.com/netdata/netdata/edit/master/web/README.md
|
||||
sidebar_label: "Dashboards"
|
||||
learn_status: "Published"
|
||||
learn_topic_type: "References"
|
||||
learn_rel_path: "Developers/Web"
|
||||
-->
|
||||
|
||||
# Dashboards
|
||||
# Agent Dashboards
|
||||
|
||||
Because Netdata is a health monitoring and _performance troubleshooting_ system,
|
||||
we put a lot of emphasis on real-time, meaningful, and context-aware charts.
|
||||
|
|
@ -16,7 +6,7 @@ we put a lot of emphasis on real-time, meaningful, and context-aware charts.
|
|||
We bundle Netdata with a dashboard and hundreds of charts, designed by both our
|
||||
team and the community, but you can also customize them yourself.
|
||||
|
||||
There are two primary ways to view Netdata's dashboards:
|
||||
There are two primary ways to view Netdata's dashboards on the agent:
|
||||
|
||||
1. The [local Agent dashboard](https://github.com/netdata/netdata/blob/master/web/gui/README.md) that comes pre-configured with every Netdata installation. You can
|
||||
see it at `http://NODE:19999`, replacing `NODE` with `localhost`, the hostname of your node, or its IP address. You
|
||||
|
|
@ -30,188 +20,6 @@ There are two primary ways to view Netdata's dashboards:
|
|||
|
||||
You can also view all the data Netdata collects through the [REST API v1](https://github.com/netdata/netdata/blob/master/web/api/README.md#netdata-rest-api).
|
||||
|
||||
No matter where you use Netdata's charts, you'll want to know how to [use](#using-charts) them. You'll also want to
|
||||
understand how Netdata defines [charts](#charts), [dimensions](#dimensions), [families](#families), and
|
||||
[contexts](#contexts).
|
||||
|
||||
## Using charts
|
||||
|
||||
Netdata's charts are far from static. They are interactive, real-time, and work
|
||||
with your mouse, touchpad, or touchscreen!
|
||||
|
||||
Hover over any chart to temporarily pause it and see the exact values presented
|
||||
as different [dimensions](#dimensions). Click or tap stop the chart from automatically updating with new metrics, thereby locking it to a single timeframe.
|
||||
|
||||
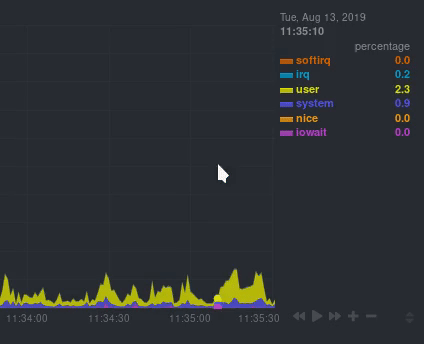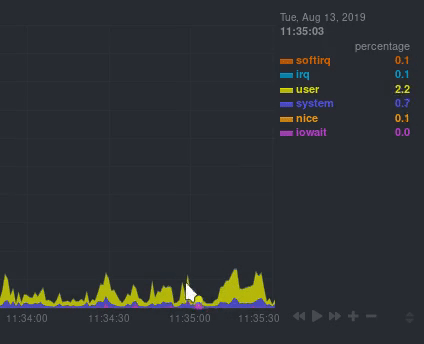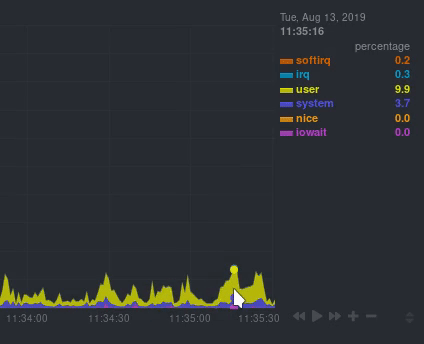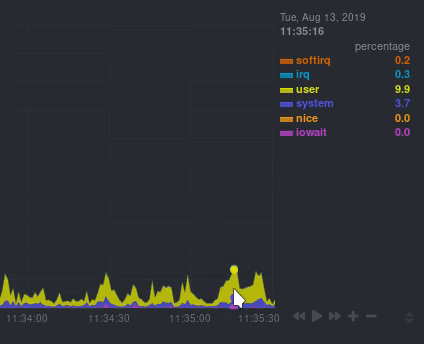
|
||||
|
||||
You can change how charts show their metrics by zooming in or out, moving
|
||||
forward or backward in time, or selecting a specific timeframe for more in-depth
|
||||
analysis.
