mirror of
https://github.com/netdata/netdata.git
synced 2025-04-07 06:45:39 +00:00
docs rename alarm to alert (#15812)
This commit is contained in:
parent
4040a16ba2
commit
d5bdb7cf15
75 changed files with 704 additions and 711 deletions
collectors
daemon/config
docs
category-overview-pages
cloud
collect
configure
contributing
dashboard
getting-started
glossary.mdguides
collect-apache-nginx-web-logs.mdmonitor-cockroachdb.mdmonitor-hadoop-cluster.md
monitor
python-collector.mdusing-host-labels.mdmetrics-storage-management
monitor
quickstart
store
exporting
health
ml
packaging/installer
streaming
web
|
|
@ -581,9 +581,9 @@ collectors are described only in code and associated charts in Netdata dashboard
|
|||
- [ACLK (code only)](https://github.com/netdata/netdata/blob/master/aclk/legacy/aclk_stats.c): View whether a Netdata
|
||||
Agent is connected to Netdata Cloud via the [ACLK](https://github.com/netdata/netdata/blob/master/aclk/README.md), the
|
||||
volume of queries, process times, and more.
|
||||
- [Alarms](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/alarms/README.md): This collector
|
||||
- [Alerts](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/alarms/README.md): This collector
|
||||
creates an
|
||||
**Alarms** menu with one line plot showing the alarm states of a Netdata Agent over time.
|
||||
**Alerts** menu with one line plot showing the alert states of a Netdata Agent over time.
|
||||
- [Anomalies](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/anomalies/README.md): This
|
||||
collector uses the
|
||||
Python PyOD library to perform unsupervised anomaly detection on your Netdata charts and/or dimensions.
|
||||
|
|
|
|||
|
|
@ -139,10 +139,10 @@ chart instead of `auto` to enable it permanently. For example:
|
|||
You can also set the `enable zero metrics` option to `yes` in the `[global]` section which enables charts with zero
|
||||
metrics for all internal Netdata plugins.
|
||||
|
||||
### Alarms
|
||||
### Alerts
|
||||
|
||||
CPU and memory limits are watched and used to rise alarms. Memory usage for every cgroup is checked against `ram`
|
||||
and `ram+swap` limits. CPU usage for every cgroup is checked against `cpuset.cpus` and `cpu.cfs_period_us` + `cpu.cfs_quota_us` pair assigned for the cgroup. Configuration for the alarms is available in `health.d/cgroups.conf`
|
||||
CPU and memory limits are watched and used to rise alerts. Memory usage for every cgroup is checked against `ram`
|
||||
and `ram+swap` limits. CPU usage for every cgroup is checked against `cpuset.cpus` and `cpu.cfs_period_us` + `cpu.cfs_quota_us` pair assigned for the cgroup. Configuration for the alerts is available in `health.d/cgroups.conf`
|
||||
file.
|
||||
|
||||
## Monitoring systemd services
|
||||
|
|
@ -264,7 +264,7 @@ Network interfaces and cgroups (containers) are self-cleaned. When a network int
|
|||
a few errors in error.log complaining about files it cannot find, but immediately:
|
||||
|
||||
1. It will detect this is a removed container or network interface
|
||||
2. It will freeze/pause all alarms for them
|
||||
2. It will freeze/pause all alerts for them
|
||||
3. It will mark their charts as obsolete
|
||||
4. Obsolete charts are not be offered on new dashboard sessions (so hit F5 and the charts are gone)
|
||||
5. Existing dashboard sessions will continue to see them, but of course they will not refresh
|
||||
|
|
|
|||
|
|
@ -90,9 +90,9 @@ Metrics:
|
|||
| ipmi.sensor_power | power | Watts |
|
||||
| ipmi.sensor_reading_percent | percentage | % |
|
||||
|
||||
## Alarms
|
||||
## Alerts
|
||||
|
||||
There are 2 alarms:
|
||||
There are 2 alerts:
|
||||
|
||||
- The sensor is in a warning or critical state.
|
||||
- System Event Log (SEL) is non-empty.
|
||||
|
|
|
|||
|
|
@ -33,10 +33,10 @@ request_size="4k"
|
|||
ioping_opts="-T 1000000 -R"
|
||||
```
|
||||
|
||||
## alarms
|
||||
## alerts
|
||||
|
||||
Netdata will automatically attach a few alarms for each host.
|
||||
Check the [latest versions of the ioping alarms](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/ioping.conf)
|
||||
Netdata will automatically attach a few alerts for each host.
|
||||
Check the [latest versions of the ioping alerts](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/ioping.conf)
|
||||
|
||||
## Multiple ioping Plugins With Different Settings
|
||||
|
||||
|
|
|
|||
|
|
@ -14,20 +14,20 @@ from external processes, thus allowing Netdata to use **external plugins**.
|
|||
|
||||
## Provided External Plugins
|
||||
|
||||
|plugin|language|O/S|description|
|
||||
|:----:|:------:|:-:|:----------|
|
||||
|[apps.plugin](https://github.com/netdata/netdata/blob/master/collectors/apps.plugin/README.md)|`C`|linux, freebsd|monitors the whole process tree on Linux and FreeBSD and breaks down system resource usage by **process**, **user** and **user group**.|
|
||||
|[charts.d.plugin](https://github.com/netdata/netdata/blob/master/collectors/charts.d.plugin/README.md)|`BASH`|all|a **plugin orchestrator** for data collection modules written in `BASH` v4+.|
|
||||
|[cups.plugin](https://github.com/netdata/netdata/blob/master/collectors/cups.plugin/README.md)|`C`|all|monitors **CUPS**|
|
||||
|[ebpf.plugin](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md)|`C`|linux|monitors different metrics on environments using kernel internal functions.|
|
||||
|[go.d.plugin](https://github.com/netdata/go.d.plugin/blob/master/README.md)|`GO`|all|collects metrics from the system, applications, or third-party APIs.|
|
||||
|[ioping.plugin](https://github.com/netdata/netdata/blob/master/collectors/ioping.plugin/README.md)|`C`|all|measures disk latency.|
|
||||
|[freeipmi.plugin](https://github.com/netdata/netdata/blob/master/collectors/freeipmi.plugin/README.md)|`C`|linux|collects metrics from enterprise hardware sensors, on Linux servers.|
|
||||
|[nfacct.plugin](https://github.com/netdata/netdata/blob/master/collectors/nfacct.plugin/README.md)|`C`|linux|collects netfilter firewall, connection tracker and accounting metrics using `libmnl` and `libnetfilter_acct`.|
|
||||
|[xenstat.plugin](https://github.com/netdata/netdata/blob/master/collectors/xenstat.plugin/README.md)|`C`|linux|collects XenServer and XCP-ng metrics using `lxenstat`.|
|
||||
|[perf.plugin](https://github.com/netdata/netdata/blob/master/collectors/perf.plugin/README.md)|`C`|linux|collects CPU performance metrics using performance monitoring units (PMU).|
|
||||
|[python.d.plugin](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/README.md)|`python`|all|a **plugin orchestrator** for data collection modules written in `python` v2 or v3 (both are supported).|
|
||||
|[slabinfo.plugin](https://github.com/netdata/netdata/blob/master/collectors/slabinfo.plugin/README.md)|`C`|linux|collects kernel internal cache objects (SLAB) metrics.|
|
||||
| plugin | language | O/S | description |
|
||||
|:------------------------------------------------------------------------------------------------------:|:--------:|:--------------:|:----------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| [apps.plugin](https://github.com/netdata/netdata/blob/master/collectors/apps.plugin/README.md) | `C` | linux, freebsd | monitors the whole process tree on Linux and FreeBSD and breaks down system resource usage by **process**, **user** and **user group**. |
|
||||
| [charts.d.plugin](https://github.com/netdata/netdata/blob/master/collectors/charts.d.plugin/README.md) | `BASH` | all | a **plugin orchestrator** for data collection modules written in `BASH` v4+. |
|
||||
| [cups.plugin](https://github.com/netdata/netdata/blob/master/collectors/cups.plugin/README.md) | `C` | all | monitors **CUPS** |
|
||||
| [ebpf.plugin](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md) | `C` | linux | monitors different metrics on environments using kernel internal functions. |
|
||||
| [go.d.plugin](https://github.com/netdata/go.d.plugin/blob/master/README.md) | `GO` | all | collects metrics from the system, applications, or third-party APIs. |
|
||||
| [ioping.plugin](https://github.com/netdata/netdata/blob/master/collectors/ioping.plugin/README.md) | `C` | all | measures disk latency. |
|
||||
| [freeipmi.plugin](https://github.com/netdata/netdata/blob/master/collectors/freeipmi.plugin/README.md) | `C` | linux | collects metrics from enterprise hardware sensors, on Linux servers. |
|
||||
| [nfacct.plugin](https://github.com/netdata/netdata/blob/master/collectors/nfacct.plugin/README.md) | `C` | linux | collects netfilter firewall, connection tracker and accounting metrics using `libmnl` and `libnetfilter_acct`. |
|
||||
| [xenstat.plugin](https://github.com/netdata/netdata/blob/master/collectors/xenstat.plugin/README.md) | `C` | linux | collects XenServer and XCP-ng metrics using `lxenstat`. |
|
||||
| [perf.plugin](https://github.com/netdata/netdata/blob/master/collectors/perf.plugin/README.md) | `C` | linux | collects CPU performance metrics using performance monitoring units (PMU). |
|
||||
| [python.d.plugin](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/README.md) | `python` | all | a **plugin orchestrator** for data collection modules written in `python` v2 or v3 (both are supported). |
|
||||
| [slabinfo.plugin](https://github.com/netdata/netdata/blob/master/collectors/slabinfo.plugin/README.md) | `C` | linux | collects kernel internal cache objects (SLAB) metrics. |
|
||||
|
||||
Plugin orchestrators may also be described as **modular plugins**. They are modular since they accept custom made modules to be included. Writing modules for these plugins is easier than accessing the native Netdata API directly. You will find modules already available for each orchestrator under the directory of the particular modular plugin (e.g. under python.d.plugin for the python orchestrator).
|
||||
Each of these modular plugins has each own methods for defining modules. Please check the examples and their documentation.
|
||||
|
|
@ -154,18 +154,18 @@ every 5 seconds.
|
|||
There are a few environment variables that are set by `netdata` and are
|
||||
available for the plugin to use.
|
||||
|
||||
|variable|description|
|
||||
|:------:|:----------|
|
||||
|`NETDATA_USER_CONFIG_DIR`|The directory where all Netdata-related user configuration should be stored. If the plugin requires custom user configuration, this is the place the user has saved it (normally under `/etc/netdata`).|
|
||||
|`NETDATA_STOCK_CONFIG_DIR`|The directory where all Netdata -related stock configuration should be stored. If the plugin is shipped with configuration files, this is the place they can be found (normally under `/usr/lib/netdata/conf.d`).|
|
||||
|`NETDATA_PLUGINS_DIR`|The directory where all Netdata plugins are stored.|
|
||||
|`NETDATA_USER_PLUGINS_DIRS`|The list of directories where custom plugins are stored.|
|
||||
|`NETDATA_WEB_DIR`|The directory where the web files of Netdata are saved.|
|
||||
|`NETDATA_CACHE_DIR`|The directory where the cache files of Netdata are stored. Use this directory if the plugin requires a place to store data. A new directory should be created for the plugin for this purpose, inside this directory.|
|
||||
|`NETDATA_LOG_DIR`|The directory where the log files are stored. By default the `stderr` output of the plugin will be saved in the `error.log` file of Netdata.|
|
||||
|`NETDATA_HOST_PREFIX`|This is used in environments where system directories like `/sys` and `/proc` have to be accessed at a different path.|
|
||||
|`NETDATA_DEBUG_FLAGS`|This is a number (probably in hex starting with `0x`), that enables certain Netdata debugging features. Check **\[[Tracing Options]]** for more information.|
|
||||
|`NETDATA_UPDATE_EVERY`|The minimum number of seconds between chart refreshes. This is like the **internal clock** of Netdata (it is user configurable, defaulting to `1`). There is no meaning for a plugin to update its values more frequently than this number of seconds.|
|
||||
| variable | description |
|
||||
|:---------------------------:|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| `NETDATA_USER_CONFIG_DIR` | The directory where all Netdata-related user configuration should be stored. If the plugin requires custom user configuration, this is the place the user has saved it (normally under `/etc/netdata`). |
|
||||
| `NETDATA_STOCK_CONFIG_DIR` | The directory where all Netdata -related stock configuration should be stored. If the plugin is shipped with configuration files, this is the place they can be found (normally under `/usr/lib/netdata/conf.d`). |
|
||||
| `NETDATA_PLUGINS_DIR` | The directory where all Netdata plugins are stored. |
|
||||
| `NETDATA_USER_PLUGINS_DIRS` | The list of directories where custom plugins are stored. |
|
||||
| `NETDATA_WEB_DIR` | The directory where the web files of Netdata are saved. |
|
||||
| `NETDATA_CACHE_DIR` | The directory where the cache files of Netdata are stored. Use this directory if the plugin requires a place to store data. A new directory should be created for the plugin for this purpose, inside this directory. |
|
||||
| `NETDATA_LOG_DIR` | The directory where the log files are stored. By default the `stderr` output of the plugin will be saved in the `error.log` file of Netdata. |
|
||||
| `NETDATA_HOST_PREFIX` | This is used in environments where system directories like `/sys` and `/proc` have to be accessed at a different path. |
|
||||
| `NETDATA_DEBUG_FLAGS` | This is a number (probably in hex starting with `0x`), that enables certain Netdata debugging features. Check **\[[Tracing Options]]** for more information. |
|
||||
| `NETDATA_UPDATE_EVERY` | The minimum number of seconds between chart refreshes. This is like the **internal clock** of Netdata (it is user configurable, defaulting to `1`). There is no meaning for a plugin to update its values more frequently than this number of seconds. |
|
||||
|
||||
### The output of the plugin
|
||||
|
||||
|
|
@ -298,7 +298,7 @@ the template is:
|
|||
|
||||
the context is giving the template of the chart. For example, if multiple charts present the same information for a different family, they should have the same `context`
|
||||
|
||||
this is used for looking up rendering information for the chart (colors, sizes, informational texts) and also apply alarms to it
|
||||
this is used for looking up rendering information for the chart (colors, sizes, informational texts) and also apply alerts to it
|
||||
|
||||
- `charttype`
|
||||
|
||||
|
|
@ -388,12 +388,12 @@ the template is:
|
|||
|
||||
> VARIABLE [SCOPE] name = value
|
||||
|
||||
`VARIABLE` defines a variable that can be used in alarms. This is to used for setting constants (like the max connections a server may accept).
|
||||
`VARIABLE` defines a variable that can be used in alerts. This is to used for setting constants (like the max connections a server may accept).
|
||||
|
||||
Variables support 2 scopes:
|
||||
|
||||
- `GLOBAL` or `HOST` to define the variable at the host level.
|
||||
- `LOCAL` or `CHART` to define the variable at the chart level. Use chart-local variables when the same variable may exist for different charts (i.e. Netdata monitors 2 mysql servers, and you need to set the `max_connections` each server accepts). Using chart-local variables is the ideal to build alarm templates.
|
||||
- `LOCAL` or `CHART` to define the variable at the chart level. Use chart-local variables when the same variable may exist for different charts (i.e. Netdata monitors 2 mysql servers, and you need to set the `max_connections` each server accepts). Using chart-local variables is the ideal to build alert templates.
|
||||
|
||||
The position of the `VARIABLE` line, sets its default scope (in case you do not specify a scope). So, defining a `VARIABLE` before any `CHART`, or between `END` and `BEGIN` (outside any chart), sets `GLOBAL` scope, while defining a `VARIABLE` just after a `CHART` or a `DIMENSION`, or within the `BEGIN` - `END` block of a chart, sets `LOCAL` scope.
|
||||
|
||||
|
|
|
|||
|
|
@ -398,11 +398,11 @@ You can set the following values for each configuration option:
|
|||
|
||||
#### Wireless configuration
|
||||
|
||||
#### alarms
|
||||
#### alerts
|
||||
|
||||
There are several alarms defined in `health.d/net.conf`.
|
||||
There are several alerts defined in `health.d/net.conf`.
|
||||
|
||||
The tricky ones are `inbound packets dropped` and `inbound packets dropped ratio`. They have quite a strict policy so that they warn users about possible issues. These alarms can be annoying for some network configurations. It is especially true for some bonding configurations if an interface is a child or a bonding interface itself. If it is expected to have a certain number of drops on an interface for a certain network configuration, a separate alarm with different triggering thresholds can be created or the existing one can be disabled for this specific interface. It can be done with the help of the [families](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alarm-line-families) line in the alarm configuration. For example, if you want to disable the `inbound packets dropped` alarm for `eth0`, set `families: !eth0 *` in the alarm definition for `template: inbound_packets_dropped`.
|
||||
The tricky ones are `inbound packets dropped` and `inbound packets dropped ratio`. They have quite a strict policy so that they warn users about possible issues. These alerts can be annoying for some network configurations. It is especially true for some bonding configurations if an interface is a child or a bonding interface itself. If it is expected to have a certain number of drops on an interface for a certain network configuration, a separate alert with different triggering thresholds can be created or the existing one can be disabled for this specific interface. It can be done with the help of the [families](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alert-line-families) line in the alert configuration. For example, if you want to disable the `inbound packets dropped` alert for `eth0`, set `families: !eth0 *` in the alert definition for `template: inbound_packets_dropped`.
|
||||
|
||||
#### configuration
|
||||
|
||||
|
|
|
|||
|
|
@ -36,7 +36,7 @@ Netdata ships with a few synthetic chart definitions to automatically present ap
|
|||
more uniform way. These synthetic charts are configuration files (you can create your own) that re-arrange
|
||||
statsd metrics into a more meaningful way.
|
||||
|
||||
On synthetic charts, we can have alarms as with any metric and chart.
|
||||
On synthetic charts, we can have alerts as with any metric and chart.
|
||||
|
||||
- [K6 load testing tool](https://k6.io)
|
||||
- **Description:** k6 is a developer-centric, free and open-source load testing tool built for making performance testing a productive and enjoyable experience.
|
||||
|
|
@ -348,11 +348,11 @@ Using the above configuration `myapp` should get its own section on the dashboar
|
|||
- `gaps when not collected = yes|no`, enables or disables gaps on the charts of the application in case that no metrics are collected.
|
||||
- `memory mode` sets the memory mode for all charts of the application. The default is the global default for Netdata (not the global default for StatsD private charts). We suggest not to use this (we have commented it out in the example) and let your app use the global default for Netdata, which is our dbengine.
|
||||
|
||||
- `history` sets the size of the round robin database for this application. The default is the global default for Netdata (not the global default for StatsD private charts). This is only relevant if you use `memory mode = save`. Read more on our [metrics storage(]/docs/store/change-metrics-storage.md) doc.
|
||||
- `history` sets the size of the round-robin database for this application. The default is the global default for Netdata (not the global default for StatsD private charts). This is only relevant if you use `memory mode = save`. Read more on our [metrics storage(]/docs/store/change-metrics-storage.md) doc.
|
||||
|
||||
`[dictionary]` defines name-value associations. These are used to renaming metrics, when added to synthetic charts. Metric names are also defined at each `dimension` line. However, using the dictionary dimension names can be declared globally, for each app and is the only way to rename dimensions when using patterns. Of course the dictionary can be empty or missing.
|
||||
|
||||
Then, add any number of charts. Each chart should start with `[id]`. The chart will be called `app_name.id`. `family` controls the submenu on the dashboard. `context` controls the alarm templates. `priority` controls the ordering of the charts on the dashboard. The rest of the settings are informational.
|
||||
Then, add any number of charts. Each chart should start with `[id]`. The chart will be called `app_name.id`. `family` controls the submenu on the dashboard. `context` controls the alert templates. `priority` controls the ordering of the charts on the dashboard. The rest of the settings are informational.
|
||||
|
||||
Add any number of metrics to a chart, using `dimension` lines. These lines accept 5 space separated parameters:
|
||||
|
||||
|
|
@ -361,7 +361,7 @@ Add any number of metrics to a chart, using `dimension` lines. These lines accep
|
|||
3. an optional selector (type) of the value to shown (see below)
|
||||
4. an optional multiplier
|
||||
5. an optional divider
|
||||
6. optional flags, space separated and enclosed in quotes. All the external plugins `DIMENSION` flags can be used. Currently the only usable flag is `hidden`, to add the dimension, but not show it on the dashboard. This is usually needed to have the values available for percentage calculation, or use them in alarms.
|
||||
6. optional flags, space separated and enclosed in quotes. All the external plugins `DIMENSION` flags can be used. Currently, the only usable flag is `hidden`, to add the dimension, but not show it on the dashboard. This is usually needed to have the values available for percentage calculation, or use them in alerts.
|
||||
|
||||
So, the format is this:
|
||||
|
||||
|
|
@ -439,7 +439,7 @@ Use the dictionary in 2 ways:
|
|||
1. set `dimension = myapp.metric1 ''` and have at the dictionary `myapp.metric1 = metric1 name`
|
||||
2. set `dimension = myapp.metric1 'm1'` and have at the dictionary `m1 = metric1 name`
|
||||
|
||||
In both cases, the dimension will be added with ID `myapp.metric1` and will be named `metric1 name`. So, in alarms use either of the 2 as `${myapp.metric1}` or `${metric1 name}`.
|
||||
In both cases, the dimension will be added with ID `myapp.metric1` and will be named `metric1 name`. So, in alerts use either of the 2 as `${myapp.metric1}` or `${metric1 name}`.
|
||||
|
||||
> keep in mind that if you add multiple times the same StatsD metric to a chart, Netdata will append `TYPE` to the dimension ID, so `myapp.metric1` will be added as `myapp.metric1_last` or `myapp.metric1_events`, etc. If you add multiple times the same metric with the same `TYPE` to a chart, Netdata will also append an incremental counter to the dimension ID, i.e. `myapp.metric1_last1`, `myapp.metric1_last2`, etc.