|
||||
|
||||
Whenever you use a chart in this way, Netdata synchronizes all the other charts
|
||||
to match it.
|
||||
|
||||
You can change how charts show their metrics in a few different ways, each of
|
||||
which have a few methods:
|
||||
|
||||
| Manipulation | Method #1 | Method #2 | Method #3 |
|
||||
|--- |--- |--- |--- |
|
||||
| **Reset** charts to default auto-refreshing state | `double click` | `double tap` (touchpad/touchscreen) | |
|
||||
| **Select** a certain timeframe | `ALT` + `mouse selection` | `⌘` + `mouse selection` (macOS) | |
|
||||
| **Pan** forward or back in time | `click and drag` | `touch and drag` (touchpad/touchscreen) | |
|
||||
| **Zoom** to a specific timeframe | `SHIFT` + `mouse selection` | | |
|
||||
| **Zoom** in/out | `SHIFT`/`ALT` + `mouse scrollwheel` | `SHIFT`/`ALT` + `two-finger pinch` (touchpad/touchscreen) | `SHIFT`/`ALT` + `two-finger scroll` (touchpad/touchscreen) |
|
||||
|
||||
Here's how chart synchronization looks while zooming and panning:
|
||||
|
||||

|
||||
|
||||
You can also perform all these actions using the small
|
||||
rewind/play/fast-forward/zoom-in/zoom-out buttons that appear in the
|
||||
bottom-right corner of each chart.
|
||||
|
||||
Additionally, resize charts by clicking-and-dragging the icon on the bottom-right corner of any chart. To restore the
|
||||
chart to its original height, double-click the same icon.
|
||||
|
||||
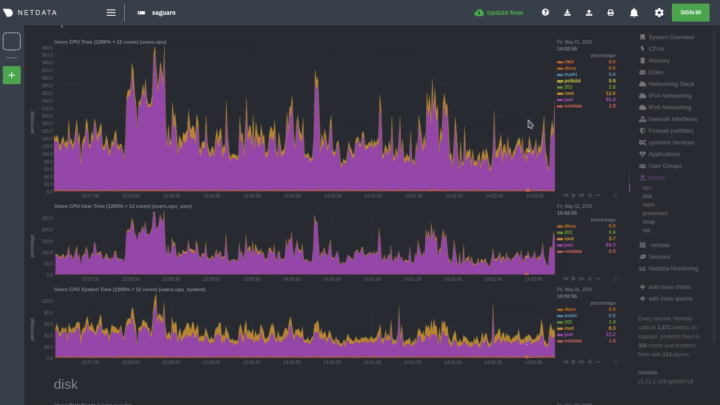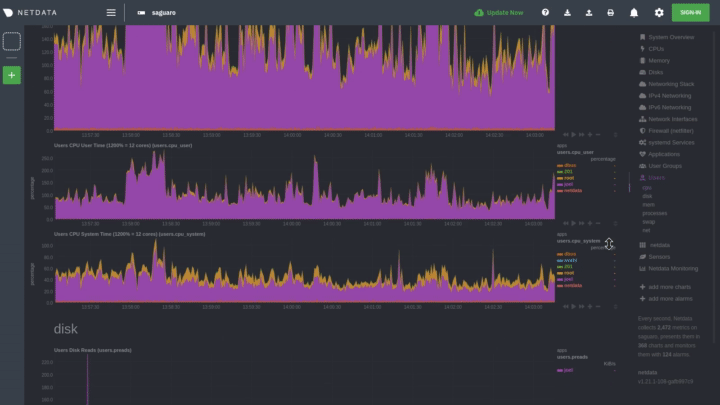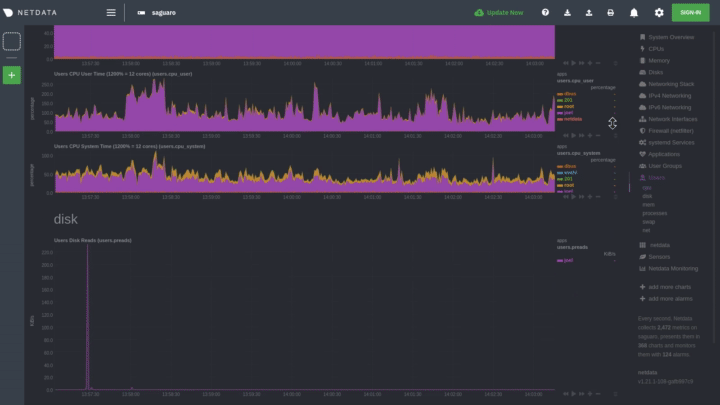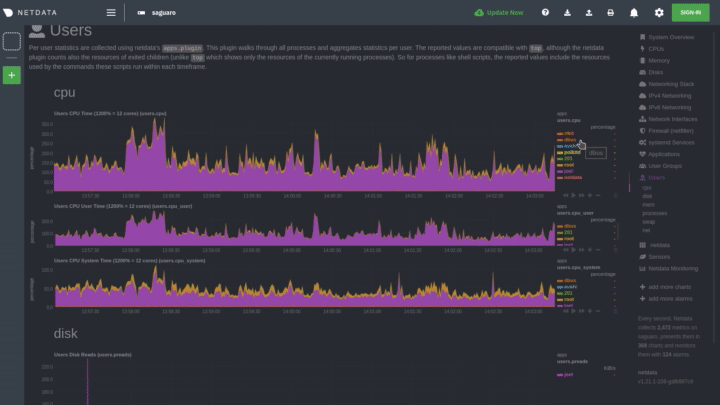
|
||||
|
||||
## Charts, contexts, families
|
||||
|
||||
Before customizing the standard web dashboard, creating a custom dashboard,
|
||||
configuring an alarm, or writing a collector, it's crucial to understand how
|
||||
Netdata organizes metrics into charts, dimensions, families, and contexts.
|
||||
|
||||
### Charts
|
||||
|
||||
A **chart** is an individual, interactive, always-updating graphic displaying
|
||||
one or more collected/calculated metrics. Charts are generated by
|
||||
[collectors](https://github.com/netdata/netdata/blob/master/collectors/README.md).
|
||||
|
||||
Here's the system CPU chart, the first chart displayed on the standard
|
||||
dashboard:
|
||||
|
||||
|
||||
|
||||
Netdata displays a chart's name in parentheses above the chart. For example, if
|
||||
you navigate to the system CPU chart, you'll see the label: **Total CPU
|
||||
utilization (system.cpu)**. In this case, the chart's name is `system.cpu`.
|
||||
Netdata derives the name from the chart's [context](#contexts).
|
||||
|
||||
### Dimensions
|
||||
|
||||
A **dimension** is a value that gets shown on a chart. The value can be raw data
|
||||
or calculated values, such as percentages, aggregates, and more.
|
||||
|
||||
Charts are capable of showing more than one dimension. Netdata shows these
|
||||
dimensions on the right side of the chart, beneath the date and time. Again, the
|
||||
`system.cpu` chart will serve as a good example.
|
||||
|
||||
|
||||
|
||||
Here, the `system.cpu` chart is showing many dimensions, such as `user`,
|
||||
`system`, `softirq`, `irq`, and more.
|
||||
|
||||
Note that other applications sometimes use the word _series_ instead of
|
||||
_dimension_.
|
||||
|
||||
### Families
|
||||
|
||||
A **family** is _one_ instance of a monitored hardware or software resource that
|
||||
needs to be monitored and displayed separately from similar instances.
|
||||
|
||||
For example, if your system has multiple disk drives at `sda` and `sdb`, Netdata
|
||||
will put each interface into their own family. Same goes for software resources,
|
||||
like multiple MySQL instances. We call these instances "families" because the
|
||||
charts associated with a single disk instance, for example, are often related to
|
||||
each other. Relatives, family... get it?
|
||||
|
||||
When relevant, Netdata prefers to organize charts by family. When you visit the
|
||||
**Disks** section, you will see your disk drives organized into families, and
|
||||
each family will have one or more charts: `disk`, `disk_ops`, `disk_backlog`,
|
||||
`disk_util`, `disk_await`, `disk_avgsz`, `disk_svctm`, `disk_mops`, and
|
||||
`disk_iotime`.