|
||||
|
||||
|
|
|
|||
|
|
@ -72,40 +72,40 @@ Please note that your data history will be lost if you have modified `history` p
|
|||
|
||||
### [global] section options
|
||||
|
||||
| setting | default | info |
|
||||
|:-------------------------------------:|:-------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| process scheduling policy | `keep` | See [Netdata process scheduling policy](https://github.com/netdata/netdata/blob/master/daemon/README.md#netdata-process-scheduling-policy) |
|
||||
| OOM score | `0` | |
|
||||
| glibc malloc arena max for plugins | `1` | See [Virtual memory](https://github.com/netdata/netdata/blob/master/daemon/README.md#virtual-memory). |
|
||||
| glibc malloc arena max for Netdata | `1` | See [Virtual memory](https://github.com/netdata/netdata/blob/master/daemon/README.md#virtual-memory). |
|
||||
| hostname | auto-detected | The hostname of the computer running Netdata. |
|
||||
| host access prefix | empty | This is used in docker environments where /proc, /sys, etc have to be accessed via another path. You may also have to set SYS_PTRACE capability on the docker for this work. Check [issue 43](https://github.com/netdata/netdata/issues/43). |
|
||||
| timezone | auto-detected | The timezone retrieved from the environment variable |
|
||||
| run as user | `netdata` | The user Netdata will run as. |
|
||||
| pthread stack size | auto-detected | |
|
||||
| setting | default | info |
|
||||
|:----------------------------------:|:-------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| process scheduling policy | `keep` | See [Netdata process scheduling policy](https://github.com/netdata/netdata/blob/master/daemon/README.md#netdata-process-scheduling-policy) |
|
||||
| OOM score | `0` | |
|
||||
| glibc malloc arena max for plugins | `1` | See [Virtual memory](https://github.com/netdata/netdata/blob/master/daemon/README.md#virtual-memory). |
|
||||
| glibc malloc arena max for Netdata | `1` | See [Virtual memory](https://github.com/netdata/netdata/blob/master/daemon/README.md#virtual-memory). |
|
||||
| hostname | auto-detected | The hostname of the computer running Netdata. |
|
||||
| host access prefix | empty | This is used in docker environments where /proc, /sys, etc have to be accessed via another path. You may also have to set SYS_PTRACE capability on the docker for this work. Check [issue 43](https://github.com/netdata/netdata/issues/43). |
|
||||
| timezone | auto-detected | The timezone retrieved from the environment variable |
|
||||
| run as user | `netdata` | The user Netdata will run as. |
|
||||
| pthread stack size | auto-detected | |
|
||||
|
||||
### [db] section options
|
||||
|
||||
| setting | default | info |
|
||||
|:---------------------------------------------:|:----------:|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| setting | default | info |
|
||||
|:---------------------------------------------:|:----------:|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| mode | `dbengine` | `dbengine`: The default for long-term metrics storage with efficient RAM and disk usage. Can be extended with `dbengine page cache size MB` and `dbengine disk space MB`. <br />`save`: Netdata will save its round robin database on exit and load it on startup. <br />`map`: Cache files will be updated in real-time. Not ideal for systems with high load or slow disks (check `man mmap`). <br />`ram`: The round-robin database will be temporary and it will be lost when Netdata exits. <br />`alloc`: Similar to `ram`, but can significantly reduce memory usage, when combined with a low retention and does not support KSM. <br />`none`: Disables the database at this host, and disables health monitoring entirely, as that requires a database of metrics. Not to be used together with streaming. |
|
||||
| retention | `3600` | Used with `mode = save/map/ram/alloc`, not the default `mode = dbengine`. This number reflects the number of entries the `netdata` daemon will by default keep in memory for each chart dimension. Check [Memory Requirements](https://github.com/netdata/netdata/blob/master/database/README.md) for more information. |
|
||||
| storage tiers | `1` | The number of storage tiers you want to have in your dbengine. Check the tiering mechanism in the [dbengine's reference](https://github.com/netdata/netdata/blob/master/database/engine/README.md#tiering). You can have up to 5 tiers of data (including the _Tier 0_). This number ranges between 1 and 5. |
|
||||
| dbengine page cache size MB | `32` | Determines the amount of RAM in MiB that is dedicated to caching for _Tier 0_ Netdata metric values. |
|
||||
| dbengine tier **`N`** page cache size MB | `32` | Determines the amount of RAM in MiB that is dedicated for caching Netdata metric values of the **`N`** tier. <br /> `N belongs to [1..4]` ||
|
||||
| dbengine disk space MB | `256` | Determines the amount of disk space in MiB that is dedicated to storing _Tier 0_ Netdata metric values and all related metadata describing them. This option is available **only for legacy configuration** (`Agent v1.23.2 and prior`). |
|
||||
| dbengine multihost disk space MB | `256` | Same functionality as `dbengine disk space MB`, but includes support for storing metrics streamed to a parent node by its children. Can be used in single-node environments as well. This setting is only for _Tier 0_ metrics. |
|
||||
| dbengine tier **`N`** multihost disk space MB | `256` | Same functionality as `dbengine multihost disk space MB`, but stores metrics of the **`N`** tier (both parent node and its children). Can be used in single-node environments as well. <br /> `N belongs to [1..4]` |
|
||||
| update every | `1` | The frequency in seconds, for data collection. For more information see the [performance guide](https://github.com/netdata/netdata/blob/master/docs/guides/configure/performance.md). These metrics stored as _Tier 0_ data. Explore the tiering mechanism in the [dbengine's reference](https://github.com/netdata/netdata/blob/master/database/engine/README.md#tiering). |
|
||||
| dbengine tier **`N`** update every iterations | `60` | The down sampling value of each tier from the previous one. For each Tier, the greater by one Tier has N (equal to 60 by default) less data points of any metric it collects. This setting can take values from `2` up to `255`. <br /> `N belongs to [1..4]` |
|
||||
| dbengine tier **`N`** back fill | `New` | Specifies the strategy of recreating missing data on each Tier from the exact lower Tier. <br /> `New`: Sees the latest point on each Tier and save new points to it only if the exact lower Tier has available points for it's observation window (`dbengine tier N update every iterations` window). <br /> `none`: No back filling is applied. <br /> `N belongs to [1..4]` |
|
||||
| memory deduplication (ksm) | `yes` | When set to `yes`, Netdata will offer its in-memory round robin database and the dbengine page cache to kernel same page merging (KSM) for deduplication. For more information check [Memory Deduplication - Kernel Same Page Merging - KSM](https://github.com/netdata/netdata/blob/master/database/README.md#ksm) |
|
||||
| cleanup obsolete charts after secs | `3600` | See [monitoring ephemeral containers](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md#monitoring-ephemeral-containers), also sets the timeout for cleaning up obsolete dimensions |
|
||||
| gap when lost iterations above | `1` | |
|
||||
| cleanup orphan hosts after secs | `3600` | How long to wait until automatically removing from the DB a remote Netdata host (child) that is no longer sending data. |
|
||||
| delete obsolete charts files | `yes` | See [monitoring ephemeral containers](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md#monitoring-ephemeral-containers), also affects the deletion of files for obsolete dimensions |
|
||||
| delete orphan hosts files | `yes` | Set to `no` to disable non-responsive host removal. |
|
||||
| enable zero metrics | `no` | Set to `yes` to show charts when all their metrics are zero. |
|
||||
| retention | `3600` | Used with `mode = save/map/ram/alloc`, not the default `mode = dbengine`. This number reflects the number of entries the `netdata` daemon will by default keep in memory for each chart dimension. Check [Memory Requirements](https://github.com/netdata/netdata/blob/master/database/README.md) for more information. |
|
||||
| storage tiers | `1` | The number of storage tiers you want to have in your dbengine. Check the tiering mechanism in the [dbengine's reference](https://github.com/netdata/netdata/blob/master/database/engine/README.md#tiering). You can have up to 5 tiers of data (including the _Tier 0_). This number ranges between 1 and 5. |
|
||||
| dbengine page cache size MB | `32` | Determines the amount of RAM in MiB that is dedicated to caching for _Tier 0_ Netdata metric values. |
|
||||
| dbengine tier **`N`** page cache size MB | `32` | Determines the amount of RAM in MiB that is dedicated for caching Netdata metric values of the **`N`** tier. <br /> `N belongs to [1..4]` |
|
||||
| dbengine disk space MB | `256` | Determines the amount of disk space in MiB that is dedicated to storing _Tier 0_ Netdata metric values and all related metadata describing them. This option is available **only for legacy configuration** (`Agent v1.23.2 and prior`). |
|
||||
| dbengine multihost disk space MB | `256` | Same functionality as `dbengine disk space MB`, but includes support for storing metrics streamed to a parent node by its children. Can be used in single-node environments as well. This setting is only for _Tier 0_ metrics. |
|
||||
| dbengine tier **`N`** multihost disk space MB | `256` | Same functionality as `dbengine multihost disk space MB`, but stores metrics of the **`N`** tier (both parent node and its children). Can be used in single-node environments as well. <br /> `N belongs to [1..4]` |
|
||||
| update every | `1` | The frequency in seconds, for data collection. For more information see the [performance guide](https://github.com/netdata/netdata/blob/master/docs/guides/configure/performance.md). These metrics stored as _Tier 0_ data. Explore the tiering mechanism in the [dbengine's reference](https://github.com/netdata/netdata/blob/master/database/engine/README.md#tiering). |
|
||||
| dbengine tier **`N`** update every iterations | `60` | The down sampling value of each tier from the previous one. For each Tier, the greater by one Tier has N (equal to 60 by default) less data points of any metric it collects. This setting can take values from `2` up to `255`. <br /> `N belongs to [1..4]` |
|
||||
| dbengine tier **`N`** back fill | `New` | Specifies the strategy of recreating missing data on each Tier from the exact lower Tier. <br /> `New`: Sees the latest point on each Tier and save new points to it only if the exact lower Tier has available points for it's observation window (`dbengine tier N update every iterations` window). <br /> `none`: No back filling is applied. <br /> `N belongs to [1..4]` |
|
||||
| memory deduplication (ksm) | `yes` | When set to `yes`, Netdata will offer its in-memory round robin database and the dbengine page cache to kernel same page merging (KSM) for deduplication. For more information check [Memory Deduplication - Kernel Same Page Merging - KSM](https://github.com/netdata/netdata/blob/master/database/README.md#ksm) |
|
||||
| cleanup obsolete charts after secs | `3600` | See [monitoring ephemeral containers](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md#monitoring-ephemeral-containers), also sets the timeout for cleaning up obsolete dimensions |
|
||||
| gap when lost iterations above | `1` | |
|
||||
| cleanup orphan hosts after secs | `3600` | How long to wait until automatically removing from the DB a remote Netdata host (child) that is no longer sending data. |
|
||||
| delete obsolete charts files | `yes` | See [monitoring ephemeral containers](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md#monitoring-ephemeral-containers), also affects the deletion of files for obsolete dimensions |
|
||||
| delete orphan hosts files | `yes` | Set to `no` to disable non-responsive host removal. |
|
||||
| enable zero metrics | `no` | Set to `yes` to show charts when all their metrics are zero. |
|
||||
|
||||
> ### Info
|
||||
>
|
||||
|
|
@ -113,32 +113,32 @@ Please note that your data history will be lost if you have modified `history` p
|
|||
|
||||
### [directories] section options
|
||||
|
||||
| setting | default | info |
|
||||
|:-------------------:|:------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| config | `/etc/netdata` | The directory configuration files are kept. |
|
||||
| stock config | `/usr/lib/netdata/conf.d` | |
|
||||
| log | `/var/log/netdata` | The directory in which the [log files](https://github.com/netdata/netdata/blob/master/daemon/README.md#log-files) are kept. |
|
||||
| web | `/usr/share/netdata/web` | The directory the web static files are kept. |
|
||||
| cache | `/var/cache/netdata` | The directory the memory database will be stored if and when Netdata exits. Netdata will re-read the database when it will start again, to continue from the same point. |
|
||||
| lib | `/var/lib/netdata` | Contains the alarm log and the Netdata instance GUID. |
|
||||
| home | `/var/cache/netdata` | Contains the db files for the collected metrics. |
|
||||
| lock | `/var/lib/netdata/lock` | Contains the data collectors lock files. |
|
||||
| plugins | `"/usr/libexec/netdata/plugins.d" "/etc/netdata/custom-plugins.d"` | The directory plugin programs are kept. This setting supports multiple directories, space separated. If any directory path contains spaces, enclose it in single or double quotes. |
|
||||
| health config | `/etc/netdata/health.d` | The directory containing the user alarm configuration files, to override the stock configurations |
|
||||
| stock health config | `/usr/lib/netdata/conf.d/health.d` | Contains the stock alarm configuration files for each collector |
|
||||
| registry | `/opt/netdata/var/lib/netdata/registry` | Contains the [registry](https://github.com/netdata/netdata/blob/master/registry/README.md) database and GUID that uniquely identifies each Netdata Agent |
|
||||
| setting | default | info |
|
||||
|:-------------------:|:------------------------------------------------------------------:|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| config | `/etc/netdata` | The directory configuration files are kept. |
|
||||
| stock config | `/usr/lib/netdata/conf.d` | |
|
||||
| log | `/var/log/netdata` | The directory in which the [log files](https://github.com/netdata/netdata/blob/master/daemon/README.md#log-files) are kept. |
|
||||
| web | `/usr/share/netdata/web` | The directory the web static files are kept. |
|
||||
| cache | `/var/cache/netdata` | The directory the memory database will be stored if and when Netdata exits. Netdata will re-read the database when it will start again, to continue from the same point. |
|
||||
| lib | `/var/lib/netdata` | Contains the alert log and the Netdata instance GUID. |
|
||||
| home | `/var/cache/netdata` | Contains the db files for the collected metrics. |
|
||||
| lock | `/var/lib/netdata/lock` | Contains the data collectors lock files. |
|
||||
| plugins | `"/usr/libexec/netdata/plugins.d" "/etc/netdata/custom-plugins.d"` | The directory plugin programs are kept. This setting supports multiple directories, space separated. If any directory path contains spaces, enclose it in single or double quotes. |
|
||||
| health config | `/etc/netdata/health.d` | The directory containing the user alert configuration files, to override the stock configurations |
|
||||
| stock health config | `/usr/lib/netdata/conf.d/health.d` | Contains the stock alert configuration files for each collector |
|
||||
| registry | `/opt/netdata/var/lib/netdata/registry` | Contains the [registry](https://github.com/netdata/netdata/blob/master/registry/README.md) database and GUID that uniquely identifies each Netdata Agent |
|
||||
|
||||
### [logs] section options
|
||||
|
||||
| setting | default | info |
|
||||
|:----------------------------------:|:-----------------------------:|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| setting | default | info |
|
||||
|:----------------------------------:|:-----------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| debug flags | `0x0000000000000000` | Bitmap of debug options to enable. For more information check [Tracing Options](https://github.com/netdata/netdata/blob/master/daemon/README.md#debugging). |
|
||||
| debug | `/var/log/netdata/debug.log` | The filename to save debug information. This file will not be created if debugging is not enabled. You can also set it to `syslog` to send the debug messages to syslog, or `none` to disable this log. For more information check [Tracing Options](https://github.com/netdata/netdata/blob/master/daemon/README.md#debugging). |
|
||||
| error | `/var/log/netdata/error.log` | The filename to save error messages for Netdata daemon and all plugins (`stderr` is sent here for all Netdata programs, including the plugins). You can also set it to `syslog` to send the errors to syslog, or `none` to disable this log. |
|
||||
| access | `/var/log/netdata/access.log` | The filename to save the log of web clients accessing Netdata charts. You can also set it to `syslog` to send the access log to syslog, or `none` to disable this log. |
|
||||
| facility | `daemon` | A facility keyword is used to specify the type of system that is logging the message. |
|
||||
| errors flood protection period | `1200` | Length of period (in sec) during which the number of errors should not exceed the `errors to trigger flood protection`. |
|
||||
| errors to trigger flood protection | `200` | Number of errors written to the log in `errors flood protection period` sec before flood protection is activated. |
|
||||
| error | `/var/log/netdata/error.log` | The filename to save error messages for Netdata daemon and all plugins (`stderr` is sent here for all Netdata programs, including the plugins). You can also set it to `syslog` to send the errors to syslog, or `none` to disable this log. |
|
||||
| access | `/var/log/netdata/access.log` | The filename to save the log of web clients accessing Netdata charts. You can also set it to `syslog` to send the access log to syslog, or `none` to disable this log. |
|
||||
| facility | `daemon` | A facility keyword is used to specify the type of system that is logging the message. |
|
||||
| errors flood protection period | `1200` | Length of period (in sec) during which the number of errors should not exceed the `errors to trigger flood protection`. |
|
||||
| errors to trigger flood protection | `200` | Number of errors written to the log in `errors flood protection period` sec before flood protection is activated. |
|
||||
|
||||
### [environment variables] section options
|
||||
|
||||
|
|
@ -163,20 +163,20 @@ Please note that your data history will be lost if you have modified `history` p
|
|||
|
||||
This section controls the general behavior of the health monitoring capabilities of Netdata.
|
||||
|
||||
Specific alarms are configured in per-collector config files under the `health.d` directory. For more info, see [health
|
||||
Specific alerts are configured in per-collector config files under the `health.d` directory. For more info, see [health
|
||||
monitoring](https://github.com/netdata/netdata/blob/master/health/README.md).
|
||||
|
||||
[Alarm notifications](https://github.com/netdata/netdata/blob/master/health/notifications/README.md) are configured in `health_alarm_notify.conf`.
|
||||
[Alert notifications](https://github.com/netdata/netdata/blob/master/health/notifications/README.md) are configured in `health_alarm_notify.conf`.
|
||||
|
||||
| setting | default | info |
|
||||
|:----------------------------------------------:|:------------------------------------------------:|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| enabled | `yes` | Set to `no` to disable all alarms and notifications |
|
||||
| in memory max health log entries | 1000 | Size of the alarm history held in RAM |
|
||||
| script to execute on alarm | `/usr/libexec/netdata/plugins.d/alarm-notify.sh` | The script that sends alarm notifications. Note that in versions before 1.16, the plugins.d directory may be installed in a different location in certain OSs (e.g. under `/usr/lib/netdata`). |
|
||||
| run at least every seconds | `10` | Controls how often all alarm conditions should be evaluated. |
|
||||
| postpone alarms during hibernation for seconds | `60` | Prevents false alarms. May need to be increased if you get alarms during hibernation. |
|
||||
| health log history | `432000` | Specifies the history of alarm events (in seconds) kept in the agent's sqlite database. |
|
||||
| enabled alarms | * | Defines which alarms to load from both user and stock directories. This is a [simple pattern](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) list of alarm or template names. Can be used to disable specific alarms. For example, `enabled alarms = !oom_kill *` will load all alarms except `oom_kill`. |
|
||||
| setting | default | info |
|
||||
|:----------------------------------------------:|:------------------------------------------------:|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| enabled | `yes` | Set to `no` to disable all alerts and notifications |
|
||||
| in memory max health log entries | 1000 | Size of the alert history held in RAM |
|
||||
| script to execute on alarm | `/usr/libexec/netdata/plugins.d/alarm-notify.sh` | The script that sends alert notifications. Note that in versions before 1.16, the plugins.d directory may be installed in a different location in certain OSs (e.g. under `/usr/lib/netdata`). |
|
||||
| run at least every seconds | `10` | Controls how often all alert conditions should be evaluated. |
|
||||
| postpone alarms during hibernation for seconds | `60` | Prevents false alerts. May need to be increased if you get alerts during hibernation. |
|
||||
| health log history | `432000` | Specifies the history of alert events (in seconds) kept in the agent's sqlite database. |
|
||||
| enabled alarms | * | Defines which alerts to load from both user and stock directories. This is a [simple pattern](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) list of alert or template names. Can be used to disable specific alerts. For example, `enabled alarms = !oom_kill *` will load all alerts except `oom_kill`. |
|
||||
|
||||
### [web] section options
|
||||
|
||||
|
|
@ -222,10 +222,10 @@ for all internal Netdata plugins.
|
|||
|
||||
External plugins will have only 2 options at `netdata.conf`:
|
||||
|
||||
| setting | default | info |
|
||||
|:---------------:|:--------------------------------------------:|:------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| setting | default | info |
|
||||
|:---------------:|:--------------------------------------------:|:----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| update every | the value of `[global].update every` setting | The frequency in seconds the plugin should collect values. For more information check the [performance guide](https://github.com/netdata/netdata/blob/master/docs/guides/configure/performance.md). |
|
||||
| command options | - | Additional command line options to pass to the plugin. | |
|
||||
| command options | - | Additional command line options to pass to the plugin. |
|
||||
|
||||
External plugins that need additional configuration may support a dedicated file in `/etc/netdata`. Check their
|
||||
documentation.
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ A user accessing the Netdata dashboard **from the Cloud** will always be present
|
|||
A user accessing the Netdata dashboard **from the Agent** will, by default, be presented with the latest Netdata dashboard version (the same as Netdata Cloud) except in the following scenarios:
|
||||
* Agent doesn't have Internet access, and is unable to get the latest Netdata dashboards, as a result it falls back to the Netdata dashboard version that
|
||||
was shipped with the agent.
|
||||
* Users have defined, e.g. through URL bookmark, that they wants to see the previous version of the dashboard (accessible `http://NODE:19999/v1`, replacing `NODE` with the IP address or hostname of your Agent).
|
||||
* Users have defined, e.g. through URL bookmark, that they want to see the previous version of the dashboard (accessible `http://NODE:19999/v1`, replacing `NODE` with the IP address or hostname of your Agent).
|
||||
|
||||
## Main sections
|
||||
|
||||
|
|
@ -16,12 +16,12 @@ The Netdata dashboard consists of the following main sections:
|
|||
* [Infrastructure Overview](https://github.com/netdata/netdata/blob/master/docs/visualize/overview-infrastructure.md)
|
||||
* [Nodes view](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/nodes.md)
|
||||
* [Custom dashboards](https://learn.netdata.cloud/docs/visualizations/custom-dashboards)
|
||||
* [Alerts](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alarms.md)
|
||||
* [Alerts](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md)
|
||||
* [Anomaly Advisor](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.md)
|
||||
* [Functions](https://github.com/netdata/netdata/blob/master/docs/cloud/netdata-functions.md)
|
||||
* [Events feed](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/events-feed.md)
|
||||
|
||||
> ⚠️ Some sections of the dashboard, when accessed through the agent, may require the user to be signed-in to Netdata Cloud or having the Agent claimed to Netdata Cloud for their full functionality. Examples include saving visualization settings on charts or custom dashboards, claiming the node to Netdata Cloud, or executing functions on an Agent.
|
||||
> ⚠️ Some sections of the dashboard, when accessed through the agent, may require the user to be signed in to Netdata Cloud or having the Agent claimed to Netdata Cloud for their full functionality. Examples include saving visualization settings on charts or custom dashboards, claiming the node to Netdata Cloud, or executing functions on an Agent.
|
||||
|
||||
|
||||
Documentation for previous Agent dashboard can still be found [here](https://github.com/netdata/netdata/blob/master/web/gui/README.md).
|
||||
|
|
@ -265,4 +265,4 @@ We also suggest that you:
|
|||
|
||||
3. [Use host labels](https://github.com/netdata/netdata/blob/master/docs/guides/using-host-labels.md)
|
||||
|
||||
To organize systems, metrics, and alarms.
|
||||
To organize systems, metrics, and alerts.