|
||||
|
||||
In the screenshot below, the disk family `sdb` shows a few gauges, followed by a
|
||||
few of the associated charts:
|
||||
|
||||
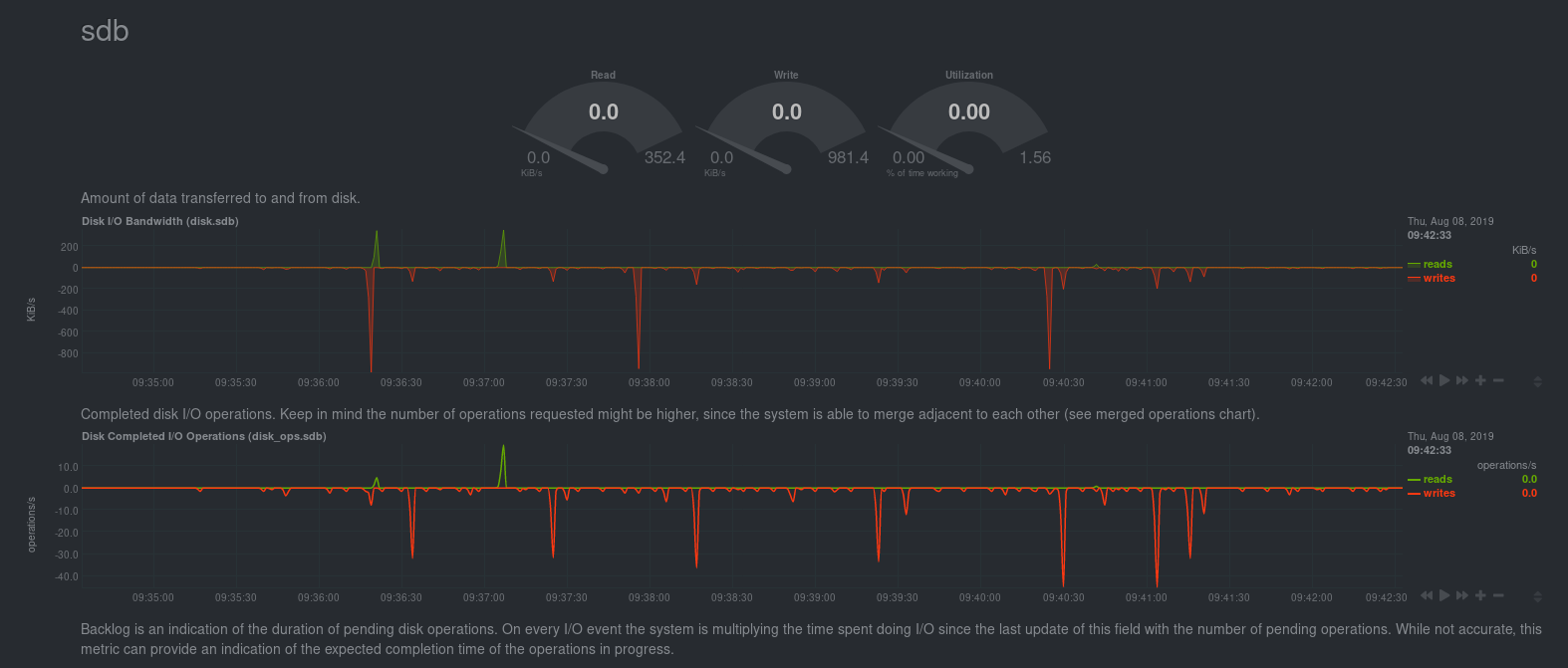
|
||||
|
||||
Netdata also creates separate submenu entries for each family in the right
|
||||
navigation page so you can easily navigate to the instance you're interested in.
|
||||
Here, Netdata has made several submenus under the **Disk** menu.
|
||||
|
||||
|
||||
|
||||
### Contexts
|
||||
|
||||
A **context** is a way of grouping charts by the types of metrics collected and
|
||||
dimensions displayed. Different charts with the same context will show the same
|
||||
dimensions, but for different instances (families) of hardware/software
|
||||
resources.
|
||||
|
||||
For example, the **Disks** section will often use many contexts (`disk.io`,
|
||||
`disk.ops`, `disk.backlog`, `disk.util`, and so on). Netdata then creates an
|
||||
individual chart for each context, and groups them by family.
|
||||
|
||||
Netdata names charts according to their context according to the following
|
||||
structure: `[context].[family]`. A chart with the `disk.util` context, in the
|
||||
`sdb` family, gets the name `disk_util.sdb`. Netdata shows that name in the
|
||||
top-left corner of a chart.
|
||||
|
||||
Given the four example contexts, and two families of `sdb` and `sdd`, Netdata
|
||||
will create the following charts and their names:
|
||||
|
||||
| Context | `sdb` family | `sdd` family |
|
||||
|----------------|--------------------|--------------------|
|
||||
| `disk.io` | `disk_io.sdb` | `disk_io.sdd` |
|
||||
| `disk.ops` | `disk_ops.sdb` | `disk_ops.sdd` |
|
||||
| `disk.backlog` | `disk_backlog.sdb` | `disk_backlog.sdd` |
|
||||
| `disk.util` | `disk_util.sdb` | `disk_util.sdd` |
|
||||
|
||||
And here's what two of those charts in the `disk.io` context look like under
|
||||
`sdb` and `sdd` families:
|
||||
|
||||

|
||||

|
||||
|
||||
As you can see in the screenshot, you can view the context of a chart if you
|
||||
hover over the date above the list of dimensions. A tooltip will appear that
|
||||
shows you two pieces of information: the collector that produces the chart, and
|
||||
the chart's context.
|
||||
|
||||
Netdata also uses [contexts for alarm templates](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alarm-line-on). You can create an alarm for the
|
||||
`net.packets` context to receive alerts for any chart with that context, no matter which family it's attached to.
|
||||
|
||||
## Positive and negative values on charts
|