|
||||
|
|
|
|||
|
|
@ -42,23 +42,23 @@ Netdata webhook integration service will send alert notifications to the destina
|
|||
|
||||
The notification content sent to the destination service will be a JSON object having these properties:
|
||||
|
||||
| field | type | description |
|
||||
| :-- | :-- | :-- |
|
||||
| message | string | A summary message of the alert. |
|
||||
| alarm | string | The alarm the notification is about. |
|
||||
| info | string | Additional info related with the alert. |
|
||||
| chart | string | The chart associated with the alert. |
|
||||
| context | string | The chart context. |
|
||||
| space | string | The space where the node that raised the alert is assigned. |
|
||||
| rooms | object[object(string,string)] | Object with list of rooms names and urls where the node belongs to. |
|
||||
| family | string | Context family. |
|
||||
| class | string | Classification of the alert, e.g. "Error". |
|
||||
| severity | string | Alert severity, can be one of "warning", "critical" or "clear". |
|
||||
| date | string | Date of the alert in ISO8601 format. |
|
||||
| duration | string | Duration the alert has been raised. |
|
||||
| additional_active_critical_alerts | integer | Number of additional critical alerts currently existing on the same node. |
|
||||
| additional_active_warning_alerts | integer | Number of additional warning alerts currently existing on the same node. |
|
||||
| alarm_url | string | Netdata Cloud URL for this alarm. |
|
||||
| field | type | description |
|
||||
|:----------------------------------|:------------------------------|:--------------------------------------------------------------------------|
|
||||
| message | string | A summary message of the alert. |
|
||||
| alarm | string | The alert the notification is about. |
|
||||
| info | string | Additional info related with the alert. |
|
||||
| chart | string | The chart associated with the alert. |
|
||||
| context | string | The chart context. |
|
||||
| space | string | The space where the node that raised the alert is assigned. |
|
||||
| rooms | object[object(string,string)] | Object with list of rooms names and urls where the node belongs to. |
|
||||
| family | string | Context family. |
|
||||
| class | string | Classification of the alert, e.g. "Error". |
|
||||
| severity | string | Alert severity, can be one of "warning", "critical" or "clear". |
|
||||
| date | string | Date of the alert in ISO8601 format. |
|
||||
| duration | string | Duration the alert has been raised. |
|
||||
| additional_active_critical_alerts | integer | Number of additional critical alerts currently existing on the same node. |
|
||||
| additional_active_warning_alerts | integer | Number of additional warning alerts currently existing on the same node. |
|
||||
| alarm_url | string | Netdata Cloud URL for this alert. |
|
||||
|
||||
### Extra headers
|
||||
|
||||
|
|
@ -66,9 +66,9 @@ When setting up a webhook integration, the user can specify a set of headers to
|
|||
|
||||
By default, the following headers will be sent in the HTTP request
|
||||
|
||||
| **Header** | **Value** |
|
||||
|:-------------------------------:|-----------------------------|
|
||||
| Content-Type | application/json |
|
||||
| **Header** | **Value** |
|
||||
|:------------:|------------------|
|
||||
| Content-Type | application/json |
|
||||
|
||||
### Authentication mechanisms
|
||||
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ you or your team.
|
|||
|
||||
Having this information centralized helps you:
|
||||
* Have a clear view of the health across your infrastructure, seeing all alerts in one place.
|
||||
* Easily [setup your alert notification process](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/manage-notification-methods.md):
|
||||
* Easily [set up your alert notification process](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/manage-notification-methods.md):
|
||||
methods to use and where to use them, filtering rules, etc.
|
||||
* Quickly troubleshoot using [Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md)
|
||||
or [Anomaly Advisor](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.md)
|
||||
|
|
@ -104,8 +104,8 @@ if the node should be silenced for the entire space or just for specific rooms (
|
|||
|
||||
### Scope definition for Alerts
|
||||
* **Alert name:** silencing a specific alert name silences all alert state transitions for that specific alert.
|
||||
* **Alert context:** silencing a specific alert context will silence all alert state transitions for alerts targeting that chart context, for more details check [alert configuration docs](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alarm-line-on).
|
||||
* **Alert role:** silencing a specific alert role will silence all the alert state transitions for alerts that are configured to be specific role recipients, for more details check [alert configuration docs](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alarm-line-to).
|
||||
* **Alert context:** silencing a specific alert context will silence all alert state transitions for alerts targeting that chart context, for more details check [alert configuration docs](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alert-line-on).
|
||||
* **Alert role:** silencing a specific alert role will silence all the alert state transitions for alerts that are configured to be specific role recipients, for more details check [alert configuration docs](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alert-line-to).
|
||||
|
||||
Beside the above two main entities there are another two important settings that you can define on a silencing rule:
|
||||
* Who does the rule affect? **All user** in the space or **Myself**
|
||||
|
|
@ -124,24 +124,24 @@ the local Agent dashboard at `http://NODE:19999`.
|
|||
|
||||
## Anatomy of an alert notification
|
||||
|
||||
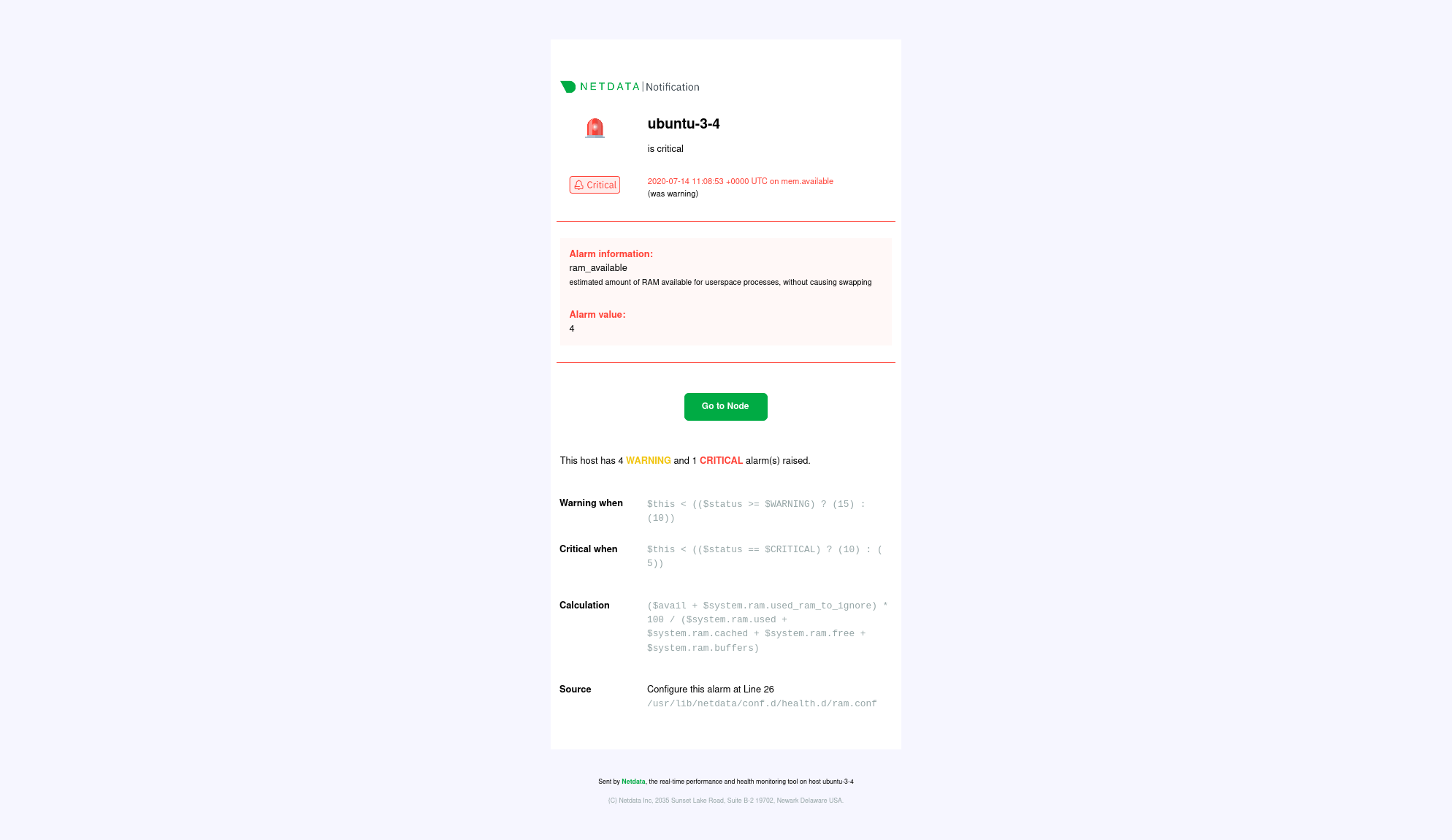
Email alarm notifications show the following information:
|
||||
Email alert notifications show the following information:
|
||||
|
||||
- The Space's name
|
||||
- The node's name
|
||||
- Alarm status: critical, warning, cleared
|
||||
- Previous alarm status
|
||||
- Time at which the alarm triggered
|
||||
- Chart context that triggered the alarm
|
||||
- Name and information about the triggered alarm
|
||||
- Alarm value
|
||||
- Alert status: critical, warning, cleared
|
||||
- Previous alert status
|
||||
- Time at which the alert triggered
|
||||
- Chart context that triggered the alert
|
||||
- Name and information about the triggered alert
|
||||
- Alert value
|
||||
- Total number of warning and critical alerts on that node
|
||||
- Threshold for triggering the given alarm state
|
||||
- Threshold for triggering the given alert state
|
||||
- Calculation or database lookups that Netdata uses to compute the value
|
||||
- Source of the alarm, including which file you can edit to configure this alarm on an individual node
|
||||
- Source of the alert, including which file you can edit to configure this alert on an individual node
|
||||
|
||||
Email notifications also feature a **Go to Node** button, which takes you directly to the offending chart for that node
|
||||
within Cloud's embedded dashboards.
|
||||
|
||||
Here's an example email notification for the `ram_available` chart, which is in a critical state:
|
||||
|
||||
|
||||

|
||||
|
|
|
|||
|
|
@ -99,13 +99,13 @@ modules:
|
|||
sudo ./edit-config go.d/mysql.conf
|
||||
```
|
||||
|
||||
### Alarms & notifications
|
||||
### Alerts & notifications
|
||||
|
||||
<!-- #### Add a new alarm
|
||||
<!-- #### Add a new alert
|
||||
|
||||
```
|
||||
sudo touch health.d/example-alarm.conf
|
||||
sudo ./edit-config health.d/example-alarm.conf
|
||||
sudo touch health.d/example-alert.conf
|
||||
sudo ./edit-config health.d/example-alert.conf
|
||||
``` -->
|
||||
After any change, reload the Netdata health configuration:
|
||||
|
||||
|
|
@ -115,23 +115,23 @@ netdatacli reload-health
|
|||
killall -USR2 netdata
|
||||
```
|
||||
|
||||
#### Configure a specific alarm
|
||||
#### Configure a specific alert
|
||||
|
||||
```bash
|
||||
sudo ./edit-config health.d/example-alarm.conf
|
||||
sudo ./edit-config health.d/example-alert.conf
|
||||
```
|
||||
|
||||
#### Silence a specific alarm
|
||||
#### Silence a specific alert
|
||||
|
||||
```bash
|
||||
sudo ./edit-config health.d/example-alarm.conf
|
||||
sudo ./edit-config health.d/example-alert.conf
|
||||
```
|
||||
|
||||
```
|
||||
to: silent
|
||||
```
|
||||
|
||||
<!-- #### Disable alarms and notifications
|
||||
<!-- #### Disable alerts and notifications
|
||||
|
||||
```conf
|
||||
[health]
|
||||
|
|
@ -142,14 +142,14 @@ sudo ./edit-config health.d/example-alarm.conf
|
|||
|
||||
### Manage the daemon
|
||||
|
||||
| Intent | Action |
|
||||
| :-------------------------- | --------------------------------------------------------------------: |
|
||||
| Start Netdata | `$ sudo service netdata start` |
|
||||
| Stop Netdata | `$ sudo service netdata stop` |
|
||||
| Restart Netdata | `$ sudo service netdata restart` |
|
||||
| Reload health configuration | `$ sudo netdatacli reload-health` `$ killall -USR2 netdata` |
|
||||
| View error logs | `less /var/log/netdata/error.log` |
|
||||
| View collectors logs | `less /var/log/netdata/collector.log` |
|
||||
| Intent | Action |
|
||||
|:----------------------------|------------------------------------------------------------:|
|
||||
| Start Netdata | `$ sudo service netdata start` |
|
||||
| Stop Netdata | `$ sudo service netdata stop` |
|
||||
| Restart Netdata | `$ sudo service netdata restart` |
|
||||
| Reload health configuration | `$ sudo netdatacli reload-health` `$ killall -USR2 netdata` |
|
||||
| View error logs | `less /var/log/netdata/error.log` |
|
||||
| View collectors logs | `less /var/log/netdata/collector.log` |
|
||||
|
||||
#### Change the port Netdata listens to (example, set it to port 39999)
|
||||
|
||||
|
|
|
|||
|
|
@ -23,7 +23,7 @@ device, and sign in.
|
|||
|
||||
### Don't have a Netdata Cloud account yet?
|
||||
|
||||
If you don't have a Netdata Cloud account yet you won't need to worry about it. During the sign in process we will create one for you and make the process seamless to you.
|
||||
If you don't already have a Netdata Cloud account, you don't need to worry about this. During the sign-in process we will create one for you and make the process seamless to you.
|
||||
|
||||
After your account is created and you sign in to Netdata, you first are asked to agree to Netdata Cloud's [Privacy
|
||||
Policy](https://www.netdata.cloud/privacy/) and [Terms of Use](https://www.netdata.cloud/terms/). Once you agree with these you are directed
|
||||
|
|
@ -40,14 +40,14 @@ If you don't see the email, try the following:
|
|||
- Check your spam folder.
|
||||
- In Gmail, check the **Updates** category.
|
||||
- Check [Netdata Cloud status](https://status.netdata.cloud) for ongoing issues with our infrastructure.
|
||||
- Request another sign in email via the [sign in page](https://app.netdata.cloud/sign-in?cloudRoute=spaces?utm_source=docs&utm_content=sign_in_button_troubleshooting_section).
|
||||
- Request another sign in email via the [sign-in page](https://app.netdata.cloud/sign-in?cloudRoute=spaces?utm_source=docs&utm_content=sign_in_button_troubleshooting_section).
|
||||
|
||||
You may also want to add `no-reply@netdata.cloud` to your address book or contacts list, especially if you're using
|
||||
a public email service, such as Gmail. You may also want to whitelist/allowlist either the specific email or the entire
|
||||
`netdata.cloud` domain.
|
||||
|
||||
In some cases, temporary issues with your mail server or email account may result in your email address being added to a Bounce list by Sendgrid.
|
||||
If you are added to that list, no Netdata cloud email can reach you, including alarm notifications. Let us know in Discord that you have trouble receiving
|
||||
If you are added to that list, no Netdata cloud email can reach you, including alert notifications. Let us know in Discord that you have trouble receiving
|
||||
any email from us and someone will ask you to provide your email address privately, so we can check if you are on the Bounce list.
|
||||
|
||||
## Google and GitHub OAuth
|
||||
|
|
|
|||
|
|
@ -4,15 +4,11 @@ The node filter allows you to quickly filter the nodes visualized in a War Room'
|
|||
|
||||
Inside the filter, the nodes get categorized into three groups:
|
||||
|
||||
- Live nodes
|
||||
Nodes that are currently online, collecting and streaming metrics to Cloud.
|
||||
- Live nodes display raised [Alert](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alarms.md) counters, [Machine Learning](https://github.com/netdata/netdata/blob/master/ml/README.md) availability, and [Functions](https://github.com/netdata/netdata/blob/master/docs/cloud/netdata-functions.md) availability
|
||||
- Stale nodes
|
||||
Nodes that are offline and not streaming metrics to Cloud. Only historical data can be presented from a parent node.
|
||||
- For these nodes you can only see their ML status, as they are not online to provide more information
|
||||
- Offline nodes
|
||||
Nodes that are offline, not streaming metrics to Cloud and not available in any parent node.
|
||||
Offline nodes are automatically deleted after 30 days and can also be deleted manually.
|
||||
| Group | Description |
|
||||
|---------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| Live | Nodes that are currently online, collecting and streaming metrics to Cloud. Live nodes display raised [Alert](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md) counters, [Machine Learning](https://github.com/netdata/netdata/blob/master/ml/README.md) availability, and [Functions](https://github.com/netdata/netdata/blob/master/docs/cloud/netdata-functions.md) availability |
|
||||
| Stale | Nodes that are offline and not streaming metrics to Cloud. Only historical data can be presented from a parent node. For these nodes you can only see their ML status, as they are not online to provide more information |
|
||||
| Offline | Nodes that are offline, not streaming metrics to Cloud and not available in any parent node. Offline nodes are automatically deleted after 30 days and can also be deleted manually. |
|
||||
|
||||
By using the search bar, you can narrow down to specific nodes based on their name.
|
||||
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ to any node's dashboard for troubleshooting performance issues or anomalies usin
|
|||
Cloud](https://user-images.githubusercontent.com/1153921/119035218-2eebb700-b964-11eb-8b74-4ec2df0e457c.png)
|
||||
|
||||
Each War Room's Nodes tab is populated based on the nodes you added to that specific War Room. Each node occupies a
|
||||
single row, first featuring that node's alarm status (yellow for warnings, red for critical alarms) and operating
|
||||
single row, first featuring that node's alert status (yellow for warnings, red for critical alerts) and operating
|
||||
system, some essential information about the node, followed by columns of user-defined key metrics represented in
|
||||
real-time charts.
|
||||
|
||||
|
|
|
|||
|
|
@ -71,13 +71,13 @@ _entirely for free_. These methods work together to help you troubleshoot perfor
|
|||
your k8s infrastructure.
|
||||
|
||||
- A [Helm chart](https://github.com/netdata/helmchart), which bootstraps a Netdata Agent pod on every node in your
|
||||
cluster, plus an additional parent pod for storing metrics and managing alarm notifications.
|
||||
cluster, plus an additional parent pod for storing metrics and managing alert notifications.
|
||||
- A [service discovery plugin](https://github.com/netdata/agent-service-discovery), which discovers and creates
|
||||
configuration files for [compatible
|
||||
applications](https://github.com/netdata/helmchart#service-discovery-and-supported-services) and any endpoints
|
||||
covered by our [generic Prometheus
|
||||
collector](https://github.com/netdata/go.d.plugin/blob/master/modules/prometheus/README.md). With these
|
||||
configuration files, Netdata collects metrics from any compatible applications as they run _inside_ of a pod.
|
||||
configuration files, Netdata collects metrics from any compatible applications as they run _inside_ a pod.
|
||||
Service discovery happens without manual intervention as pods are created, destroyed, or moved between nodes.
|
||||
- A [Kubelet collector](https://github.com/netdata/go.d.plugin/blob/master/modules/k8s_kubelet/README.md), which runs
|
||||
on each node in a k8s cluster to monitor the number of pods/containers, the volume of operations on each container,
|
||||
|
|
|
|||
|
|
@ -64,45 +64,45 @@ of
|
|||
To disable specific collectors, open `go.d.conf`, `python.d.conf` or `charts.d.conf` and find the line
|
||||
for that specific module. Uncomment the line and change its value to `no`.
|
||||
|
||||
## Modify alarms and notifications
|
||||
## Modify alerts and notifications
|
||||
|
||||
Netdata's health monitoring watchdog uses hundreds of preconfigured health entities, with intelligent thresholds, to
|
||||
generate warning and critical alarms for most production systems and their applications without configuration. However,
|
||||
each alarm and notification method is completely customizable.
|
||||
generate warning and critical alerts for most production systems and their applications without configuration. However,
|
||||
each alert and notification method is completely customizable.
|
||||
|
||||
### Add a new alarm
|
||||
### Add a new alert
|
||||
|
||||
To create a new alarm configuration file, initiate an empty file, with a filename that ends in `.conf`, in the
|
||||
`health.d/` directory. The Netdata Agent loads any valid alarm configuration file ending in `.conf` in that directory.
|
||||
Next, edit the new file with `edit-config`. For example, with a file called `example-alarm.conf`.
|
||||
To create a new alert configuration file, initiate an empty file, with a filename that ends in `.conf`, in the
|
||||
`health.d/` directory. The Netdata Agent loads any valid alert configuration file ending in `.conf` in that directory.
|
||||
Next, edit the new file with `edit-config`. For example, with a file called `example-alert.conf`.
|
||||
|
||||
```bash
|
||||
sudo touch health.d/example-alarm.conf
|
||||
sudo ./edit-config health.d/example-alarm.conf
|
||||
sudo touch health.d/example-alert.conf
|
||||
sudo ./edit-config health.d/example-alert.conf
|
||||
```
|
||||
|
||||
Or, append your new alarm to an existing file by editing a relevant existing file in the `health.d/` directory.
|
||||
Or, append your new alert to an existing file by editing a relevant existing file in the `health.d/` directory.
|
||||
|
||||
Read more about [configuring alarms](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) to
|
||||
Read more about [configuring alerts](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) to
|
||||
get started, and see
|
||||
the [health monitoring reference](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) for a full listing
|
||||
of options available in health entities.
|
||||
|
||||
### Configure a specific alarm
|
||||
### Configure a specific alert
|
||||
|
||||
Tweak existing alarms by editing files in the `health.d/` directory. For example, edit `health.d/cpu.conf` to change how
|
||||
Tweak existing alerts by editing files in the `health.d/` directory. For example, edit `health.d/cpu.conf` to change how
|
||||
the Agent responds to anomalies related to CPU utilization.
|
||||
|
||||
To see which configuration file you need to edit to configure a specific
|
||||
alarm, [view your active alarms](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alarms.md) in
|
||||
alert, [view your active alerts](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md) in
|
||||
Netdata Cloud or the local Agent dashboard and look for the **source** line. For example, it might
|
||||
read `source 4@/usr/lib/netdata/conf.d/health.d/cpu.conf`.
|
||||
|
||||
Because the source path contains `health.d/cpu.conf`, run `sudo edit-config health.d/cpu.conf` to configure that alarm.
|
||||
Because the source path contains `health.d/cpu.conf`, run `sudo edit-config health.d/cpu.conf` to configure that alert.
|
||||
|
||||
### Disable a specific alarm
|
||||
### Disable a specific alert
|
||||
|
||||
Open the configuration file for that alarm and set the `to` line to `silent`.
|
||||
Open the configuration file for that alert and set the `to` line to `silent`.
|
||||
|
||||
```conf
|
||||
template: disk_fill_rate
|
||||
|
|
@ -113,14 +113,13 @@ template: disk_fill_rate
|
|||
to: silent
|
||||
```
|
||||
|
||||
### Turn of all alarms and notifications
|
||||
### Turn of all alerts and notifications
|
||||
|
||||
Set `enabled` to `no` in
|
||||
the [`[health]` section](https://github.com/netdata/netdata/blob/master/daemon/config/README.md#health-section-options)
|
||||
section of
|
||||
`netdata.conf`.
|
||||
the [`[health]`](https://github.com/netdata/netdata/blob/master/daemon/config/README.md#health-section-options)
|
||||
section of `netdata.conf`.
|
||||
|
||||
### Enable alarm notifications
|
||||
### Enable alert notifications
|
||||
|
||||
Open `health_alarm_notify.conf` for editing. First, read the [enabling
|
||||
notifications](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md#netdata-agent) doc
|
||||
|
|
@ -156,5 +155,5 @@ The following restrictions apply to host label names:
|
|||
- Names only accept alphabet letters, numbers, dots, and dashes.
|
||||
|
||||
The policy for values is more flexible, but you can not use exclamation marks (`!`), whitespaces (` `), single quotes
|
||||
(`'`), double quotes (`"`), or asterisks (`*`), because they are used to compare label values in health alarms and
|
||||
(`'`), double quotes (`"`), or asterisks (`*`), because they are used to compare label values in health alerts and
|
||||
templates.
|
||||
|
|
|
|||
|
|
@ -42,7 +42,7 @@ exist.
|
|||
**Application** charts from [`apps.plugin`](https://github.com/netdata/netdata/blob/master/collectors/apps.plugin/README.md) or
|
||||
[`ebpf.plugin`](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md).
|
||||
- `health.d/` is a directory that contains [health configuration files](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md).
|
||||
- `health_alarm_notify.conf` enables and configures [alarm notifications](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md).
|
||||
- `health_alarm_notify.conf` enables and configures [alert notifications](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md).
|
||||
- `statsd.d/` is a directory for configuring Netdata's [statsd collector](https://github.com/netdata/netdata/blob/master/collectors/statsd.plugin/README.md).
|
||||
- `stream.conf` configures [parent-child streaming](https://github.com/netdata/netdata/blob/master/streaming/README.md) between separate nodes running the Agent.
|
||||
- `.environment` is a hidden file that describes the environment in which the Netdata Agent is installed, including the
|
||||
|
|
|
|||
|
|
@ -103,8 +103,8 @@ the sentence is action. In passive voice, the subject is acted upon. A famous ex
|
|||
|
||||
| | |
|
||||
|-----------------|-------------------------------------------------------------------------------------------|
|
||||
| Not recommended | When an alarm is triggered by a metric, a notification is sent by Netdata. |
|
||||
| **Recommended** | When a metric triggers an alarm, Netdata sends a notification to your preferred endpoint. |
|
||||
| Not recommended | When an alert is triggered by a metric, a notification is sent by Netdata. |
|
||||
| **Recommended** | When a metric triggers an alert, Netdata sends a notification to your preferred endpoint. |
|
||||
|
||||
### Second person
|
||||
|
||||
|
|
@ -470,7 +470,7 @@ The following tables describe the standard spelling, capitalization, and usage o
|
|||
| Term | Definition |
|
||||
|-----------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| **claimed node** | A node that you've proved ownership of by completing the [connecting to Cloud process](https://github.com/netdata/netdata/blob/master/claim/README.md). The claimed node will then appear in your Space and any War Rooms you added it to. |
|
||||
| **Netdata** | The company behind the open-source Netdata Agent and the Netdata Cloud web application. Never use _netdata_ or _NetData_. <br /><br />In general, focus on the user's goals, actions, and solutions rather than what the company provides. For example, write _Learn more about enabling alarm notifications on your preferred platforms_ instead of _Netdata sends alarm notifications to your preferred platforms_. |
|
||||
| **Netdata** | The company behind the open-source Netdata Agent and the Netdata Cloud web application. Never use _netdata_ or _NetData_. <br /><br />In general, focus on the user's goals, actions, and solutions rather than what the company provides. For example, write _Learn more about enabling alert notifications on your preferred platforms_ instead of _Netdata sends alert notifications to your preferred platforms_. |
|
||||
| **Netdata Agent** | The free and open source [monitoring agent](https://github.com/netdata/netdata) that you can install on all of your distributed systems, whether they're physical, virtual, containerized, ephemeral, and more. The Agent monitors systems running Linux, Docker, Kubernetes, macOS, FreeBSD, and more, and collects metrics from hundreds of popular services and applications. |
|
||||
| **Netdata Cloud** | The web application hosted at [https://app.netdata.cloud](https://app.netdata.cloud) that helps you monitor an entire infrastructure of distributed systems in real time. <br /><br />Never use _Cloud_ without the preceding _Netdata_ to avoid ambiguity. |
|
||||
| **Netdata community forum** | The Discourse-powered forum for feature requests, Netdata Cloud technical support, and conversations about Netdata's monitoring and troubleshooting products. |
|
||||
|
|
@ -478,12 +478,12 @@ The following tables describe the standard spelling, capitalization, and usage o
|
|||
| **Space** | The highest level container within Netdata Cloud for a user to organize their team members and nodes within their infrastructure. A Space likely represents an entire organization or a large team. <br /><br />_Space_ is always capitalized. |
|
||||
| **unreachable node** | A connected node with a disrupted [Agent-Cloud link](https://github.com/netdata/netdata/blob/master/aclk/README.md). Unreachable could mean the node no longer exists or is experiencing network connectivity issues with Cloud. |
|
||||
| **visited node** | A node which has had its Agent dashboard directly visited by a user. A list of these is maintained on a per-user basis. |
|
||||
| **War Room** | A smaller grouping of nodes where users can view key metrics in real-time and monitor the health of many nodes with their alarm status. War Rooms can be used to organize nodes in any way that makes sense for your infrastructure, such as by a service, purpose, physical location, and more. <br /><br />_War Room_ is always capitalized. |
|
||||
| **War Room** | A smaller grouping of nodes where users can view key metrics in real-time and monitor the health of many nodes with their alert status. War Rooms can be used to organize nodes in any way that makes sense for your infrastructure, such as by a service, purpose, physical location, and more. <br /><br />_War Room_ is always capitalized. |
|
||||
|
||||
### Other technical terms
|
||||
|
||||
| Term | Definition |
|
||||
|-----------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| **filesystem** | Use instead of _file system_. |
|
||||
| **preconfigured** | The concept that many of Netdata's features come with sane defaults that users don't need to configure to find immediate value. |
|
||||
| **real time**/**real-time** | Use _real time_ as a noun phrase, most often with _in_: _Netdata collects metrics in real time_. Use _real-time_ as an adjective: _Netdata collects real-time metrics from hundreds of supported applications and services. |
|
||||
| Term | Definition |
|
||||
|-----------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| **filesystem** | Use instead of _file system_. |
|
||||
| **preconfigured** | The concept that many of Netdata's features come with sane defaults that users don't need to configure to find immediate value. |
|
||||
| **real time**/**real-time** | Use _real time_ as a noun phrase, most often with _in_: _Netdata collects metrics in real time_. Use _real-time_ as an adjective: _Netdata collects real-time metrics from hundreds of supported applications and services. |
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ they have a lot of underlying complexity. To meaningfully organize charts out of
|
|||
your nodes, Netdata uses the concepts of **dimensions**, **contexts**, and **families**.
|
||||
|
||||
Understanding how these work will help you more easily navigate the dashboard,
|
||||
[write new alarms](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md), or play around
|
||||
[write new alerts](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md), or play around
|
||||
with the [API](https://github.com/netdata/netdata/blob/master/web/api/README.md).
|
||||
|
||||
## Dimension
|
||||
|
|
@ -42,8 +42,8 @@ whereas anything after the `.` is specified either by the chart's developer or b
|
|||
|
||||
By default, a chart's type affects where it fits in the menu, while its family creates submenus.
|
||||
|
||||
Netdata also relies on contexts for [alarm configuration](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) (the [`on`
|
||||
line](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alarm-line-on)).
|
||||
Netdata also relies on contexts for [alert configuration](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) (the [`on`
|
||||
line](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alert-line-on)).
|
||||
|
||||
## Family
|
||||
|
||||
|
|
@ -62,7 +62,7 @@ Given the four example contexts, and two families of `sda` and `sdb`, Netdata wi
|
|||
names:
|
||||
|
||||
| Context | `sda` family | `sdb` family |
|
||||
| :------------- | ------------------ | ------------------ |
|
||||
|:---------------|--------------------|--------------------|
|
||||
| `disk.io` | `disk_io.sda` | `disk_io.sdb` |
|
||||
| `disk.ops` | `disk_ops.sda` | `disk_ops.sdb` |
|
||||
| `disk.backlog` | `disk_backlog.sda` | `disk_backlog.sdb` |
|
||||
|
|
|
|||
|
|
@ -18,8 +18,8 @@ Netdata can export snapshots of the contents of your dashboard at a given time,
|
|||
node running Netdata. Or, you can create a print-ready version of your dashboard to save to PDF or actually print to
|
||||
paper.
|
||||
|
||||
Snapshots can be incredibly useful for diagnosing anomalies after they've already happened. Let's say Netdata triggered a warning alarm while you were asleep. In the morning, you can [select the
|
||||
timeframe](https://github.com/netdata/netdata/blob/master/docs/dashboard/visualization-date-and-time-controls.md) when the alarm triggered, export a snapshot, and send it to a
|
||||
Snapshots can be incredibly useful for diagnosing anomalies after they've already happened. Let's say Netdata triggered a warning alert while you were asleep. In the morning, you can [select the
|
||||
timeframe](https://github.com/netdata/netdata/blob/master/docs/dashboard/visualization-date-and-time-controls.md) when the alert triggered, export a snapshot, and send it to a
|
||||
|
||||
colleague for further analysis.
|
||||
|
||||
|
|
|
|||
|
|
@ -17,7 +17,7 @@ Netdata is:
|
|||
- **One-line deployment** for Linux distributions, plus support for Kubernetes/Docker infrastructures.
|
||||
- **Zero configuration and maintenance** required to collect thousands of metrics, every second, from the underlying
|
||||
OS and running applications.
|
||||
- **Prebuilt charts and alarms** alert you to common anomalies and performance issues without manual configuration.
|
||||
- **Prebuilt charts and alerts** alert you to common anomalies and performance issues without manual configuration.
|
||||
- **Distributed storage** to simplify the cost and complexity of storing metrics data from any number of nodes.
|
||||
|
||||
### Powerful and scalable
|
||||
|
|
@ -48,7 +48,7 @@ Netdata offers many benefits over the existing monitoring landscape, whether the
|
|||
open-source tools.
|
||||
|
||||
| Netdata | Others (open-source and commercial) |
|
||||
| :-------------------------------------------------------------- | :--------------------------------------------------------------- |
|
||||
|:----------------------------------------------------------------|:-----------------------------------------------------------------|
|
||||
| **High resolution metrics** (1s granularity) | Low resolution metrics (10s granularity at best) |
|
||||
| Collects **thousands of metrics per node** | Collects just a few metrics |
|
||||
| Fast UI optimized for **anomaly detection** | UI is good for just an abstract view |
|
||||
|
|
@ -64,7 +64,7 @@ Netdata works with tons of applications, notifications platforms, and other time
|
|||
- **300+ system, container, and application endpoints**: Collectors autodetect metrics from default endpoints and
|
||||
immediately visualize them into meaningful charts designed for troubleshooting. See [everything we
|
||||
support](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md).
|
||||
- **20+ notification platforms**: Netdata's health watchdog sends warning and critical alarms to your [favorite
|
||||
- **20+ notification platforms**: Netdata's health watchdog sends warning and critical alerts to your [favorite
|
||||
platform](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md) to inform you of anomalies just seconds
|
||||
after they affect your node.
|
||||
- **30+ external time-series databases**: Export resampled metrics as they're collected to other [local- and
|
||||
|
|
@ -96,9 +96,9 @@ You can install Netdata on most Linux distributions (Ubuntu, Debian, CentOS, and
|
|||
|
||||
### Netdata Cloud
|
||||
|
||||
Netdata Cloud is a web application that gives you real-time visibility for your entire infrastructure. With Netdata Cloud, you can view key metrics, insightful charts, and active alarms from all your nodes in a single web interface. When an anomaly strikes, seamlessly navigate to any node to troubleshoot and discover the root cause with the familiar Netdata dashboard.
|
||||
Netdata Cloud is a web application that gives you real-time visibility for your entire infrastructure. With Netdata Cloud, you can view key metrics, insightful charts, and active alerts from all your nodes in a single web interface. When an anomaly strikes, seamlessly navigate to any node to troubleshoot and discover the root cause with the familiar Netdata dashboard.
|
||||
|
||||
Netdata Cloud is free! You can add an entire infrastructure of nodes, invite all your colleagues, and visualize any number of metrics, charts, and alarms entirely for free.
|
||||
Netdata Cloud is free! You can add an entire infrastructure of nodes, invite all your colleagues, and visualize any number of metrics, charts, and alerts entirely for free.
|
||||
|
||||
While Netdata Cloud offers a centralized method of monitoring your Agents, your metrics data is not stored or centralized in any way. Metrics data remains with your nodes and is only streamed to your browser, through Cloud, when you're viewing the Netdata Cloud interface.
|
||||
|
||||
|
|
@ -189,5 +189,5 @@ _When people first hear about a new product, they frequently ask if it is any go
|
|||
[remarked](https://news.ycombinator.com/item?id=3067434):_
|
||||
|
||||
> Note to self: Starting immediately, all raganwald projects will have a “Is it any good?” section in the readme, and
|
||||
> the answer shall be “yes.".
|
||||
> the answer shall be "yes.".
|
||||
*******************************************************************************
|
||||
|
|
|
|||
|
|
@ -33,7 +33,7 @@ Use the alphabatized list below to find the answer to your single-term questions
|
|||
|
||||
- [**Child**](https://github.com/netdata/netdata/blob/master/docs/metrics-storage-management/enable-streaming.md#streaming-basics): A node, running Netdata, that streams metric data to one or more parent.
|
||||
|
||||
- [**Cloud** or **Netdata Cloud**](https://github.com/netdata/netdata/blob/master/docs/quickstart/infrastructure.md): Netdata Cloud is a web application that gives you real-time visibility for your entire infrastructure. With Netdata Cloud, you can view key metrics, insightful charts, and active alarms from all your nodes in a single web interface.
|
||||
- [**Cloud** or **Netdata Cloud**](https://github.com/netdata/netdata/blob/master/docs/quickstart/infrastructure.md): Netdata Cloud is a web application that gives you real-time visibility for your entire infrastructure. With Netdata Cloud, you can view key metrics, insightful charts, and active alerts from all your nodes in a single web interface.
|
||||
|
||||
- [**Collector**](https://github.com/netdata/netdata/blob/master/collectors/README.md#collector-architecture-and-terminology): A catch-all term for any Netdata process that gathers metrics from an endpoint.
|
||||
|
||||
|
|
@ -114,7 +114,7 @@ metrics, troubleshoot complex performance problems, and make data interoperable
|
|||
|
||||
- [**Netdata Agent** or **Agent**](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md): Netdata's distributed monitoring Agent collects thousands of metrics from systems, hardware, and applications with zero configuration. It runs permanently on all your physical/virtual servers, containers, cloud deployments, and edge/IoT devices.
|
||||
|
||||
- [**Netdata Cloud** or **Cloud**](https://github.com/netdata/netdata/blob/master/docs/quickstart/infrastructure.md): Netdata Cloud is a web application that gives you real-time visibility for your entire infrastructure. With Netdata Cloud, you can view key metrics, insightful charts, and active alarms from all your nodes in a single web interface.
|
||||
- [**Netdata Cloud** or **Cloud**](https://github.com/netdata/netdata/blob/master/docs/quickstart/infrastructure.md): Netdata Cloud is a web application that gives you real-time visibility for your entire infrastructure. With Netdata Cloud, you can view key metrics, insightful charts, and active alerts from all your nodes in a single web interface.
|
||||
|
||||
- [**Netdata Functions** or **Functions**](https://github.com/netdata/netdata/blob/master/docs/cloud/netdata-functions.md): Routines exposed by a collector on the Netdata Agent that can bring additional information to support troubleshooting or trigger some action to happen on the node itself.
|
||||
|
||||
|
|
|
|||
|
|
@ -94,13 +94,13 @@ We do have [extensive
|
|||
documentation](https://github.com/netdata/go.d.plugin/blob/master/modules/weblog/README.md#custom-log-format) on how
|
||||
to build custom parsing for Nginx and Apache logs.
|
||||
|
||||
## Tweak web log collector alarms
|
||||
## Tweak web log collector alerts
|
||||
|
||||
Over time, we've created some default alarms for web log monitoring. These alarms are designed to work only when your
|
||||
Over time, we've created some default alerts for web log monitoring. These alerts are designed to work only when your
|
||||
web server is receiving more than 120 requests per minute. Otherwise, there's simply not enough data to make conclusions
|
||||
about what is "too few" or "too many."
|
||||
|
||||
- [web log alarms](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/web_log.conf).
|
||||
- [web log alerts](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/web_log.conf).
|
||||
|
||||
You can also edit this file directly with `edit-config`:
|
||||
|
||||
|
|
@ -108,5 +108,5 @@ You can also edit this file directly with `edit-config`:
|
|||
./edit-config health.d/weblog.conf
|
||||
```
|
||||
|
||||
For more information about editing the defaults or writing new alarm entities, see our
|
||||
For more information about editing the defaults or writing new alert entities, see our
|
||||
[health monitoring documentation](https://github.com/netdata/netdata/blob/master/health/README.md).
|
||||
|
|
|
|||
|
|
@ -28,7 +28,7 @@ Let's dive in and walk through the process of monitoring CockroachDB metrics wit
|
|||
- [What's in this guide](#whats-in-this-guide)
|
||||
- [Configure the CockroachDB collector](#configure-the-cockroachdb-collector)
|
||||
- [Manual setup for a local CockroachDB database](#manual-setup-for-a-local-cockroachdb-database)
|
||||
- [Tweak CockroachDB alarms](#tweak-cockroachdb-alarms)
|
||||
- [Tweak CockroachDB alerts](#tweak-cockroachdb-alerts)
|
||||
|
||||
## Configure the CockroachDB collector
|
||||
|
||||
|
|
@ -102,9 +102,9 @@ Netdata to see your new charts.
|
|||
<figcaption>Charts showing a node failure during a simulated test</figcaption>
|
||||
</figure>
|
||||
|
||||
## Tweak CockroachDB alarms
|
||||
## Tweak CockroachDB alerts
|
||||
|
||||
This release also includes eight pre-configured alarms for live nodes, such as whether the node is live, storage
|
||||
This release also includes eight pre-configured alerts for live nodes, such as whether the node is live, storage
|
||||
capacity, issues with replication, and the number of SQL connections/statements. See [health.d/cockroachdb.conf on
|
||||
GitHub](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/cockroachdb.conf) for details.
|
||||
|
||||
|
|
@ -115,4 +115,4 @@ cd /etc/netdata/ # Replace with your Netdata configuration directory, if not /et
|
|||
./edit-config health.d/cockroachdb.conf # You may need to use `sudo` for write privileges
|
||||
```
|
||||
|
||||
For more information about editing the defaults or writing new alarm entities, see our documentation on [configuring health alarms](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md).
|
||||
For more information about editing the defaults or writing new alert entities, see our documentation on [configuring health alerts](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md).
|
||||
|
|
|
|||
|
|
@ -173,13 +173,13 @@ sudo systemctl restart netdata
|
|||
Upon restart, Netdata should recognize your HDFS/Zookeeper servers, enable the HDFS and Zookeeper modules, and begin
|
||||
showing real-time metrics for both in your Netdata dashboard. 🎉
|
||||
|
||||
## Configuring HDFS and Zookeeper alarms
|
||||
## Configuring HDFS and Zookeeper alerts
|
||||
|
||||
The Netdata community helped us create sane defaults for alarms related to both HDFS and Zookeeper. You may want to
|
||||
The Netdata community helped us create sane defaults for alerts related to both HDFS and Zookeeper. You may want to
|
||||
investigate these to ensure they work well with your Hadoop implementation.
|
||||
|
||||
- [HDFS alarms](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/hdfs.conf)
|
||||
- [Zookeeper alarms](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/zookeeper.conf)
|
||||
- [HDFS alerts](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/hdfs.conf)
|
||||
- [Zookeeper alerts](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/zookeeper.conf)
|
||||
|
||||
You can also access/edit these files directly with `edit-config`:
|
||||
|
||||
|
|
@ -188,5 +188,5 @@ sudo /etc/netdata/edit-config health.d/hdfs.conf
|
|||
sudo /etc/netdata/edit-config health.d/zookeeper.conf
|
||||
```
|
||||
|
||||
For more information about editing the defaults or writing new alarm entities, see our
|
||||
For more information about editing the defaults or writing new alert entities, see our
|
||||
[health monitoring documentation](https://github.com/netdata/netdata/blob/master/health/README.md).
|
||||
|
|
|
|||
|
|
@ -53,13 +53,13 @@ Pressing the anomalies icon (next to the information icon in the chart header) w
|
|||
|
||||
## Anomaly Rate Based Alerts
|
||||
|
||||
It is possible to use the `anomaly-bit` when defining traditional Alerts within netdata. The `anomaly-bit` is just another `options` parameter that can be passed as part of an [alarm line lookup](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md#alarm-line-lookup).
|
||||
It is possible to use the `anomaly-bit` when defining traditional Alerts within netdata. The `anomaly-bit` is just another `options` parameter that can be passed as part of an [alert line lookup](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md#alert-line-lookup).
|
||||
|
||||
You can see some example ML based alert configurations below:
|
||||
|
||||
- [Anomaly rate based CPU dimensions alarm](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md#example-8---anomaly-rate-based-cpu-dimensions-alarm)
|
||||
- [Anomaly rate based CPU chart alarm](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md#example-9---anomaly-rate-based-cpu-chart-alarm)
|
||||
- [Anomaly rate based node level alarm](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md#example-10---anomaly-rate-based-node-level-alarm)
|
||||
- [Anomaly rate based CPU dimensions alert](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#example-8---anomaly-rate-based-cpu-dimensions-alert)
|
||||
- [Anomaly rate based CPU chart alert](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#example-9---anomaly-rate-based-cpu-chart-alert)
|
||||
- [Anomaly rate based node level alert](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#example-10---anomaly-rate-based-node-level-alert)
|
||||
- More examples in the [`/health/health.d/ml.conf`](https://github.com/netdata/netdata/blob/master/health/health.d/ml.conf) file that ships with the agent.
|
||||
|
||||
## Learn More
|
||||
|
|
|
|||
|
|
@ -34,7 +34,7 @@ of required setup.
|
|||
In this tutorial, you'll set up robust LAMP stack monitoring with Netdata in just a few minutes. When you're done,
|
||||
you'll have one dashboard to monitor every part of your web application, including each essential LAMP stack service.
|
||||
|
||||
This dashboard updates every second with new metrics, and pairs those metrics up with preconfigured alarms to keep you
|
||||
This dashboard updates every second with new metrics, and pairs those metrics up with preconfigured alerts to keep you
|
||||
informed of any errors or odd behavior.
|
||||
|
||||
## What you need to get started
|
||||
|
|
@ -192,18 +192,18 @@ Here's a quick reference for what charts you might want to focus on after settin
|
|||
| Active Connections (`mysql_local.connections_active`) | MySQL monitoring | If the `active` dimension nears the `limit`, your MySQL database will bottleneck responses. |
|
||||
| Performance (phpfpm_local.performance) | PHP monitoring | The `slow requests` dimension lets you know if any requests exceed the configured `request_slowlog_timeout`. If so, users might be having a less-than-ideal experience. |
|
||||
|
||||
## Get alarms for LAMP stack errors
|
||||
## Get alerts for LAMP stack errors
|
||||
|
||||
The Netdata Agent comes with hundreds of pre-configured alarms to help you keep tabs on your system, including 19 alarms
|
||||
The Netdata Agent comes with hundreds of pre-configured alerts to help you keep tabs on your system, including 19 alerts
|
||||
designed for smarter LAMP stack monitoring.