||||
|
||||
To improve clarity on charts, Netdata dashboards present **positive** values for
|
||||
metrics representing `read`, `input`, `inbound`, `received` and **negative**
|
||||
values for metrics representing `write`, `output`, `outbound`, `sent`.
|
||||
|
||||
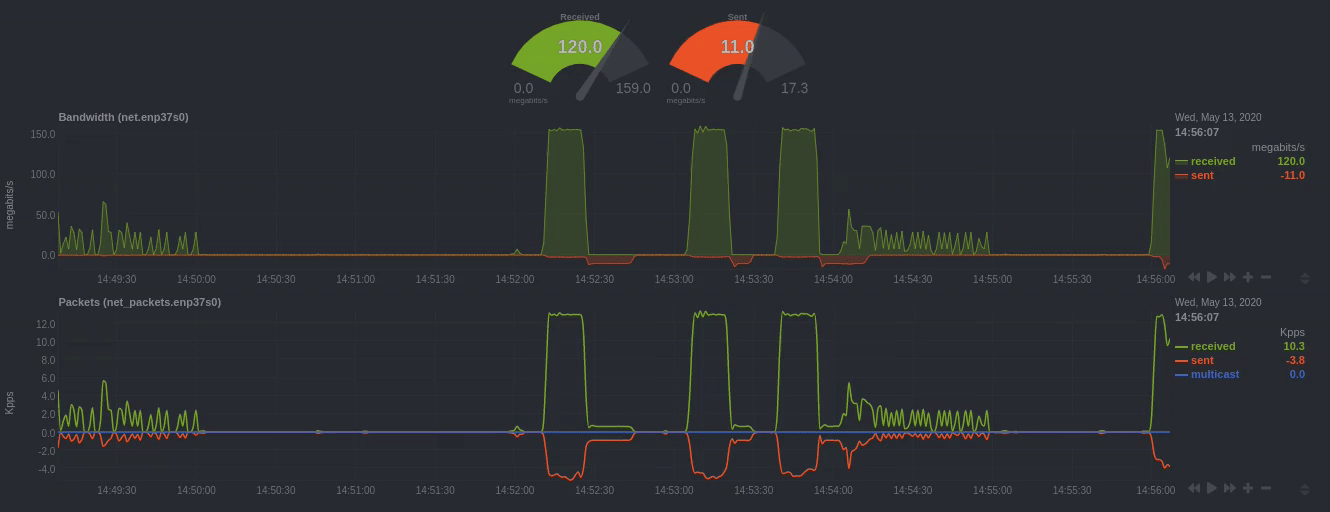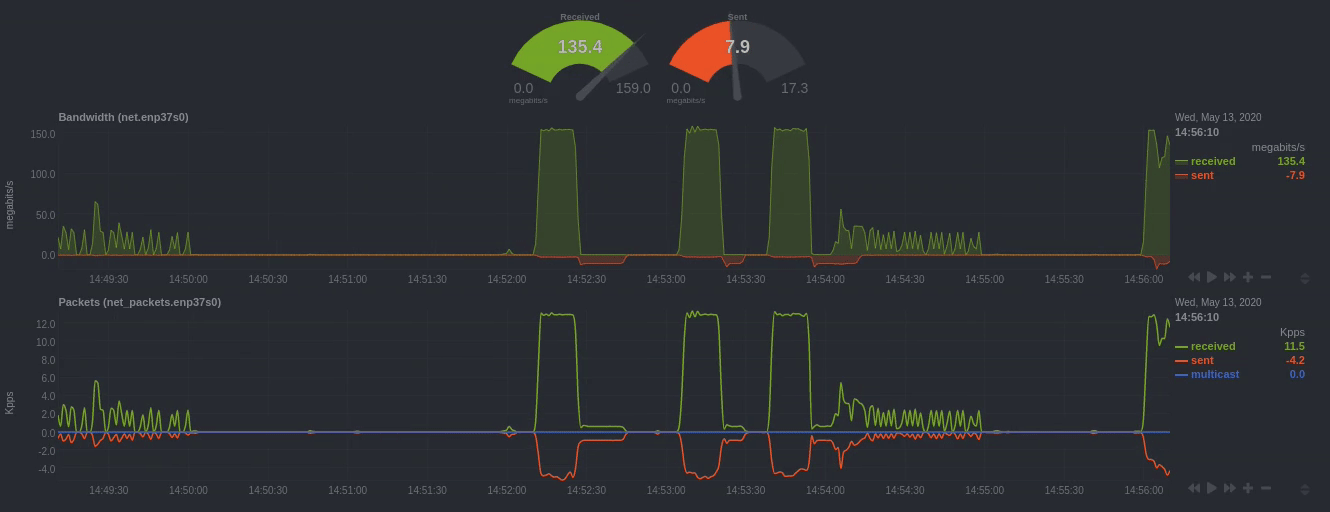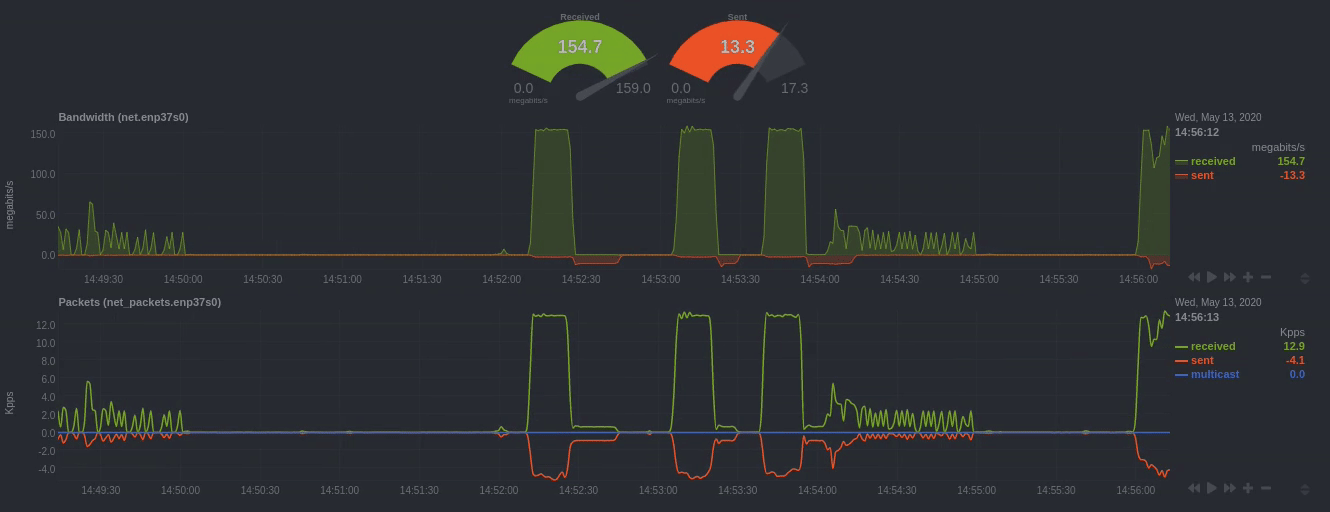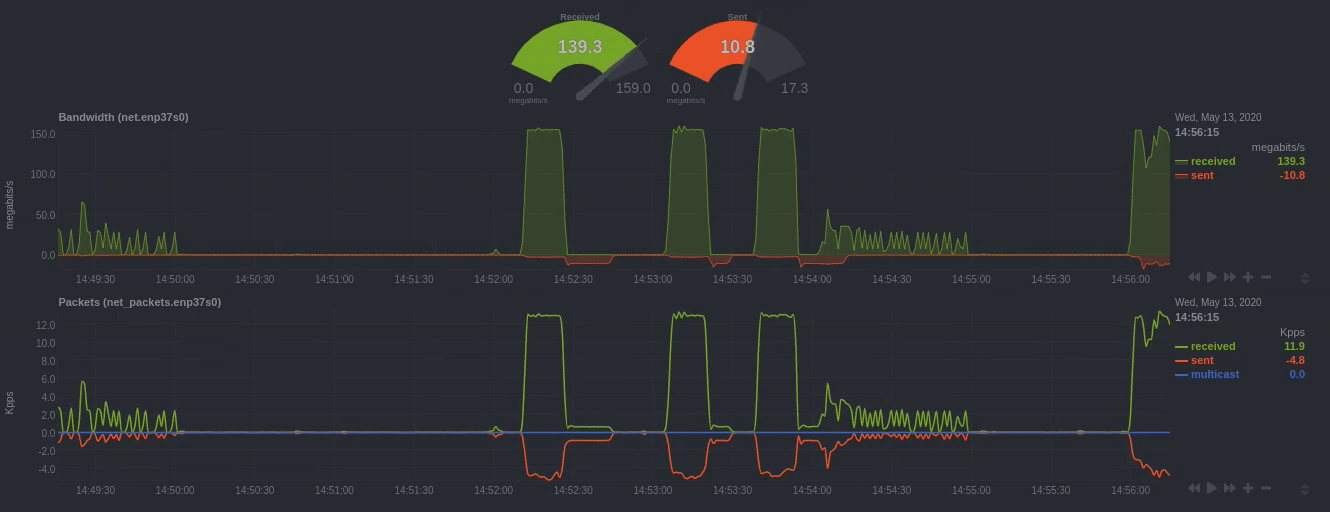
|
||||
|
||||
_Netdata charts showing the bandwidth and packets of a network interface.
|
||||
`received` is positive and `sent` is negative._
|
||||
|
||||
## Autoscaled y-axis
|
||||