|
||||
|
||||
Click the 🔔 icon in the top navigation to [see active alarms](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alarms.md). The **Active** tabs
|
||||
shows any alarms currently triggered, while the **All** tab displays a list of _every_ pre-configured alarm. The
|
||||
Click the 🔔 icon in the top navigation to [see active alerts](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md). The **Active** tabs
|
||||
shows any alerts currently triggered, while the **All** tab displays a list of _every_ pre-configured alert. The
|
||||
|
||||
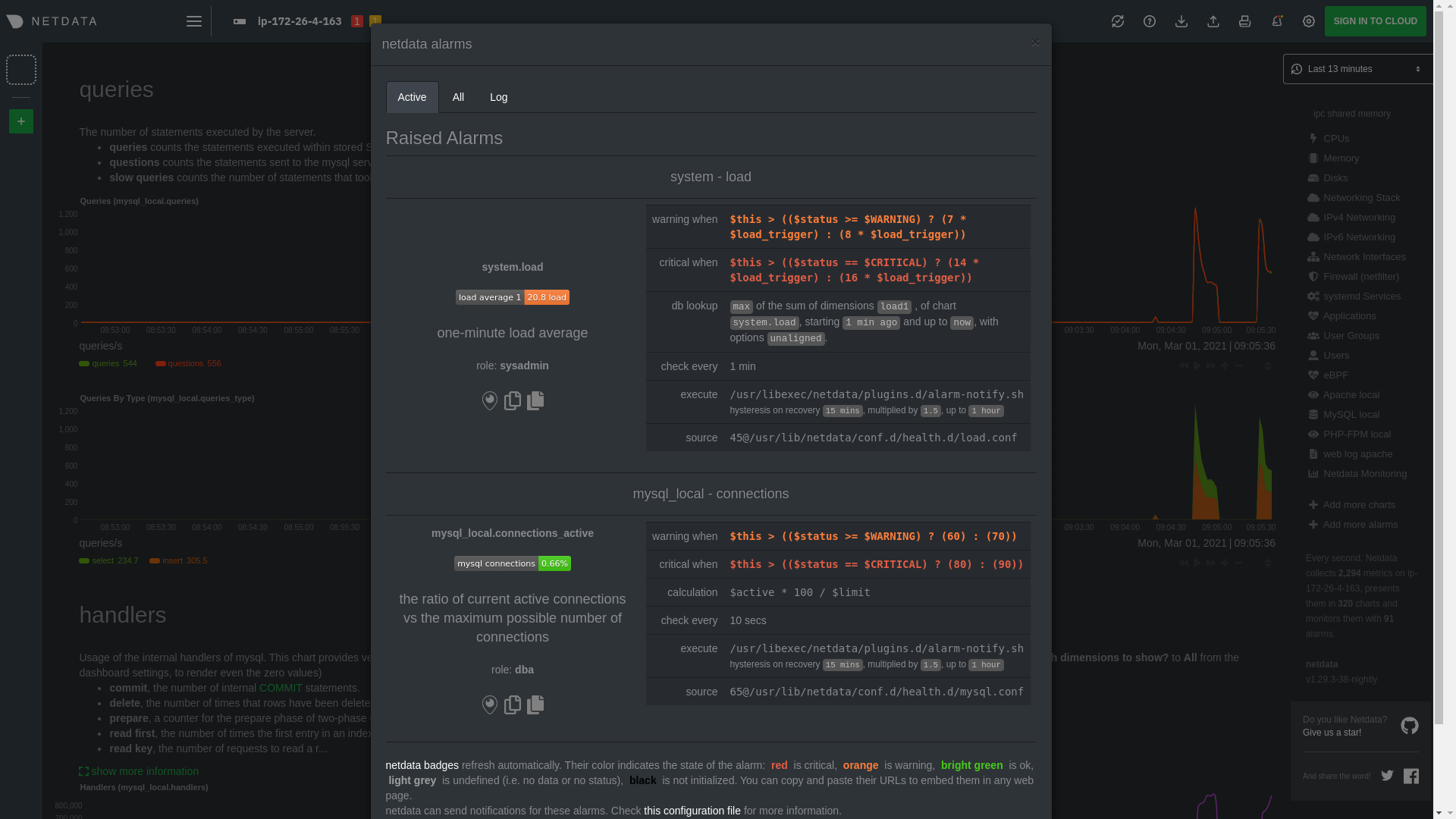
|
||||
alerts](https://user-images.githubusercontent.com/1153921/109524120-5883f900-7a6d-11eb-830e-0e7baaa28163.png)
|
||||
|
||||
[Tweak alarms](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) based on your infrastructure monitoring needs, and to see these alarms
|
||||
[Tweak alerts](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) based on your infrastructure monitoring needs, and to see these alerts
|
||||
in other places, like your inbox or a Slack channel, [enable a notification
|
||||
method](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md).
|
||||
|
||||
|
|
|
|||
|
|
@ -16,7 +16,7 @@ Golang is more performant, easier to maintain, and simpler for users since it do
|
|||
execute. Python plugins require Python on the machine to be executed. Netdata uses Go as the platform of choice for
|
||||
production-grade collectors.
|
||||
|
||||
We generally do not accept contributions of Python modules to the Github project netdata/netdata. If you write a Python collector and
|
||||
We generally do not accept contributions of Python modules to the GitHub project netdata/netdata. If you write a Python collector and
|
||||
want to make it available for other users, you should create the pull request in https://github.com/netdata/community.
|
||||
|
||||
## What you need to get started
|
||||
|
|
@ -540,7 +540,7 @@ At minimum, to be buildable and testable, the PR needs to include:
|
|||
- A makefile for the plugin at `collectors/python.d.plugin/<module_dir>/Makefile.inc`. Check an existing plugin for what this should look like.
|
||||
- A line in `collectors/python.d.plugin/Makefile.am` including the above-mentioned makefile. Place it with the other plugin includes (please keep the includes sorted alphabetically).
|
||||
- Optionally, chart information in `web/gui/dashboard_info.js`. This generally involves specifying a name and icon for the section, and may include descriptions for the section or individual charts.
|
||||
- Optionally, some default alarm configurations for your collector in `health/health.d/<module_name>.conf` and a line adding `<module_name>.conf` in `health/Makefile.am`.
|
||||
- Optionally, some default alert configurations for your collector in `health/health.d/<module_name>.conf` and a line adding `<module_name>.conf` in `health/Makefile.am`.
|
||||
|
||||
## Framework class reference
|
||||
|
||||
|
|
|
|||
|
|
@ -41,7 +41,7 @@ To define your windows server as a virtual node you need to:
|
|||
|
||||
Host labels can be extremely useful when:
|
||||
|
||||
- You need alarms that adapt to the system's purpose
|
||||
- You need alerts that adapt to the system's purpose
|
||||
- You need properly-labeled metrics archiving so you can sort, correlate, and mash-up your data to your heart's content.
|
||||
- You need to keep tabs on ephemeral Docker containers in a Kubernetes cluster.
|
||||
|
||||
|
|
@ -149,7 +149,7 @@ exporting. Speaking of which...
|
|||
### Host labels in alerts
|
||||
|
||||
You can use host labels to logically organize your systems by their type, purpose, or location, and then apply specific
|
||||
alarms to them.
|
||||
alerts to them.
|
||||
|
||||
For example, let's use configuration example from earlier:
|
||||
|
||||
|
|
@ -178,7 +178,7 @@ Or, by using one of the automatic labels, for only webserver systems running a s
|
|||
host labels: _os_name = Debian*
|
||||
```
|
||||
|
||||
In a streaming configuration where a parent node is triggering alarms for its child nodes, you could create health
|
||||
In a streaming configuration where a parent node is triggering alerts for its child nodes, you could create health
|
||||
entities that apply only to child nodes:
|
||||
|
||||
```yaml
|
||||
|
|
@ -192,7 +192,7 @@ Or when ephemeral Docker nodes are involved:
|
|||
```
|
||||
|
||||
Of course, there are many more possibilities for intuitively organizing your systems with host labels. See the [health
|
||||
documentation](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alarm-line-host-labels) for more details, and then get creative!
|
||||
documentation](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alert-line-host-labels) for more details, and then get creative!
|
||||
|
||||
### Host labels in metrics exporting
|
||||
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ replicate metrics data across multiple nodes, or centralize all your metrics dat
|
|||
(TSDB).
|
||||
|
||||
When one node streams metrics to another, the node receiving metrics can visualize them on the dashboard, run health checks to
|
||||
[trigger alarms](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alarms.md) and
|
||||
[trigger alerts](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md) and
|
||||
[send notifications](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md), and
|
||||
[export](https://github.com/netdata/netdata/blob/master/docs/export/external-databases.md) all metrics to an external TSDB. When Netdata streams metrics to another
|
||||
Netdata, the receiving one is able to perform everything a Netdata instance is capable of.
|
||||
|
|
@ -48,16 +48,16 @@ Here are a few example streaming configurations:
|
|||
- **Headless collector**:
|
||||
- Child `A`, _without_ a database or web dashboard, streams metrics to parent `B`.
|
||||
- `A` metrics are only available via the local Agent dashboard for `B`.
|
||||
- `B` generates alarms for `A`.
|
||||
- `B` generates alerts for `A`.
|
||||
- **Replication**:
|
||||
- Child `A`, _with_ a database and web dashboard, streams metrics to parent `B`.
|
||||
- `A` metrics are available on both local Agent dashboards, and can be stored with the same or different metrics
|
||||
retention policies.
|
||||
- Both `A` and `B` generate alarms.
|
||||
- Both `A` and `B` generate alerts.
|
||||
- **Proxy**:
|
||||
- Child `A`, _with or without_ a database, sends metrics to proxy `C`, also _with or without_ a database. `C` sends
|
||||
metrics to parent `B`.
|
||||
- Any node with a database can generate alarms.
|
||||
- Any node with a database can generate alerts.
|
||||
|
||||
|
||||
|
||||
|
|
@ -102,7 +102,7 @@ parent node, and both nodes retain metrics in their own databases.
|
|||
To configure replication, you need two nodes, each running Netdata. First you'll first enable streaming on your parent
|
||||
node, then enable streaming on your child node. When you're finished, you'll be able to see the child node's metrics in
|
||||
the parent node's dashboard, quickly switch between the two dashboards, and be able to serve
|
||||
[alarm notifications](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md) from either or both nodes.
|
||||
[alert notifications](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md) from either or both nodes.
|
||||
|
||||
### Enable streaming on the parent node
|
||||
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
<!--
|
||||
title: "Alert notifications"
|
||||
description: "Send Netdata alarms from a centralized place with Netdata Cloud, or configure nodes individually, to enable incident response and faster resolution."
|
||||
description: "Send Netdata alerts from a centralized place with Netdata Cloud, or configure nodes individually, to enable incident response and faster resolution."
|
||||
custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/monitor/enable-notifications.md"
|
||||
sidebar_label: "Notify"
|
||||
learn_status: "Published"
|
||||
|
|
|
|||
|
|
@ -43,28 +43,28 @@ At the bottom of the panel you can click the green button "View dedicated alert
|
|||
<!--
|
||||
## Local Netdata Agent dashboard
|
||||
|
||||
Find the alarms icon 
|
||||
in the top navigation to bring up a modal that shows currently raised alarms, all running alarms, and the alarms log.
|
||||
Here is an example of a raised `system.cpu` alarm, followed by the full list and alarm log:
|
||||
in the top navigation to bring up a modal that shows currently raised alerts, all running alerts, and the alerts log.
|
||||
Here is an example of a raised `system.cpu` alert, followed by the full list and alert log:
|
||||
|
||||
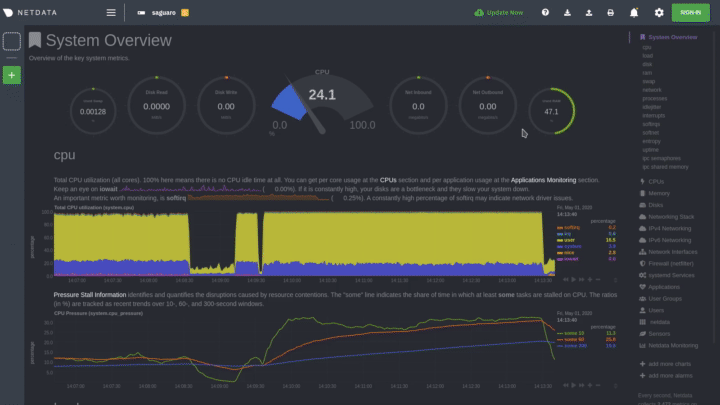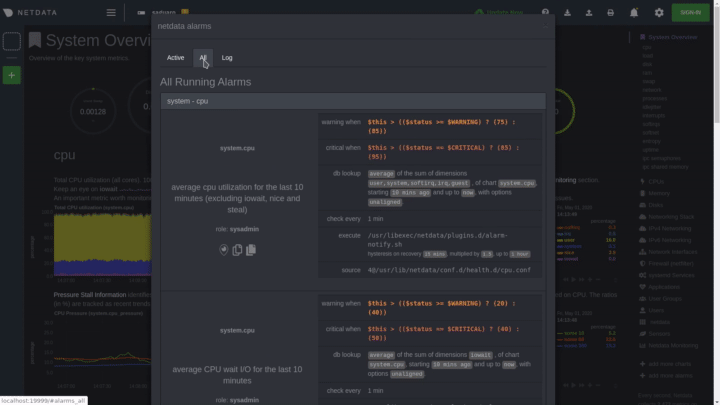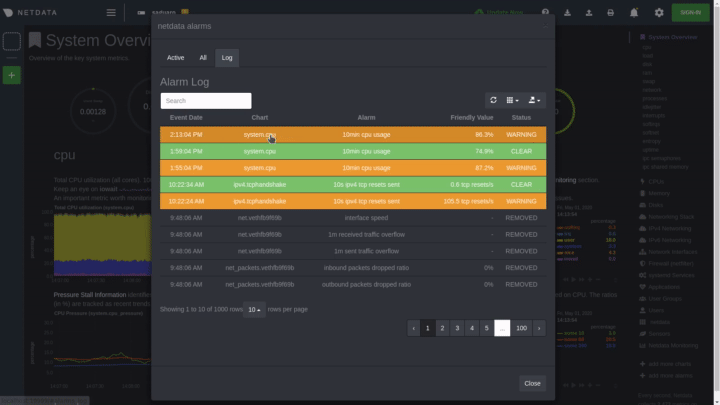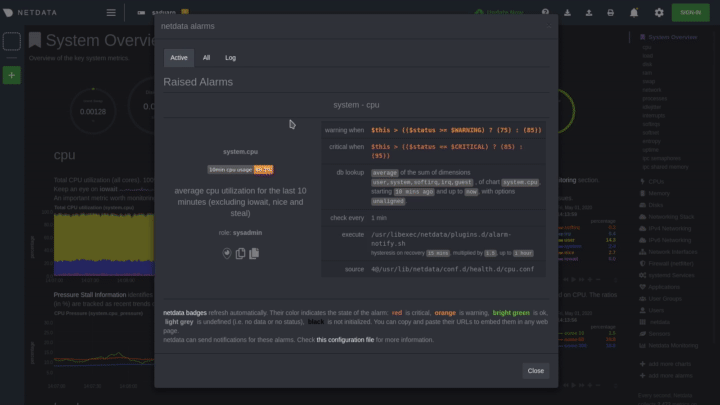
|
||||
|
||||
And a static screenshot of the raised CPU alarm:
|
||||
And a static screenshot of the raised CPU alert:
|
||||
|
||||
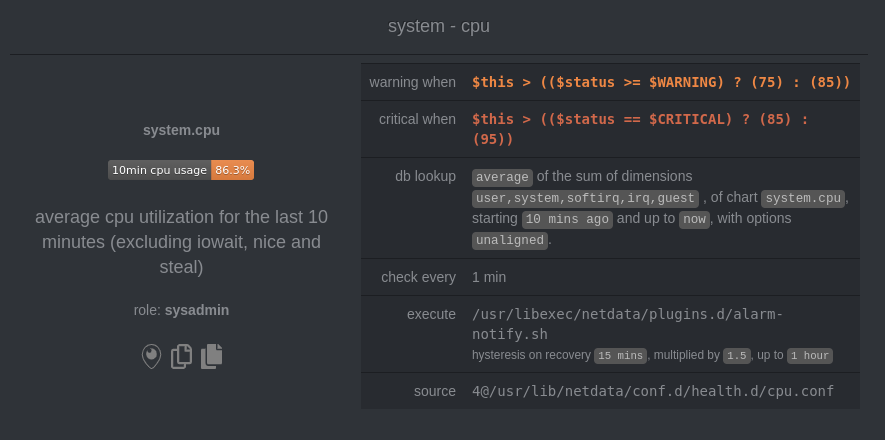
|
||||
alert](https://user-images.githubusercontent.com/1153921/80842330-2dfbb200-8bb6-11ea-8147-3cd366eb0f37.png)
|
||||
|
||||
The alarm itself is named **system - cpu**, and its context is `system.cpu`. Beneath that is an auto-updating badge that
|
||||
shows the latest value of the chart that triggered the alarm.
|
||||
The alert itself is named **system - cpu**, and its context is `system.cpu`. Beneath that is an auto-updating badge that
|
||||
shows the latest value of the chart that triggered the alert.
|
||||
|
||||
With the three icons beneath that and the **role** designation, you can:
|
||||
|
||||
1. Scroll to the chart associated with this raised alarm.
|
||||
1. Scroll to the chart associated with this raised alert.
|
||||
2. Copy a link to the badge to your clipboard.
|
||||
3. Copy the code to embed the badge onto another web page using an `<embed>` element.
|
||||
|
||||
The table on the right-hand side displays information about the health entity that triggered the alarm, which you can
|
||||
use as a reference to [configure alarms](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md).
|
||||
The table on the right-hand side displays information about the health entity that triggered the alert, which you can
|
||||
use as a reference to [configure alerts](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md).
|
||||
-->
|
||||
|
|
@ -3,7 +3,7 @@ import { RiExternalLinkLine } from 'react-icons/ri'
|
|||
|
||||
# Monitor your infrastructure
|
||||
|
||||
Learn how to view key metrics, insightful charts, and active alarms from all your nodes, with Netdata Cloud's real-time infrastructure monitoring.
|
||||
Learn how to view key metrics, insightful charts, and active alerts from all your nodes, with Netdata Cloud's real-time infrastructure monitoring.
|
||||
|
||||
[Netdata Cloud](https://app.netdata.cloud) provides scalable infrastructure monitoring for any number of distributed
|
||||
nodes running the Netdata Agent. A node is any system in your infrastructure that you want to monitor, whether it's a
|
||||
|
|
@ -20,7 +20,7 @@ between them, you can monitor your infrastructure using customizable, interactiv
|
|||
number of distributed nodes.
|
||||
|
||||
In this quickstart guide, you'll learn the basics of using Netdata Cloud to monitor an infrastructure with dashboards,
|
||||
composite charts, and alarm viewing. You'll then learn about the most critical ways to configure the Agent on each of
|
||||
composite charts, and alert viewing. You'll then learn about the most critical ways to configure the Agent on each of
|
||||
your nodes to maximize the value you get from Netdata.
|
||||
|
||||
This quickstart assumes you've [installed Netdata](https://github.com/netdata/netdata/edit/master/packaging/installer/README.md)
|
||||
|
|
@ -73,13 +73,13 @@ These tabs can be separated into "static", meaning they are by default presented
|
|||
|
||||
- The second and most important tab is the [Overview tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md#overview-and-single-node-view) which uses composite charts to display real-time metrics from every available node in a given War Room.
|
||||
|
||||
- The [Nodes tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/nodes.md) gives you the ability to see the status (offline or online), host details, alarm status and also a short overview of some key metrics from all your nodes at a glance.
|
||||
- The [Nodes tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/nodes.md) gives you the ability to see the status (offline or online), host details, alert status and also a short overview of some key metrics from all your nodes at a glance.
|
||||
|
||||
- [Kubernetes tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/kubernetes.md) is a logical grouping of charts regarding your Kubernetes clusters. It contains a subset of the charts available in the **Overview tab**.
|
||||
|
||||
- The [Dashboards tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md) gives you the ability to have tailored made views of specific/targeted interfaces for your infrastructure using any number of charts from any number of nodes.
|
||||
|
||||
- The [Alerts tab](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alarms.md) provides you with an overview for all the active alerts you receive for the nodes in this War Room, you can also see all the alerts that are configured to be triggered in any given moment.
|
||||
- The [Alerts tab](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md) provides you with an overview for all the active alerts you receive for the nodes in this War Room, you can also see all the alerts that are configured to be triggered in any given moment.
|
||||
|
||||
- The [Anomalies tab](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.md) is dedicated to the Anomaly Advisor tool.
|
||||
|
||||
|
|
@ -181,7 +181,7 @@ collect from across your infrastructure with Netdata.
|
|||
<Box
|
||||
title="Alerts and notifications">
|
||||
<BoxList>
|
||||
<BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alarms.md#netdata-cloud)" title="View active alerts" />
|
||||
<BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md#netdata-cloud)" title="View active alerts" />
|
||||
<BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.md)" title="Alert notifications" />
|
||||
</BoxList>
|
||||
</Box>
|
||||
|
|
@ -212,7 +212,7 @@ collect from across your infrastructure with Netdata.
|
|||
- [Kubernetes](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/kubernetes.md)
|
||||
- [Create new dashboards](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md)
|
||||
- Alerts and notifications
|
||||
- [View active alerts](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alarms.md#netdata-cloud)
|
||||
- [View active alerts](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md#netdata-cloud)
|
||||
- [Alert notifications](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.md)
|
||||
- Troubleshooting with Netdata Cloud
|
||||
- [Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md)
|
||||
|
|
|
|||
|
|
@ -68,8 +68,8 @@ When you use the database engine to store your metrics, you can always perform a
|
|||
|
||||
Netdata Cloud does not store metric values.
|
||||
|
||||
To enable certain features, such as [viewing active alarms](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alarms.md)
|
||||
To enable certain features, such as [viewing active alerts](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md)
|
||||
or [filtering by hostname](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/node-filter.md), Netdata Cloud does
|
||||
store configured alarms, their status, and a list of active collectors.
|
||||
store configured alerts, their status, and a list of active collectors.
|
||||
|
||||
Netdata does not and never will sell your personal data or data about your deployment.
|
||||
|
|
|
|||
|
|
@ -314,9 +314,9 @@ and performance of the exporting engine itself:
|
|||
|
||||

|
||||
|
||||
## Exporting engine alarms
|
||||
## Exporting engine alerts
|
||||
|
||||
Netdata adds 3 alarms:
|
||||
Netdata adds 3 alerts:
|
||||
|
||||
1. `exporting_last_buffering`, number of seconds since the last successful buffering of exported data
|
||||
2. `exporting_metrics_sent`, percentage of metrics sent to the external database server
|
||||
|
|
|
|||
|
|
@ -24,7 +24,7 @@ Each chart in Netdata has several properties (common to all its metrics):
|
|||
- `chart_name` - a more human friendly name for `chart_id`, also unique.
|
||||
|
||||
- `context` - this is the template of the chart. All disk I/O charts have the same context, all mysql requests charts
|
||||
have the same context, etc. This is used for alarm templates to match all the charts they should be attached to.
|
||||
have the same context, etc. This is used for alert templates to match all the charts they should be attached to.
|
||||
|
||||
- `family` groups a set of charts together. It is used as the submenu of the dashboard.
|
||||
|
||||
|
|
|
|||
|
|
@ -2,10 +2,10 @@
|
|||
|
||||
The Netdata Agent is a health watchdog for the health and performance of your systems, services, and applications. We've
|
||||
worked closely with our community of DevOps engineers, SREs, and developers to define hundreds of production-ready
|
||||
alarms that work without any configuration.
|
||||
alerts that work without any configuration.
|
||||
|
||||
The Agent's health monitoring system is also dynamic and fully customizable. You can write entirely new alarms, tune the
|
||||
community-configured alarms for every app/service [the Agent collects metrics from](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md), or
|
||||
The Agent's health monitoring system is also dynamic and fully customizable. You can write entirely new alerts, tune the
|
||||
community-configured alerts for every app/service [the Agent collects metrics from](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md), or
|
||||
silence anything you're not interested in. You can even power complex lookups by running statistical algorithms against
|
||||
your metrics.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,15 +1,15 @@
|
|||
# Configure alerts
|
||||
|
||||
Netdata's health watchdog is highly configurable, with support for dynamic thresholds, hysteresis, alarm templates, and
|
||||
more. You can tweak any of the existing alarms based on your infrastructure's topology or specific monitoring needs, or
|
||||
Netdata's health watchdog is highly configurable, with support for dynamic thresholds, hysteresis, alert templates, and
|
||||
more. You can tweak any of the existing alerts based on your infrastructure's topology or specific monitoring needs, or
|
||||
create new entities.
|
||||
|
||||
You can use health alarms in conjunction with any of Netdata's [collectors](https://github.com/netdata/netdata/blob/master/collectors/README.md) (see
|
||||
You can use health alerts in conjunction with any of Netdata's [collectors](https://github.com/netdata/netdata/blob/master/collectors/README.md) (see
|
||||
the [supported collector list](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md)) to monitor the health of your systems, containers, and
|
||||
applications in real time.
|
||||
|
||||
While you can see active alarms both on the local dashboard and Netdata Cloud, all health alarms are configured _per
|
||||
node_ via individual Netdata Agents. If you want to deploy a new alarm across your
|
||||
While you can see active alerts both on the local dashboard and Netdata Cloud, all health alerts are configured _per
|
||||
node_ via individual Netdata Agents. If you want to deploy a new alert across your
|
||||
[infrastructure](https://github.com/netdata/netdata/blob/master/docs/quickstart/infrastructure.md), you must configure each node with the same health configuration
|
||||
files.
|
||||
|
||||
|
|
@ -55,7 +55,7 @@ template: 10min_cpu_usage
|
|||
to: sysadmin
|
||||
```
|
||||
|
||||
To tune this alarm to trigger warning and critical alarms at a lower CPU utilization, change the `warn` and `crit` lines
|
||||
To tune this alert to trigger warning and critical alerts at a lower CPU utilization, change the `warn` and `crit` lines
|
||||
to the values of your choosing. For example:
|
||||
|
||||
```yaml
|
||||
|
|
@ -79,7 +79,7 @@ In the `netdata.conf` `[health]` section, set `enabled` to `no`, and restart the
|
|||
|
||||
In the `netdata.conf` `[health]` section, set `enabled alarms` to a
|
||||
[simple pattern](https://github.com/netdata/netdata/edit/master/libnetdata/simple_pattern/README.md) that
|
||||
excludes one or more alerts. e.g. `enabled alarms = !oom_kill *` will load all alarms except `oom_kill`.
|
||||
excludes one or more alerts. e.g. `enabled alarms = !oom_kill *` will load all alerts except `oom_kill`.
|
||||
|
||||
You can also [edit the file where the alert is defined](#edit-individual-alerts), comment out its definition,
|
||||
and [reload Netdata's health configuration](#reload-health-configuration).
|
||||
|
|
@ -112,7 +112,7 @@ or restarting the agent.
|
|||
|
||||
## Write a new health entity
|
||||
|
||||
While tuning existing alarms may work in some cases, you may need to write entirely new health entities based on how
|
||||
While tuning existing alerts may work in some cases, you may need to write entirely new health entities based on how
|
||||
your systems, containers, and applications work.
|
||||
|
||||
Read the [health entity reference](#health-entity-reference) for a full listing of the format,
|
||||
|
|
@ -128,8 +128,8 @@ sudo touch health.d/ram-usage.conf
|
|||
sudo ./edit-config health.d/ram-usage.conf
|
||||
```
|
||||
|
||||
For example, here is a health entity that triggers a warning alarm when a node's RAM usage rises above 80%, and a
|
||||
critical alarm above 90%:
|
||||
For example, here is a health entity that triggers a warning alert when a node's RAM usage rises above 80%, and a
|
||||
critical alert above 90%:
|
||||
|
||||
```yaml
|
||||
alarm: ram_usage
|
||||
|
|
@ -151,7 +151,7 @@ Let's look into each of the lines to see how they create a working health entity
|
|||
|
||||
- `on`: Which chart the entity listens to.
|
||||
|
||||
- `lookup`: Which metrics the alarm monitors, the duration of time to monitor, and how to process the metrics into a
|
||||
- `lookup`: Which metrics the alert monitors, the duration of time to monitor, and how to process the metrics into a
|
||||
usable format.
|
||||
- `average`: Calculate the average of all the metrics collected.
|
||||
- `-1m`: Use metrics from 1 minute ago until now to calculate that average.
|
||||
|
|
@ -160,13 +160,13 @@ Let's look into each of the lines to see how they create a working health entity
|
|||
|
||||
- `units`: Use percentages rather than absolute units.
|
||||
|
||||
- `every`: How often to perform the `lookup` calculation to decide whether or not to trigger this alarm.
|
||||
- `every`: How often to perform the `lookup` calculation to decide whether to trigger this alert.
|
||||
|
||||
- `warn`/`crit`: The value at which Netdata should trigger a warning or critical alarm. This example uses simple
|
||||
- `warn`/`crit`: The value at which Netdata should trigger a warning or critical alert. This example uses simple
|
||||
syntax, but most pre-configured health entities use
|
||||
[hysteresis](#special-use-of-the-conditional-operator) to avoid superfluous notifications.
|
||||
|
||||
- `info`: A description of the alarm, which will appear in the dashboard and notifications.
|
||||
- `info`: A description of the alert, which will appear in the dashboard and notifications.
|
||||
|
||||
In human-readable format:
|
||||
|
||||
|
|
@ -174,8 +174,8 @@ In human-readable format:
|
|||
> metrics from the **used** dimension and calculates the **average** of all those metrics in a **percentage** format,
|
||||
> using a **% unit**. The entity performs this lookup **every minute**.
|
||||
>
|
||||
> If the average RAM usage percentage over the last 1 minute is **more than 80%**, the entity triggers a warning alarm.
|
||||
> If the usage is **more than 90%**, the entity triggers a critical alarm.
|
||||
> If the average RAM usage percentage over the last 1 minute is **more than 80%**, the entity triggers a warning alert.
|
||||
> If the usage is **more than 90%**, the entity triggers a critical alert.
|
||||
|
||||
When you finish writing this new health entity, [reload Netdata's health configuration](#reload-health-configuration) to
|
||||
see it live on the local dashboard or Netdata Cloud.
|
||||
|
|
@ -188,20 +188,20 @@ without restarting all of Netdata, run `netdatacli reload-health` or `killall -U
|
|||
## Health entity reference
|
||||
|
||||
The following reference contains information about the syntax and options of _health entities_, which Netdata attaches
|
||||
to charts in order to trigger alarms.
|
||||
to charts in order to trigger alerts.
|
||||
|
||||
### Entity types
|
||||
|
||||
There are two entity types: **alarms** and **templates**. They have the same format and feature set—the only difference
|
||||
is their label.
|
||||
|
||||
**Alarms** are attached to specific charts and use the `alarm` label.
|
||||
**Alerts** are attached to specific charts and use the `alarm` label.
|
||||
|
||||
**Templates** define rules that apply to all charts of a specific context, and use the `template` label. Templates help
|
||||
you apply one entity to all disks, all network interfaces, all MySQL databases, and so on.
|
||||
|
||||
Alarms have higher precedence and will override templates. If an alarm and template entity have the same name and attach
|
||||
to the same chart, Netdata will use the alarm.
|
||||
Alerts have higher precedence and will override templates.
|
||||
If the `alert` and `template` entities have the same name and are attached to the same chart, Netdata will use `alarm`.
|
||||
|
||||
### Entity format
|
||||
|
||||
|
|
@ -219,39 +219,39 @@ Netdata parses the following lines. Beneath the table is an in-depth explanation
|
|||
This comes in handy if your `info` line consists of several sentences.
|
||||
|
||||
| line | required | functionality |
|
||||
| --------------------------------------------------- | --------------- | ------------------------------------------------------------------------------------- |
|
||||
| [`alarm`/`template`](#alarm-line-alarm-or-template) | yes | Name of the alarm/template. |
|
||||
| [`on`](#alarm-line-on) | yes | The chart this alarm should attach to. |
|
||||
| [`class`](#alarm-line-class) | no | The general alarm classification. |
|
||||
| [`type`](#alarm-line-type) | no | What area of the system the alarm monitors. |
|
||||
| [`component`](#alarm-line-component) | no | Specific component of the type of the alarm. |
|
||||
| [`os`](#alarm-line-os) | no | Which operating systems to run this chart. |
|
||||
| [`hosts`](#alarm-line-hosts) | no | Which hostnames will run this alarm. |
|
||||
| [`plugin`](#alarm-line-plugin) | no | Restrict an alarm or template to only a certain plugin. |
|
||||
| [`module`](#alarm-line-module) | no | Restrict an alarm or template to only a certain module. |
|
||||
| [`charts`](#alarm-line-charts) | no | Restrict an alarm or template to only certain charts. |
|
||||
| [`families`](#alarm-line-families) | no | Restrict a template to only certain families. |
|
||||
| [`lookup`](#alarm-line-lookup) | yes | The database lookup to find and process metrics for the chart specified through `on`. |
|
||||
| [`calc`](#alarm-line-calc) | yes (see above) | A calculation to apply to the value found via `lookup` or another variable. |
|
||||
| [`every`](#alarm-line-every) | no | The frequency of the alarm. |
|
||||
| [`green`/`red`](#alarm-lines-green-and-red) | no | Set the green and red thresholds of a chart. |
|
||||
| [`warn`/`crit`](#alarm-lines-warn-and-crit) | yes (see above) | Expressions evaluating to true or false, and when true, will trigger the alarm. |
|
||||
| [`to`](#alarm-line-to) | no | A list of roles to send notifications to. |
|
||||
| [`exec`](#alarm-line-exec) | no | The script to execute when the alarm changes status. |
|
||||
| [`delay`](#alarm-line-delay) | no | Optional hysteresis settings to prevent floods of notifications. |
|
||||
| [`repeat`](#alarm-line-repeat) | no | The interval for sending notifications when an alarm is in WARNING or CRITICAL mode. |
|
||||
| [`options`](#alarm-line-options) | no | Add an option to not clear alarms. |
|
||||
| [`host labels`](#alarm-line-host-labels) | no | Restrict an alarm or template to a list of matching labels present on a host. |
|
||||
| [`chart labels`](#alarm-line-chart-labels) | no | Restrict an alarm or template to a list of matching labels present on a host. |
|
||||
| [`info`](#alarm-line-info) | no | A brief description of the alarm. |
|
||||
|-----------------------------------------------------|-----------------|---------------------------------------------------------------------------------------|
|
||||
| [`alarm`/`template`](#alert-line-alarm-or-template) | yes | Name of the alert/template. |
|
||||
| [`on`](#alert-line-on) | yes | The chart this alert should attach to. |
|
||||
| [`class`](#alert-line-class) | no | The general alert classification. |
|
||||
| [`type`](#alert-line-type) | no | What area of the system the alert monitors. |
|
||||
| [`component`](#alert-line-component) | no | Specific component of the type of the alert. |
|
||||
| [`os`](#alert-line-os) | no | Which operating systems to run this chart. |
|
||||
| [`hosts`](#alert-line-hosts) | no | Which hostnames will run this alert. |
|
||||
| [`plugin`](#alert-line-plugin) | no | Restrict an alert or template to only a certain plugin. |
|
||||
| [`module`](#alert-line-module) | no | Restrict an alert or template to only a certain module. |
|
||||
| [`charts`](#alert-line-charts) | no | Restrict an alert or template to only certain charts. |
|
||||
| [`families`](#alert-line-families) | no | Restrict a template to only certain families. |
|
||||
| [`lookup`](#alert-line-lookup) | yes | The database lookup to find and process metrics for the chart specified through `on`. |
|
||||
| [`calc`](#alert-line-calc) | yes (see above) | A calculation to apply to the value found via `lookup` or another variable. |
|
||||
| [`every`](#alert-line-every) | no | The frequency of the alert. |
|
||||
| [`green`/`red`](#alert-lines-green-and-red) | no | Set the green and red thresholds of a chart. |
|
||||
| [`warn`/`crit`](#alert-lines-warn-and-crit) | yes (see above) | Expressions evaluating to true or false, and when true, will trigger the alert. |
|
||||
| [`to`](#alert-line-to) | no | A list of roles to send notifications to. |
|
||||
| [`exec`](#alert-line-exec) | no | The script to execute when the alert changes status. |
|
||||
| [`delay`](#alert-line-delay) | no | Optional hysteresis settings to prevent floods of notifications. |
|
||||
| [`repeat`](#alert-line-repeat) | no | The interval for sending notifications when an alert is in WARNING or CRITICAL mode. |
|
||||
| [`options`](#alert-line-options) | no | Add an option to not clear alerts. |
|
||||
| [`host labels`](#alert-line-host-labels) | no | Restrict an alert or template to a list of matching labels present on a host. |
|
||||
| [`chart labels`](#alert-line-chart-labels) | no | Restrict an alert or template to a list of matching labels present on a host. |
|
||||
| [`info`](#alert-line-info) | no | A brief description of the alert. |
|
||||
|
||||
The `alarm` or `template` line must be the first line of any entity.
|
||||
|
||||
#### Alarm line `alarm` or `template`
|
||||
#### Alert line `alarm` or `template`
|
||||
|
||||
This line starts an alarm or template based on the [entity type](#entity-types) you're interested in creating.
|
||||
This line starts an alert or template based on the [entity type](#entity-types) you're interested in creating.
|
||||
|
||||
**Alarm:**
|
||||
**Alert:**
|
||||
|
||||
```yaml
|
||||
alarm: NAME
|
||||
|
|
@ -266,11 +266,11 @@ template: NAME
|
|||
`NAME` can be any alpha character, with `.` (period) and `_` (underscore) as the only allowed symbols, but the names
|
||||
cannot be `chart name`, `dimension name`, `family name`, or `chart variables names`.
|
||||
|
||||
#### Alarm line `on`
|
||||
#### Alert line `on`
|
||||
|
||||
This line defines the chart this alarm should attach to.
|
||||
This line defines the chart this alert should attach to.
|
||||
|
||||
**Alarms:**
|
||||
**Alerts:**
|
||||
|
||||
```yaml
|
||||
on: CHART
|
||||
|
|
@ -297,40 +297,40 @@ shows a disk I/O chart, the tooltip reads: `proc:/proc/diskstats, disk.io`.
|
|||
|
||||
You're interested in what comes after the comma: `disk.io`. That's the name of the chart's context.
|
||||
|
||||
If you create a template using the `disk.io` context, it will apply an alarm to every disk available on your system.
|
||||
If you create a template using the `disk.io` context, it will apply an alert to every disk available on your system.
|
||||
|
||||
#### Alarm line `class`
|
||||
#### Alert line `class`
|
||||
|
||||
This indicates the type of error (or general problem area) that the alarm or template applies to. For example, `Latency` can be used for alarms that trigger on latency issues on network interfaces, web servers, or database systems. Example:
|
||||
This indicates the type of error (or general problem area) that the alert or template applies to. For example, `Latency` can be used for alerts that trigger on latency issues on network interfaces, web servers, or database systems. Example:
|
||||
|
||||
```yaml
|
||||
class: Latency
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>Netdata's stock alarms use the following `class` attributes by default:</summary>
|
||||
<summary>Netdata's stock alerts use the following `class` attributes by default:</summary>
|
||||
|
||||
| Class |
|
||||
| ----------------|
|
||||
| Errors |
|
||||
| Latency |
|
||||
| Utilization |
|
||||
| Workload |
|
||||
| Class |
|
||||
|-------------|
|
||||
| Errors |
|
||||
| Latency |
|
||||
| Utilization |
|
||||
| Workload |
|
||||
|
||||
</details>
|
||||
|
||||
`class` will default to `Unknown` if the line is missing from the alarm configuration.
|
||||
`class` will default to `Unknown` if the line is missing from the alert configuration.
|
||||
|
||||
#### Alarm line `type`
|
||||
#### Alert line `type`
|
||||
|
||||
Type can be used to indicate the broader area of the system that the alarm applies to. For example, under the general `Database` type, you can group together alarms that operate on various database systems, like `MySQL`, `CockroachDB`, `CouchDB` etc. Example:
|
||||
Type can be used to indicate the broader area of the system that the alert applies to. For example, under the general `Database` type, you can group together alerts that operate on various database systems, like `MySQL`, `CockroachDB`, `CouchDB` etc. Example:
|
||||
|
||||
```yaml
|
||||
type: Database
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>Netdata's stock alarms use the following `type` attributes by default, but feel free to adjust for your own requirements.</summary>
|
||||
<summary>Netdata's stock alerts use the following `type` attributes by default, but feel free to adjust for your own requirements.</summary>
|
||||
|
||||
| Type | Description |
|
||||
|-----------------|------------------------------------------------------------------------------------------------|
|
||||
|
|
@ -352,7 +352,7 @@ type: Database
|
|||
| Power Supply | Alerts from power supply related services (e.g. apcupsd) |
|
||||
| Search engine | Alerts for search services (e.g. elasticsearch) |
|
||||
| Storage | Class for alerts dealing with storage services (storage devices typically live under `System`) |
|
||||
| System | General system alarms (e.g. cpu, network, etc.) |
|
||||
| System | General system alerts (e.g. cpu, network, etc.) |
|
||||
| Virtual Machine | Virtual Machine software |
|
||||
| Web Proxy | Web proxy software (e.g. squid) |
|
||||
| Web Server | Web server software (e.g. Apache, ngnix, etc.) |
|
||||
|
|
@ -360,11 +360,11 @@ type: Database
|
|||
|
||||
</details>
|
||||
|
||||
If an alarm configuration is missing the `type` line, its value will default to `Unknown`.
|
||||
If an alert configuration is missing the `type` line, its value will default to `Unknown`.
|
||||
|
||||
#### Alarm line `component`
|
||||
#### Alert line `component`
|
||||
|
||||
Component can be used to narrow down what the previous `type` value specifies for each alarm or template. Continuing from the previous example, `component` might include `MySQL`, `CockroachDB`, `MongoDB`, all under the same `Database` type. Example:
|
||||
Component can be used to narrow down what the previous `type` value specifies for each alert or template. Continuing from the previous example, `component` might include `MySQL`, `CockroachDB`, `MongoDB`, all under the same `Database` type. Example:
|
||||
|
||||
```yaml
|
||||
component: MySQL
|
||||
|
|
@ -372,9 +372,9 @@ component: MySQL
|
|||
|
||||
As with the `class` and `type` line, if `component` is missing from the configuration, its value will default to `Unknown`.
|
||||
|
||||
#### Alarm line `os`
|
||||
#### Alert line `os`
|
||||
|
||||
The alarm or template will be used only if the operating system of the host matches this list specified in `os`. The
|
||||
The alert or template will be used only if the operating system of the host matches this list specified in `os`. The
|
||||
value is a space-separated list.
|
||||
|
||||
The following example enables the entity on Linux, FreeBSD, and macOS, but no other operating systems.
|
||||
|
|
@ -383,9 +383,9 @@ The following example enables the entity on Linux, FreeBSD, and macOS, but no ot
|
|||
os: linux freebsd macos
|
||||
```
|
||||
|
||||
#### Alarm line `hosts`
|
||||
#### Alert line `hosts`
|
||||
|
||||
The alarm or template will be used only if the hostname of the host matches this space-separated list.
|
||||
The alert or template will be used only if the hostname of the host matches this space-separated list.
|
||||
|
||||
The following example will load on systems with the hostnames `server` and `server2`, and any system with hostnames that
|
||||
begin with `database`. It _will not load_ on the host `redis3`, but will load on any _other_ systems with hostnames that
|
||||
|
|
@ -395,47 +395,47 @@ begin with `redis`.
|
|||
hosts: server1 server2 database* !redis3 redis*
|
||||
```
|
||||
|
||||
#### Alarm line `plugin`
|
||||
#### Alert line `plugin`
|
||||
|
||||
The `plugin` line filters which plugin within the context this alarm should apply to. The value is a space-separated
|
||||
The `plugin` line filters which plugin within the context this alert should apply to. The value is a space-separated
|
||||
list of [simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md). For example,
|
||||
you can create a filter for an alarm that applies specifically to `python.d.plugin`:
|
||||
you can create a filter for an alert that applies specifically to `python.d.plugin`:
|
||||
|
||||
```yaml
|
||||
plugin: python.d.plugin
|
||||
```
|
||||
|
||||
The `plugin` line is best used with other options like `module`. When used alone, the `plugin` line creates a very
|
||||
inclusive filter that is unlikely to be of much use in production. See [`module`](#alarm-line-module) for a
|
||||
inclusive filter that is unlikely to be of much use in production. See [`module`](#alert-line-module) for a
|
||||
comprehensive example using both.
|
||||
|
||||
#### Alarm line `module`
|
||||
#### Alert line `module`
|
||||
|
||||
The `module` line filters which module within the context this alarm should apply to. The value is a space-separated
|
||||
The `module` line filters which module within the context this alert should apply to. The value is a space-separated
|
||||
list of [simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md). For
|
||||
example, you can create an alarm that applies only on the `isc_dhcpd` module started by `python.d.plugin`:
|
||||
example, you can create an alert that applies only on the `isc_dhcpd` module started by `python.d.plugin`:
|
||||
|
||||
```yaml
|
||||
plugin: python.d.plugin
|
||||
module: isc_dhcpd
|
||||
```
|
||||
|
||||
#### Alarm line `charts`
|
||||
#### Alert line `charts`
|
||||
|
||||
The `charts` line filters which chart this alarm should apply to. It is only available on entities using the
|
||||
[`template`](#alarm-line-alarm-or-template) line.
|
||||
The `charts` line filters which chart this alert should apply to. It is only available on entities using the
|
||||
[`template`](#alert-line-alarm-or-template) line.
|
||||
The value is a space-separated list of [simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md). For
|
||||
example, a template that applies to `disk.svctm` (Average Service Time) context, but excludes the disk `sdb` from alarms:
|
||||
example, a template that applies to `disk.svctm` (Average Service Time) context, but excludes the disk `sdb` from alerts:
|
||||
|
||||
```yaml
|
||||
template: disk_svctm_alarm
|
||||
template: disk_svctm_alert
|
||||
on: disk.svctm
|
||||
charts: !*sdb* *
|
||||
```
|
||||
|
||||
#### Alarm line `families`
|
||||
#### Alert line `families`
|
||||
|
||||
The `families` line, used only alongside templates, filters which families within the context this alarm should apply
|
||||
The `families` line, used only alongside templates, filters which families within the context this alert should apply
|
||||
to. The value is a space-separated list.
|
||||
|
||||
The value is a space-separate list of simple patterns. See our [simple patterns docs](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) for
|
||||
|
|
@ -448,9 +448,9 @@ families: sda sdb
|
|||
```
|
||||
|
||||
Please note that the use of the `families` filter is planned to be deprecated in upcoming Netdata releases.
|
||||
Please use [`chart labels`](#alarm-line-chart-labels) instead.
|
||||
Please use [`chart labels`](#alert-line-chart-labels) instead.
|
||||
|
||||
#### Alarm line `lookup`
|
||||
#### Alert line `lookup`
|
||||
|
||||
This line makes a database lookup to find a value. This result of this lookup is available as `$this`.
|
||||
|
||||
|
|
@ -485,17 +485,17 @@ The full [database query API](https://github.com/netdata/netdata/blob/master/web
|
|||
`,` or `|` instead of spaces)_ and the `match-ids` and `match-names` options affect the searches
|
||||
for dimensions.
|
||||
|
||||
- `foreach DIMENSIONS` is optional and works only with [templates](#alarm-line-alarm-or-template), will always be the last parameter, and uses the same `,`/`|`
|
||||
- `foreach DIMENSIONS` is optional and works only with [templates](#alert-line-alarm-or-template), will always be the last parameter, and uses the same `,`/`|`
|
||||
rules as the `of` parameter. Each dimension you specify in `foreach` will use the same rule
|
||||
to trigger an alarm. If you set both `of` and `foreach`, Netdata will ignore the `of` parameter
|
||||
to trigger an alert. If you set both `of` and `foreach`, Netdata will ignore the `of` parameter
|
||||
and replace it with one of the dimensions you gave to `foreach`. This option allows you to
|
||||
[use dimension templates to create dynamic alarms](#use-dimension-templates-to-create-dynamic-alarms).