|
||||
Netdata charts automatically zoom vertically, to visualize the variation of each
|
||||
metric within the visible timeframe.
|
||||
|
||||
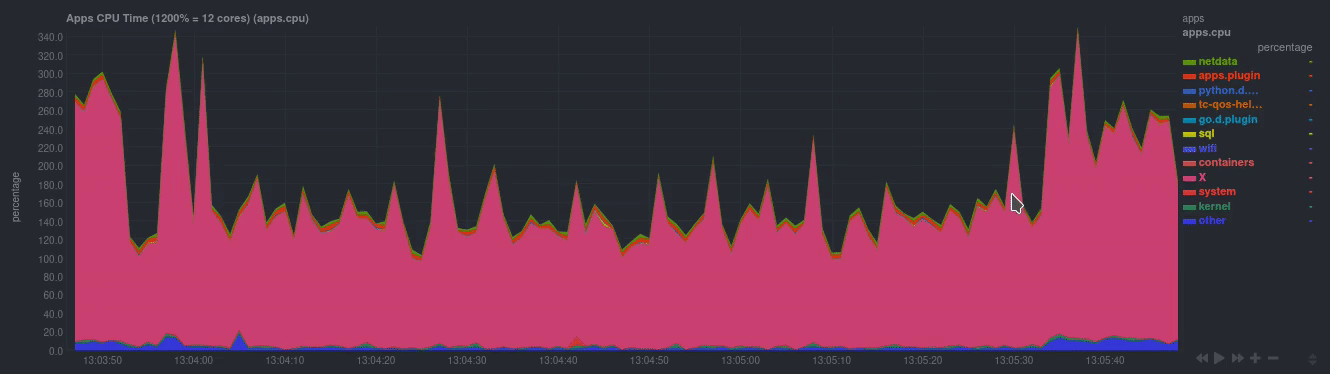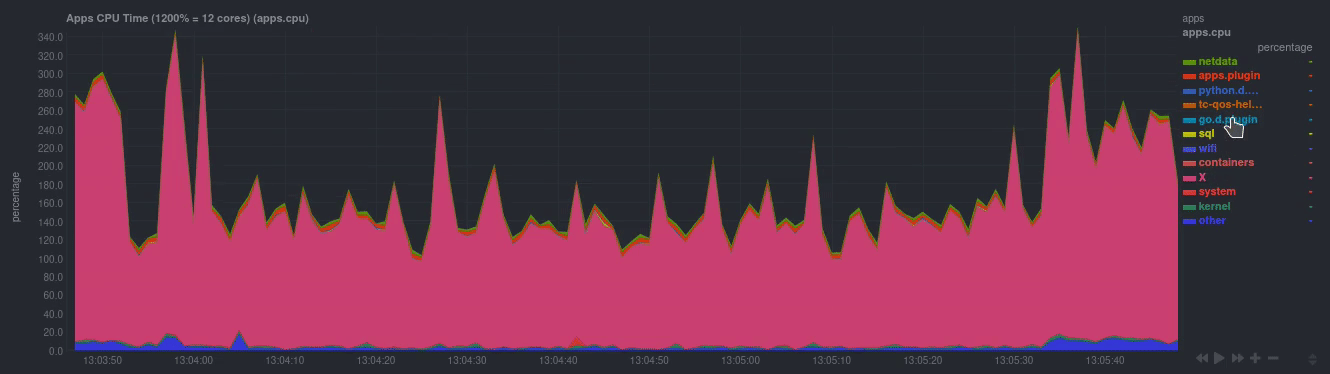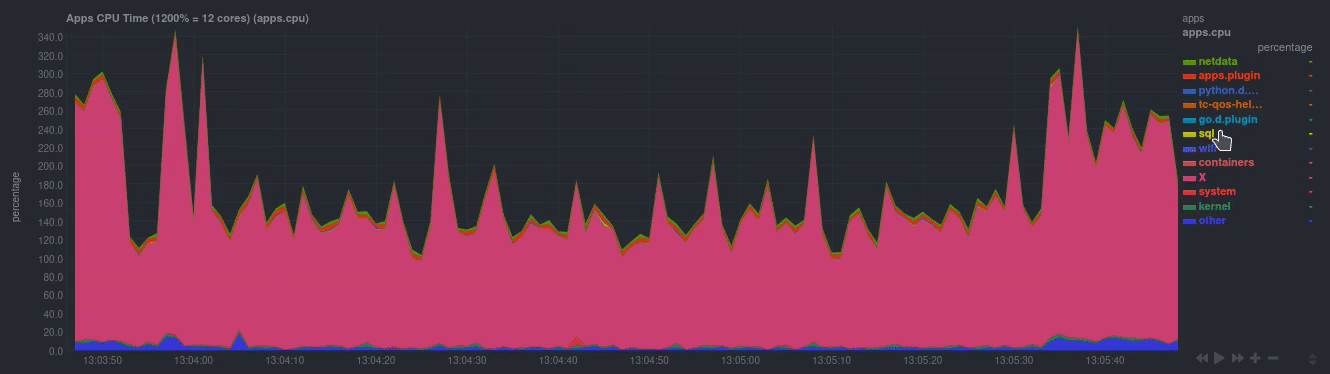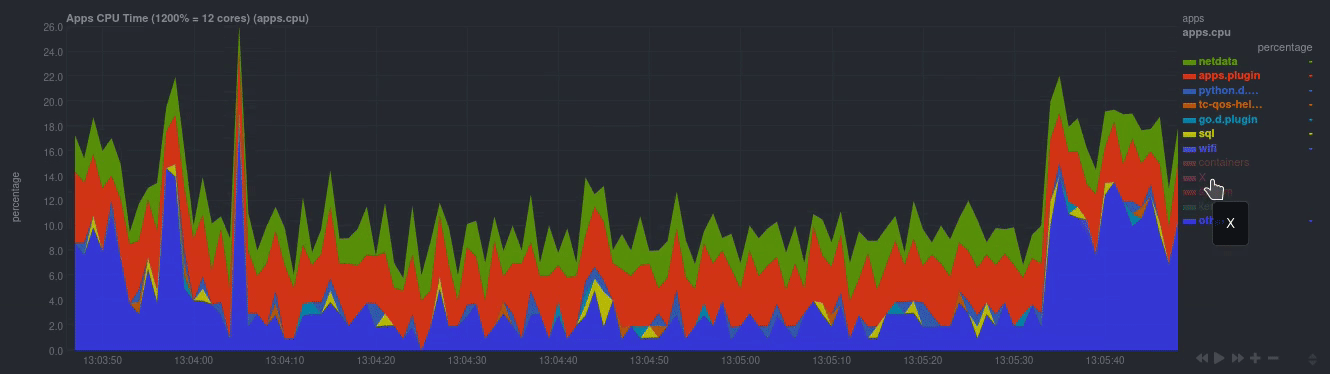
|
||||
|
||||
_A zero-based `stacked` chart, automatically switches to an auto-scaled `area`
|
||||
chart when a single dimension is selected._
|
||||
|
||||
## dashboard.js
|
||||
|
||||
Netdata uses the `dashboards.js` file to define, configure, create, and update
|
||||
|
|
|
|||
Loading…
Add table
Reference in a new issue