|
||||
[use dimension templates to create dynamic alerts](#use-dimension-templates-to-create-dynamic-alerts).
|
||||
|
||||
The result of the lookup will be available as `$this` and `$NAME` in expressions.
|
||||
The timestamps of the timeframe evaluated by the database lookup is available as variables
|
||||
`$after` and `$before` (both are unix timestamps).
|
||||
|
||||
#### Alarm line `calc`
|
||||
#### Alert line `calc`
|
||||
|
||||
A `calc` is designed to apply some calculation to the values or variables available to the entity. The result of the
|
||||
calculation will be made available at the `$this` variable, overwriting the value from your `lookup`, to use in warning
|
||||
|
|
@ -512,9 +512,9 @@ The `calc` line uses [expressions](#expressions) for its syntax.
|
|||
calc: EXPRESSION
|
||||
```
|
||||
|
||||
#### Alarm line `every`
|
||||
#### Alert line `every`
|
||||
|
||||
Sets the update frequency of this alarm. This is the same to the `every DURATION` given
|
||||
Sets the update frequency of this alert. This is the same to the `every DURATION` given
|
||||
in the `lookup` lines.
|
||||
|
||||
Format:
|
||||
|
|
@ -525,11 +525,11 @@ every: DURATION
|
|||
|
||||
`DURATION` accepts `s` for seconds, `m` is minutes, `h` for hours, `d` for days.
|
||||
|
||||
#### Alarm lines `green` and `red`
|
||||
#### Alert lines `green` and `red`
|
||||
|
||||
Set the green and red thresholds of a chart. Both are available as `$green` and `$red` in expressions. If multiple
|
||||
alarms define different thresholds, the ones defined by the first alarm will be used. These will eventually visualized
|
||||
on the dashboard, so only one set of them is allowed. If you need multiple sets of them in different alarms, use
|
||||
alerts define different thresholds, the ones defined by the first alert will be used. Eventually it will be visualized
|
||||
on the dashboard, so only one set of them is allowed If you need multiple sets of them in different alerts, use
|
||||
absolute numbers instead of `$red` and `$green`.
|
||||
|
||||
Format:
|
||||
|
|
@ -539,9 +539,9 @@ green: NUMBER
|
|||
red: NUMBER
|
||||
```
|
||||
|
||||
#### Alarm lines `warn` and `crit`
|
||||
#### Alert lines `warn` and `crit`
|
||||
|
||||
Define the expression that triggers either a warning or critical alarm. These are optional, and should evaluate to
|
||||
Define the expression that triggers either a warning or critical alert. These are optional, and should evaluate to
|
||||
either true or false (or zero/non-zero).
|
||||
|
||||
The format uses Netdata's [expressions syntax](#expressions).
|
||||
|
|
@ -551,9 +551,9 @@ warn: EXPRESSION
|
|||
crit: EXPRESSION
|
||||
```
|
||||
|
||||
#### Alarm line `to`
|
||||
#### Alert line `to`
|
||||
|
||||
This will be the first parameter of the script to be executed when the alarm switches status. Its meaning is left up to
|
||||
This will be the first script parameter that will be executed when the alert changes its status. Its meaning is left up to
|
||||
the `exec` script.
|
||||
|
||||
The default `exec` script, `alarm-notify.sh`, uses this field as a space separated list of roles, which are then
|
||||
|
|
@ -565,9 +565,9 @@ Format:
|
|||
to: ROLE1 ROLE2 ROLE3 ...
|
||||
```
|
||||
|
||||
#### Alarm line `exec`
|
||||
#### Alert line `exec`
|
||||
|
||||
The script that will be executed when the alarm changes status.
|
||||
Script to be executed when the alert status changes.
|
||||
|
||||
Format:
|
||||
|
||||
|
|
@ -578,10 +578,10 @@ exec: SCRIPT
|
|||
The default `SCRIPT` is Netdata's `alarm-notify.sh`, which supports all the notifications methods Netdata supports,
|
||||
including custom hooks.
|
||||
|
||||
#### Alarm line `delay`
|
||||
#### Alert line `delay`
|
||||
|
||||
This is used to provide optional hysteresis settings for the notifications, to defend against notification floods. These
|
||||
settings do not affect the actual alarm - only the time the `exec` script is executed.
|
||||
settings do not affect the actual alert - only the time the `exec` script is executed.
|
||||
|
||||
Format:
|
||||
|
||||
|
|
@ -589,45 +589,45 @@ Format:
|
|||
delay: [[[up U] [down D] multiplier M] max X]
|
||||
```
|
||||
|
||||
- `up U` defines the delay to be applied to a notification for an alarm that raised its status
|
||||
- `up U` defines the delay to be applied to a notification for an alert that raised its status
|
||||
(i.e. CLEAR to WARNING, CLEAR to CRITICAL, WARNING to CRITICAL). For example, `up 10s`, the
|
||||
notification for this event will be sent 10 seconds after the actual event. This is used in
|
||||
hope the alarm will get back to its previous state within the duration given. The default `U`
|
||||
hope the alert will get back to its previous state within the duration given. The default `U`
|
||||
is zero.
|
||||
|
||||
- `down D` defines the delay to be applied to a notification for an alarm that moves to lower
|
||||
- `down D` defines the delay to be applied to a notification for an alert that moves to lower
|
||||
state (i.e. CRITICAL to WARNING, CRITICAL to CLEAR, WARNING to CLEAR). For example, `down 1m`
|
||||
will delay the notification by 1 minute. This is used to prevent notifications for flapping
|
||||
alarms. The default `D` is zero.
|
||||
alerts. The default `D` is zero.
|
||||
|
||||
- `multiplier M` multiplies `U` and `D` when an alarm changes state, while a notification is
|
||||
- `multiplier M` multiplies `U` and `D` when an alert changes state, while a notification is
|
||||
delayed. The default multiplier is `1.0`.
|
||||
|
||||
- `max X` defines the maximum absolute notification delay an alarm may get. The default `X`
|
||||
- `max X` defines the maximum absolute notification delay an alert may get. The default `X`
|
||||
is `max(U * M, D * M)` (i.e. the max duration of `U` or `D` multiplied once with `M`).
|
||||
|
||||
Example:
|
||||
|
||||
`delay: up 10s down 15m multiplier 2 max 1h`
|
||||
|
||||
The time is `00:00:00` and the status of the alarm is CLEAR.
|
||||
The time is `00:00:00` and the status of the alert is CLEAR.
|
||||
|
||||
| time of event | new status | delay | notification will be sent | why |
|
||||
| ------------- | ---------- | --- | ------------------------- | --- |
|
||||
|---------------|------------|---------------------|---------------------------|-------------------------------------------------------------------------------|
|
||||
| 00:00:01 | WARNING | `up 10s` | 00:00:11 | first state switch |
|
||||
| 00:00:05 | CLEAR | `down 15m x2` | 00:30:05 | the alarm changes state while a notification is delayed, so it was multiplied |
|
||||
| 00:00:05 | CLEAR | `down 15m x2` | 00:30:05 | the alert changes state while a notification is delayed, so it was multiplied |
|
||||
| 00:00:06 | WARNING | `up 10s x2 x2` | 00:00:26 | multiplied twice |
|
||||
| 00:00:07 | CLEAR | `down 15m x2 x2 x2` | 00:45:07 | multiplied 3 times. |
|
||||
|
||||
So:
|
||||
|
||||
- `U` and `D` are multiplied by `M` every time the alarm changes state (any state, not just
|
||||
- `U` and `D` are multiplied by `M` every time the alert changes state (any state, not just
|
||||
their matching one) and a delay is in place.
|
||||
- All are reset to their defaults when the alarm switches state without a delay in place.
|
||||
- All are reset to their defaults when the alert switches state without a delay in place.
|
||||
|
||||
#### Alarm line `repeat`
|
||||
#### Alert line `repeat`
|
||||
|
||||
Defines the interval between repeating notifications for the alarms in CRITICAL or WARNING mode. This will override the
|
||||
Defines the interval between repeating notifications for the alerts in CRITICAL or WARNING mode. This will override the
|
||||
default interval settings inherited from health settings in `netdata.conf`. The default settings for repeating
|
||||
notifications are `default repeat warning = DURATION` and `default repeat critical = DURATION` which can be found in
|
||||
health stock configuration, when one of these interval is bigger than 0, Netdata will activate the repeat notification
|
||||
|
|
@ -639,14 +639,14 @@ Format:
|
|||
repeat: [off] [warning DURATION] [critical DURATION]
|
||||
```
|
||||
|
||||
- `off`: Turns off the repeating feature for the current alarm. This is effective when the default repeat settings has
|
||||
- `off`: Turns off the repeating feature for the current alert. This is effective when the default repeat settings has
|
||||
been enabled in health configuration.
|
||||
- `warning DURATION`: Defines the interval when the alarm is in WARNING state. Use `0s` to turn off the repeating
|
||||
- `warning DURATION`: Defines the interval when the alert is in WARNING state. Use `0s` to turn off the repeating
|
||||
notification for WARNING mode.
|
||||
- `critical DURATION`: Defines the interval when the alarm is in CRITICAL state. Use `0s` to turn off the repeating
|
||||
- `critical DURATION`: Defines the interval when the alert is in CRITICAL state. Use `0s` to turn off the repeating
|
||||
notification for CRITICAL mode.
|
||||
|
||||
#### Alarm line `options`
|
||||
#### Alert line `options`
|
||||
|
||||
The only possible value for the `options` line is
|
||||
|
||||
|
|
@ -654,16 +654,16 @@ The only possible value for the `options` line is
|
|||
options: no-clear-notification
|
||||
```
|
||||
|
||||
For some alarms we need compare two time-frames, to detect anomalies. For example, `health.d/httpcheck.conf` has an
|
||||
alarm template called `web_service_slow` that compares the average http call response time over the last 3 minutes,
|
||||
compared to the average over the last hour. It triggers a warning alarm when the average of the last 3 minutes is twice
|
||||
the average of the last hour. In such cases, it is easy to trigger the alarm, but difficult to tell when the alarm is
|
||||
For some alerts we need compare two time-frames, to detect anomalies. For example, `health.d/httpcheck.conf` has an
|
||||
alert template called `web_service_slow` that compares the average http call response time over the last 3 minutes,
|
||||
compared to the average over the last hour. It triggers a warning alert when the average of the last 3 minutes is twice
|
||||
the average of the last hour. In such cases, it is easy to trigger the alert, but difficult to tell when the alert is
|
||||
cleared. As time passes, the newest window moves into the older, so the average response time of the last hour will keep
|
||||
increasing. Eventually, the comparison will find the averages in the two time-frames close enough to clear the alarm.
|
||||
However, the issue was not resolved, it's just a matter of the newer data "polluting" the old. For such alarms, it's a
|
||||
increasing. Eventually, the comparison will find the averages in the two time-frames close enough to clear the alert.
|
||||
However, the issue was not resolved, it's just a matter of the newer data "polluting" the old. For such alerts, it's a
|
||||
good idea to tell Netdata to not clear the notification, by using the `no-clear-notification` option.
|
||||
|
||||
#### Alarm line `host labels`
|
||||
#### Alert line `host labels`
|
||||
|
||||
Defines the list of labels present on a host. See our [host labels guide](https://github.com/netdata/netdata/blob/master/docs/guides/using-host-labels.md) for
|
||||
an explanation of host labels and how to implement them.
|
||||
|
|
@ -684,14 +684,14 @@ And more labels in `netdata.conf` for workstations:
|
|||
room = workstation
|
||||
```
|
||||
|
||||
By defining labels inside of `netdata.conf`, you can now apply labels to alarms. For example, you can add the following
|
||||
line to any alarms you'd like to apply to hosts that have the label `room = server`.
|
||||
By defining labels inside of `netdata.conf`, you can now apply labels to alerts. For example, you can add the following
|
||||
line to any alerts you'd like to apply to hosts that have the label `room = server`.
|
||||
|
||||
```yaml
|
||||
host labels: room = server
|
||||
```
|
||||
|
||||
The `host labels` is a space-separated list that accepts simple patterns. For example, you can create an alarm
|
||||
The `host labels` is a space-separated list that accepts simple patterns. For example, you can create an alert
|
||||
that will be applied to all hosts installed in the last decade with the following line:
|
||||
|
||||
```yaml
|
||||
|
|
@ -700,9 +700,9 @@ host labels: installed = 201*
|
|||
|
||||
See our [simple patterns docs](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) for more examples.
|
||||
|
||||
#### Alarm line `chart labels`
|
||||
#### Alert line `chart labels`
|
||||
|
||||
Similar to host labels, the `chart labels` key can be used to filter if an alarm will load or not for a specific chart, based on
|
||||
Similar to host labels, the `chart labels` key can be used to filter if an alert will load or not for a specific chart, based on
|
||||
whether these chart labels match or not.
|
||||
|
||||
The list of chart labels present on each chart can be obtained from http://localhost:19999/api/v1/charts?all
|
||||
|
|
@ -729,10 +729,10 @@ is specified that does not exist in the chart, the chart won't be matched.
|
|||
|
||||
See our [simple patterns docs](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) for more examples.
|
||||
|
||||
#### Alarm line `info`
|
||||
#### Alert line `info`
|
||||
|
||||
The info field can contain a small piece of text describing the alarm or template. This will be rendered in
|
||||
notifications and UI elements whenever the specific alarm is in focus. An example for the `ram_available` alarm is:
|
||||
The info field can contain a small piece of text describing the alert or template. This will be rendered in
|
||||
notifications and UI elements whenever the specific alert is in focus. An example for the `ram_available` alert is:
|
||||
|
||||
```yaml
|
||||
info: percentage of estimated amount of RAM available for userspace processes, without causing swapping
|
||||
|
|
@ -741,10 +741,10 @@ info: percentage of estimated amount of RAM available for userspace processes, w
|
|||
info fields can contain special variables in their text that will be replaced during run-time to provide more specific
|
||||
alert information. Current variables supported are:
|
||||
|
||||
| variable | description |
|
||||
| ---------| ----------- |
|
||||
| ${family} | Will be replaced by the family instance for the alert (e.g. eth0) |
|
||||
| ${label:LABEL_NAME} | The variable will be replaced with the value of the label |
|
||||
| variable | description |
|
||||
|---------------------|-------------------------------------------------------------------|
|
||||
| ${family} | Will be replaced by the family instance for the alert (e.g. eth0) |
|
||||
| ${label:LABEL_NAME} | The variable will be replaced with the value of the label |
|
||||
|
||||
For example, an info field like the following:
|
||||
|
||||
|
|
@ -771,7 +771,7 @@ Will become:
|
|||
info: average ratio of HTTP responses with unexpected status over the last 5 minutes for the site https://netdata.cloud/
|
||||
```
|
||||
|
||||
> Please note that variable names are case sensitive.
|
||||
> Please note that variable names are case-sensitive.
|
||||
|
||||
## Expressions
|
||||
|
||||
|
|
@ -797,10 +797,10 @@ Expressions can have variables. Variables start with `$`. Check below for more i
|
|||
There are two special values you can use:
|
||||
|
||||
- `nan`, for example `$this != nan` will check if the variable `this` is available. A variable can be `nan` if the
|
||||
database lookup failed. All calculations (i.e. addition, multiplication, etc) with a `nan` result in a `nan`.
|
||||
database lookup failed. All calculations (i.e. addition, multiplication, etc.) with a `nan` result in a `nan`.
|
||||
|
||||
- `inf`, for example `$this != inf` will check if `this` is not infinite. A value or variable can be set to infinite
|
||||
if divided by zero. All calculations (i.e. addition, multiplication, etc) with a `inf` result in a `inf`.
|
||||
if divided by zero. All calculations (i.e. addition, multiplication, etc.) with a `inf` result in a `inf`.
|
||||
|
||||
### Special use of the conditional operator
|
||||
|
||||
|
|
@ -809,7 +809,7 @@ A common (but not necessarily obvious) use of the conditional evaluation operato
|
|||
avoid bogus messages resulting from small variations in the value when it is varying regularly but staying close to the
|
||||
threshold value, without needing to delay sending messages at all.
|
||||
|
||||
An example of such usage from the default CPU usage alarms bundled with Netdata is:
|
||||
An example of such usage from the default CPU usage alerts bundled with Netdata is:
|
||||
|
||||
```yaml
|
||||
warn: $this > (($status >= $WARNING) ? (75) : (85))
|
||||
|
|
@ -818,9 +818,9 @@ crit: $this > (($status == $CRITICAL) ? (85) : (95))
|
|||
|
||||
The above say:
|
||||
|
||||
- If the alarm is currently a warning, then the threshold for being considered a warning is 75, otherwise it's 85.
|
||||
- If the alert is currently a warning, then the threshold for being considered a warning is 75, otherwise it's 85.
|
||||
|
||||
- If the alarm is currently critical, then the threshold for being considered critical is 85, otherwise it's 95.
|
||||
- If the alert is currently critical, then the threshold for being considered critical is 85, otherwise it's 95.
|
||||
|
||||
Which in turn, results in the following behavior:
|
||||
|
||||
|
|
@ -846,26 +846,25 @@ registry](https://registry.my-netdata.io/api/v1/alarm_variables?chart=system.cpu
|
|||
|
||||
Netdata supports 3 internal indexes for variables that will be used in health monitoring.
|
||||
|
||||
<details markdown="1"><summary>The variables below can be used in both chart alarms and context templates.</summary>
|
||||
<details markdown="1"><summary>The variables below can be used in both chart alerts and context templates.</summary>
|
||||
|
||||
Although the `alarm_variables` link shows you variables for a particular chart, the same variables can also be used in
|
||||
templates for charts belonging to a given [context](https://github.com/netdata/netdata/blob/master/web/README.md#contexts). The reason is that all charts of a given
|
||||
context are essentially identical, with the only difference being the [family](https://github.com/netdata/netdata/blob/master/web/README.md#families) that
|
||||
identifies a particular hardware or software instance. Charts and templates do not apply to specific families anyway,
|
||||
unless if you explicitly limit an alarm with the [alarm line `families`](#alarm-line-families).
|
||||
unless if you explicitly limit an alert with the [alert line `families`](#alert-line-families).
|
||||
|
||||
</details>
|
||||
|
||||
- **chart local variables**. All the dimensions of the chart are exposed as local variables. The value of `$this` for
|
||||
the other configured alarms of the chart also appears, under the name of each configured alarm.
|
||||
the other configured alerts of the chart also appears, under the name of each configured alert.
|
||||
|
||||
Charts also define a few special variables:
|
||||
|
||||
- `$last_collected_t` is the unix timestamp of the last data collection
|
||||
- `$collected_total_raw` is the sum of all the dimensions (their last collected values)
|
||||
- `$update_every` is the update frequency of the chart
|
||||
- `$green` and `$red` the threshold defined in alarms (these are per chart - the charts
|
||||
inherits them from the the first alarm that defined them)
|
||||
- `$green` and `$red` the threshold defined in alerts (these are per chart - the charts inherits them from the first alert that defined them)
|
||||
|
||||
Chart dimensions define their last calculated (i.e. interpolated) value, exactly as
|
||||
shown on the charts, but also a variable with their name and suffix `_raw` that resolves
|
||||
|
|
@ -877,35 +876,35 @@ unless if you explicitly limit an alarm with the [alarm line `families`](#alarm-
|
|||
charts, have `family = eth0`. This index includes all local variables, but if there are
|
||||
overlapping variables, only the first are exposed.
|
||||
|
||||
- **host variables**. All the dimensions of all charts, including all alarms, in fullname.
|
||||
- **host variables**. All the dimensions of all charts, including all alerts, in fullname.
|
||||
Fullname is `CHART.VARIABLE`, where `CHART` is either the chart id or the chart name (both
|
||||
are supported).
|
||||
|
||||
- **special variables\*** are:
|
||||
|
||||
- `$this`, which is resolved to the value of the current alarm.
|
||||
- `$this`, which is resolved to the value of the current alert.
|
||||
|
||||
- `$status`, which is resolved to the current status of the alarm (the current = the last
|
||||
- `$status`, which is resolved to the current status of the alert (the current = the last
|
||||
status, i.e. before the current database lookup and the evaluation of the `calc` line).
|
||||
This values can be compared with `$REMOVED`, `$UNINITIALIZED`, `$UNDEFINED`, `$CLEAR`,
|
||||
`$WARNING`, `$CRITICAL`. These values are incremental, ie. `$status > $CLEAR` works as
|
||||
`$WARNING`, `$CRITICAL`. These values are incremental, e.g. `$status > $CLEAR` works as
|
||||
expected.
|
||||
|
||||
- `$now`, which is resolved to current unix timestamp.
|
||||
|
||||
## Alarm statuses
|
||||
## Alert statuses
|
||||
|
||||
Alarms can have the following statuses:
|
||||
Alerts can have the following statuses:
|
||||
|
||||
- `REMOVED` - the alarm has been deleted (this happens when a SIGUSR2 is sent to Netdata
|
||||
- `REMOVED` - the alert has been deleted (this happens when a SIGUSR2 is sent to Netdata
|
||||
to reload health configuration)
|
||||
|
||||
- `UNINITIALIZED` - the alarm is not initialized yet
|
||||
- `UNINITIALIZED` - the alert is not initialized yet
|
||||
|
||||
- `UNDEFINED` - the alarm failed to be calculated (i.e. the database lookup failed,
|
||||
a division by zero occurred, etc)
|
||||
- `UNDEFINED` - the alert failed to be calculated (i.e. the database lookup failed,
|
||||
a division by zero occurred, etc.)
|
||||
|
||||
- `CLEAR` - the alarm is not armed / raised (i.e. is OK)
|
||||
- `CLEAR` - the alert is not armed / raised (i.e. is OK)
|
||||
|
||||
- `WARNING` - the warning expression resulted in true or non-zero
|
||||
|
||||
|
|
@ -913,9 +912,9 @@ Alarms can have the following statuses:
|
|||
|
||||
The external script will be called for all status changes.
|
||||
|
||||
## Example alarms
|
||||
## Example alerts
|
||||
|
||||
Check the `health/health.d/` directory for all alarms shipped with Netdata.
|
||||
Check the `health/health.d/` directory for all alerts shipped with Netdata.
|
||||
|
||||
Here are a few examples:
|
||||
|
||||
|
|
@ -962,16 +961,16 @@ The above applies the **template** to all charts that have `context = apache.req
|
|||
every: 10s
|
||||
```
|
||||
|
||||
The alarm will be evaluated every 10 seconds.
|
||||
The alert will be evaluated every 10 seconds.
|
||||
|
||||
```yaml
|
||||
warn: $this > ( 5 * $update_every)
|
||||
crit: $this > (10 * $update_every)
|
||||
```
|
||||
|
||||
If these result in non-zero or true, they trigger the alarm.
|
||||
If these result in non-zero or true, they trigger the alert.
|
||||
|
||||
- `$this` refers to the value of this alarm (i.e. the result of the `calc` line.
|
||||
- `$this` refers to the value of this alert (e.g. the result of the `calc` line).
|
||||
We could also use `$apache_last_collected_secs`.
|
||||
|
||||
`$update_every` is the update frequency of the chart, in seconds.
|
||||
|
|
@ -997,8 +996,8 @@ template: disk_full_percent
|
|||
|
||||
So, the `calc` line finds the percentage of used space. `$this` resolves to this percentage.
|
||||
|
||||
This is a repeating alarm and if the alarm becomes CRITICAL it repeats the notifications every 10 seconds. It also
|
||||
repeats notifications every 2 minutes if the alarm goes into WARNING mode.
|
||||
This is a repeating alert and if the alert becomes CRITICAL it repeats the notifications every 10 seconds. It also
|
||||
repeats notifications every 2 minutes if the alert goes into WARNING mode.
|
||||
|
||||
### Example 3 - disk fill rate
|
||||
|
||||
|
|
@ -1018,7 +1017,7 @@ Calculate the disk fill rate:
|
|||
|
||||
In the `calc` line: `$this` is the result of the `lookup` line (i.e. the free space 30 minutes
|
||||
ago) and `$avail` is the current disk free space. So the `calc` line will either have a positive
|
||||
number of GB/second if the disk if filling up, or a negative number of GB/second if the disk is
|
||||
number of GB/second if the disk is filling up, or a negative number of GB/second if the disk is
|
||||
freeing up space.
|
||||
|
||||
There is no `warn` or `crit` lines here. So, this template will just do the calculation and
|
||||
|
|
@ -1039,7 +1038,7 @@ The `calc` line estimates the time in hours, we will run out of disk space. Of c
|
|||
positive values are interesting for this check, so the warning and critical conditions check
|
||||
for positive values and that we have enough free space for 48 and 24 hours respectively.
|
||||
|
||||
Once this alarm triggers we will receive an email like this:
|
||||
Once this alert triggers we will receive an email like this:
|
||||
|
||||

|
||||
|
||||
|
|
@ -1057,11 +1056,11 @@ template: 30min_packet_drops
|
|||
|
||||
The `lookup` line will calculate the sum of the all dropped packets in the last 30 minutes.
|
||||
|
||||
The `crit` line will issue a critical alarm if even a single packet has been dropped.
|
||||
The `crit` line will issue a critical alert if even a single packet has been dropped.
|
||||
|
||||
Note that the drops chart does not exist if a network interface has never dropped a single packet.
|
||||
When Netdata detects a dropped packet, it will add the chart and it will automatically attach this
|
||||
alarm to it.
|
||||
When Netdata detects a dropped packet, it will add the chart, and it will automatically attach this
|
||||
alert to it.
|
||||
|
||||
### Example 5 - CPU usage
|
||||
|
||||
|
|
@ -1079,7 +1078,7 @@ template: cpu_template
|
|||
```
|
||||
|
||||
The `lookup` line will calculate the average CPU usage from system and user over the last minute. Because we have
|
||||
the foreach in the `lookup` line, Netdata will create two independent alarms called `cpu_template_system`
|
||||
the foreach in the `lookup` line, Netdata will create two independent alerts called `cpu_template_system`
|
||||
and `dim_template_user` that will have all the other parameters shared among them.
|
||||
|
||||
### Example 6 - CPU usage
|
||||
|
|
@ -1098,11 +1097,11 @@ template: cpu_template
|
|||
```
|
||||
|
||||
The `lookup` line will calculate the average of CPU usage from system and user over the last minute. In this case
|
||||
Netdata will create alarms for all dimensions of the chart.
|
||||
Netdata will create alerts for all dimensions of the chart.
|
||||
|
||||
### Example 7 - Z-Score based alarm
|
||||
### Example 7 - Z-Score based alert
|
||||
|
||||
Derive a "[Z Score](https://en.wikipedia.org/wiki/Standard_score)" based alarm on `user` dimension of the `system.cpu` chart:
|
||||
Derive a "[Z Score](https://en.wikipedia.org/wiki/Standard_score)" based alert on `user` dimension of the `system.cpu` chart:
|
||||
|
||||
```yaml
|
||||
alarm: cpu_user_mean
|
||||
|
|
@ -1124,9 +1123,9 @@ lookup: mean -10s of user
|
|||
crit: $this < -3 or $this > 3
|
||||
```
|
||||
|
||||
Since [`z = (x - mean) / stddev`](https://en.wikipedia.org/wiki/Standard_score) we create two input alarms, one for `mean` and one for `stddev` and then use them both as inputs in our final `cpu_user_zscore` alarm.
|
||||
Since [`z = (x - mean) / stddev`](https://en.wikipedia.org/wiki/Standard_score) we create two input alerts, one for `mean` and one for `stddev` and then use them both as inputs in our final `cpu_user_zscore` alert.
|
||||
|
||||
### Example 8 - [Anomaly rate](https://github.com/netdata/netdata/blob/master/ml/README.md#anomaly-rate) based CPU dimensions alarm
|
||||
### Example 8 - [Anomaly rate](https://github.com/netdata/netdata/blob/master/ml/README.md#anomaly-rate) based CPU dimensions alert
|
||||
|
||||
Warning if 5 minute rolling [anomaly rate](https://github.com/netdata/netdata/blob/master/ml/README.md#anomaly-rate) for any CPU dimension is above 5%, critical if it goes above 20%:
|
||||
|
||||
|
|
@ -1145,9 +1144,9 @@ template: ml_5min_cpu_dims
|
|||
```
|
||||
|
||||
The `lookup` line will calculate the average anomaly rate of each `system.cpu` dimension over the last 5 minues. In this case
|
||||
Netdata will create alarms for all dimensions of the chart.
|
||||
Netdata will create alerts for all dimensions of the chart.
|
||||
|
||||
### Example 9 - [Anomaly rate](https://github.com/netdata/netdata/blob/master/ml/README.md#anomaly-rate) based CPU chart alarm
|
||||
### Example 9 - [Anomaly rate](https://github.com/netdata/netdata/blob/master/ml/README.md#anomaly-rate) based CPU chart alert
|
||||
|
||||
Warning if 5 minute rolling [anomaly rate](https://github.com/netdata/netdata/blob/master/ml/README.md#anomaly-rate) averaged across all CPU dimensions is above 5%, critical if it goes above 20%:
|
||||
|
||||
|
|
@ -1166,9 +1165,9 @@ template: ml_5min_cpu_chart
|
|||
```
|
||||
|
||||
The `lookup` line will calculate the average anomaly rate across all `system.cpu` dimensions over the last 5 minues. In this case
|
||||
Netdata will create one alarm for the chart.
|
||||
Netdata will create one alert for the chart.
|
||||
|
||||
### Example 10 - [Anomaly rate](https://github.com/netdata/netdata/blob/master/ml/README.md#anomaly-rate) based node level alarm
|
||||
### Example 10 - [Anomaly rate](https://github.com/netdata/netdata/blob/master/ml/README.md#anomaly-rate) based node level alert
|
||||
|
||||
Warning if 5 minute rolling [anomaly rate](https://github.com/netdata/netdata/blob/master/ml/README.md#anomaly-rate) averaged across all ML enabled dimensions is above 5%, critical if it goes above 20%:
|
||||
|
||||
|
|
@ -1188,10 +1187,10 @@ template: ml_5min_node
|
|||
|
||||
The `lookup` line will use the `anomaly_rate` dimension of the `anomaly_detection.anomaly_rate` ML chart to calculate the average [node level anomaly rate](https://github.com/netdata/netdata/blob/master/ml/README.md#node-anomaly-rate) over the last 5 minues.
|
||||
|
||||
## Use dimension templates to create dynamic alarms
|
||||
## Use dimension templates to create dynamic alerts
|
||||
|
||||
In v1.18 of Netdata, we introduced **dimension templates** for alarms, which simplifies the process of
|
||||
writing [alarm entities](#health-entity-reference) for
|
||||
In v1.18 of Netdata, we introduced **dimension templates** for alerts, which simplifies the process of
|
||||
writing [alert entities](#health-entity-reference) for
|
||||
charts with many dimensions.
|
||||
|
||||
Dimension templates can condense many individual entities into one—no more copy-pasting one entity and changing the
|
||||
|
|
@ -1199,21 +1198,21 @@ Dimension templates can condense many individual entities into one—no more cop
|
|||
|
||||
### The fundamentals of `foreach`
|
||||
|
||||
> **Note**: works only with [templates](#alarm-line-alarm-or-template).
|
||||
> **Note**: works only with [templates](#alert-line-alarm-or-template).
|
||||
|
||||
Our dimension templates update creates a new `foreach` parameter to the
|
||||
existing [`lookup` line](#alarm-line-lookup). This
|
||||
existing [`lookup` line](#alert-line-lookup). This
|
||||
is where the magic happens.
|
||||
|
||||
You use the `foreach` parameter to specify which dimensions you want to monitor with this single alarm. You can separate
|
||||
You use the `foreach` parameter to specify which dimensions you want to monitor with this single alert. You can separate
|
||||
them with a comma (`,`) or a pipe (`|`). You can also use
|
||||
a [Netdata simple pattern](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) to create
|
||||
many alarms with a regex-like syntax.
|
||||
many alerts with a regex-like syntax.
|
||||
|
||||
The `foreach` parameter _has_ to be the last parameter in your `lookup` line, and if you have both `of` and `foreach` in
|
||||
the same `lookup` line, Netdata will ignore the `of` parameter and use `foreach` instead.
|
||||
|
||||
Let's get into some examples so you can see how the new parameter works.
|
||||
Let's get into some examples, so you can see how the new parameter works.
|
||||
|
||||
> ⚠️ The following entities are examples to showcase the functionality and syntax of dimension templates. They are not
|
||||
> meant to be run as-is on production systems.
|
||||
|
|
@ -1246,7 +1245,7 @@ lookup: average -10m of nice
|
|||
crit: $this > 80
|
||||
```
|
||||
|
||||
With dimension templates, you can condense these into a single template. Take note of the `alarm` and `lookup` lines.
|
||||
With dimension templates, you can condense these into a single template. Take note of the `lookup` line.
|
||||
|
||||
```yaml
|
||||
template: cpu_template
|
||||
|
|
@ -1262,27 +1261,27 @@ and `_` being the only allowed symbols.
|
|||
|
||||
The `lookup` line has changed from `of` to `foreach`, and we're now passing three dimensions.
|
||||
|
||||
In this example, Netdata will create three alarms with the names `cpu_template_system`, `cpu_template_user`, and
|
||||
`cpu_template_nice`. Every minute, each alarm will use the same database query to calculate the average CPU usage for
|
||||
the `system`, `user`, and `nice` dimensions over the last 10 minutes and send out alarms if necessary.
|
||||
In this example, Netdata will create three alerts with the names `cpu_template_system`, `cpu_template_user`, and
|
||||
`cpu_template_nice`. Every minute, each alert will use the same database query to calculate the average CPU usage for
|
||||
the `system`, `user`, and `nice` dimensions over the last 10 minutes and send out alerts if necessary.
|
||||
|
||||
You can find these three alarms active by clicking on the **Alarms** button in the top navigation, and then clicking on
|
||||
You can find these three alerts active by clicking on the **Alerts** button in the top navigation, and then clicking on
|
||||
the **All** tab and scrolling to the **system - cpu** collapsible section.
|
||||
|
||||
|
||||

|
||||
|
||||
Let's look at some other examples of how `foreach` works so you can best apply it in your configurations.
|
||||
Let's look at some other examples of how `foreach` works, so you can best apply it in your configurations.
|
||||
|
||||
### Using a Netdata simple pattern in `foreach`
|
||||
|
||||
In the last example, we used `foreach system,user,nice` to create three distinct alarms using dimension templates. But
|
||||
what if you want to quickly create alarms for _all_ the dimensions of a given chart?
|
||||
In the last example, we used `foreach system,user,nice` to create three distinct alerts using dimension templates. But
|
||||
what if you want to quickly create alerts for _all_ the dimensions of a given chart?
|
||||
|
||||
Use a [simple pattern](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md)! One example of a simple pattern is a single wildcard
|
||||
(`*`).
|
||||
|
||||
Instead of monitoring system CPU usage, let's monitor per-application CPU usage using the `apps.cpu` chart. Passing a
|
||||
wildcard as the simple pattern tells Netdata to create a separate alarm for _every_ process on your system:
|
||||
wildcard as the simple pattern tells Netdata to create a separate alert for _every_ process on your system:
|
||||
|
||||
```yaml
|
||||
alarm: app_cpu
|
||||
|
|
@ -1293,21 +1292,21 @@ lookup: average -10m percentage foreach *
|
|||
crit: $this > 80
|
||||
```
|
||||
|
||||
This entity will now create alarms for every dimension in the `apps.cpu` chart. Given that most `apps.cpu` charts have
|
||||
This entity will now create alerts for every dimension in the `apps.cpu` chart. Given that most `apps.cpu` charts have
|
||||
10 or more dimensions, using the wildcard ensures you catch every CPU-hogging process.
|
||||
|
||||
To learn more about how to use simple patterns with dimension templates, see
|
||||
our [simple patterns documentation](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md).
|
||||
|
||||
### Using `foreach` with alarm templates
|
||||
### Using `foreach` with alert templates
|
||||
|
||||
Dimension templates also work
|
||||
with [alarm templates](#alarm-line-alarm-or-template).
|
||||
Alarm templates help you create alarms for all the charts with a given context—for example, all the cores of your
|
||||
with [alert templates](#alert-line-alarm-or-template).
|
||||
Alert templates help you create alerts for all the charts with a given context—for example, all the cores of your
|
||||
system's CPU.
|
||||
|
||||
By combining the two, you can create dozens of individual alarms with a single template entity. Here's how you would
|
||||
create alarms for the `system`, `user`, and `nice` dimensions for every chart in the `cpu.cpu` context—or, in other
|
||||
By combining the two, you can create dozens of individual alerts with a single template entity. Here's how you would
|
||||
create alerts for the `system`, `user`, and `nice` dimensions for every chart in the `cpu.cpu` context—or, in other
|
||||
words, every CPU core.
|
||||
|
||||
```yaml
|
||||
|
|
@ -1319,7 +1318,7 @@ template: cpu_template
|
|||
crit: $this > 80
|
||||
```
|
||||
|
||||
On a system with a 6-core, 12-thread Ryzen 5 1600 CPU, this one entity creates alarms on the following charts and
|
||||
On a system with a 6-core, 12-thread Ryzen 5 1600 CPU, this one entity creates alerts on the following charts and
|
||||
dimensions:
|
||||
|
||||
- `cpu.cpu0`
|
||||
|
|
@ -1344,11 +1343,11 @@ dimensions:
|
|||
- `cpu_template_system`
|
||||
- `cpu_template_nice`
|
||||
|
||||
And how just a few of those dimension template-generated alarms look like in the Netdata dashboard.
|
||||
And how just a few of those dimension template-generated alerts look like in the Netdata dashboard.
|
||||
|
||||
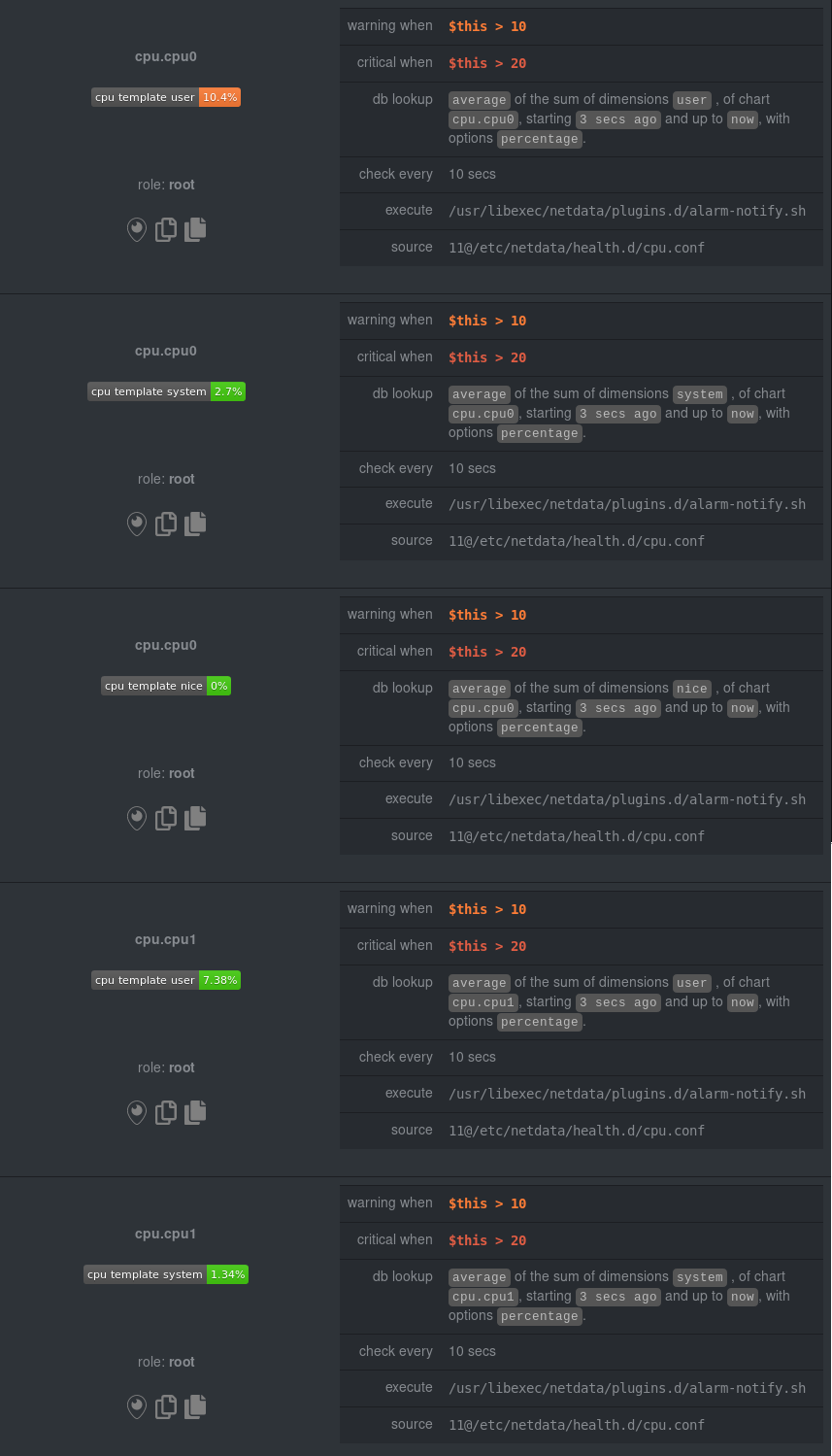
|
||||

|
||||
|
||||
All in all, this single entity creates 36 individual alarms. Much easier than writing 36 separate entities in your
|
||||
All in all, this single entity creates 36 individual alerts. Much easier than writing 36 separate entities in your
|
||||
health configuration files!
|
||||
|
||||
## Troubleshooting
|
||||
|
|
@ -1366,7 +1365,7 @@ output in debug.log.
|
|||
You can find the context of charts by looking up the chart in either `http://NODE:19999/netdata.conf` or
|
||||
`http://NODE:19999/api/v1/charts`, replacing `NODE` with the IP address or hostname for your Agent dashboard.
|
||||
|
||||
You can find how Netdata interpreted the expressions by examining the alarm at
|
||||
You can find how Netdata interpreted the expressions by examining the alert at
|
||||
`http://NODE:19999/api/v1/alarms?all`. For each expression, Netdata will return the expression as given in its
|
||||
config file, and the same expression with additional parentheses added to indicate the evaluation flow of the
|
||||
expression.
|
||||
|
|
|
|||
|
|
@ -58,7 +58,7 @@ You can send the notification to multiple recipients by separating the emails wi
|
|||
# RECIPIENTS PER ROLE
|
||||
|
||||
# -----------------------------------------------------------------------------
|
||||
# generic system alarms
|
||||
# generic system alerts
|
||||
# CPU, disks, network interfaces, entropy, etc
|
||||
|
||||
role_recipients_email[sysadmin]="someone@exaple.com someoneelse@example.com"
|
||||
|
|
@ -106,10 +106,10 @@ sudo su -s /bin/bash netdata
|
|||
# enable debugging info on the console
|
||||
export NETDATA_ALARM_NOTIFY_DEBUG=1
|
||||
|
||||
# send test alarms to sysadmin
|
||||
# send test alerts to sysadmin
|
||||
/usr/libexec/netdata/plugins.d/alarm-notify.sh test
|
||||
|
||||
# send test alarms to any role
|
||||
# send test alerts to any role
|
||||
/usr/libexec/netdata/plugins.d/alarm-notify.sh test "ROLE"
|
||||
```
|
||||
|
||||
|
|
@ -129,17 +129,17 @@ If you are [running your own registry](https://github.com/netdata/netdata/blob/m
|
|||
|
||||
When you define recipients per role for notification methods, you can append `|critical` to limit the notifications that are sent.
|
||||
|
||||
In the following examples, the first recipient receives all the alarms, while the second one receives only notifications for alarms that have at some point become critical.
|
||||
The second user may still receive warning and clear notifications, but only for the event that previously caused a critical alarm.
|
||||
In the following examples, the first recipient receives all the alerts, while the second one receives only notifications for alerts that have at some point become critical.
|
||||
The second user may still receive warning and clear notifications, but only for the event that previously caused a critical alert.
|
||||
|
||||
```conf
|
||||
email : "user1@example.com user2@example.com|critical"
|
||||
pushover : "2987343...9437837 8756278...2362736|critical"
|
||||
telegram : "111827421 112746832|critical"
|
||||
slack : "alarms disasters|critical"
|
||||
alerta : "alarms disasters|critical"
|
||||
flock : "alarms disasters|critical"
|
||||
discord : "alarms disasters|critical"
|
||||
slack : "alerts disasters|critical"
|
||||
alerta : "alerts disasters|critical"
|
||||
flock : "alerts disasters|critical"
|
||||
discord : "alerts disasters|critical"
|
||||
twilio : "+15555555555 +17777777777|critical"
|
||||
messagebird: "+15555555555 +17777777777|critical"
|
||||
kavenegar : "09155555555 09177777777|critical"
|
||||
|
|
@ -148,7 +148,7 @@ The second user may still receive warning and clear notifications, but only for
|
|||
```
|
||||
|
||||
If a per role recipient is set to an empty string, the default recipient of the given
|
||||
notification method (email, pushover, telegram, slack, alerta, etc) will be used.
|
||||
notification method (email, pushover, telegram, slack, alerta, etc.) will be used.
|
||||
|
||||
To disable a notification, use the recipient called: disabled
|
||||
This works for all notification methods (including the default recipients).
|
||||
|
|
|
|||
|
|
@ -63,14 +63,14 @@ Edit `health_alarm_notify.conf`, changes to this file do not require restarting
|
|||
| `${alarm}` | Like "name = value units" |
|
||||
| `${status_message}` | Like "needs attention", "recovered", "is critical" |
|
||||
| `${severity}` | Like "Escalated to CRITICAL", "Recovered from WARNING" |
|
||||
| `${raised_for}` | Like "(alarm was raised for 10 minutes)" |
|
||||
| `${raised_for}` | Like "(alert was raised for 10 minutes)" |
|
||||
| `${host}` | The host generated this event |
|
||||
| `${url_host}` | Same as ${host} but URL encoded |
|
||||
| `${unique_id}` | The unique id of this event |
|
||||
| `${alarm_id}` | The unique id of the alarm that generated this event |
|
||||
| `${event_id}` | The incremental id of the event, for this alarm id |
|
||||
| `${alarm_id}` | The unique id of the alert that generated this event |
|
||||
| `${event_id}` | The incremental id of the event, for this alert id |
|
||||
| `${when}` | The timestamp this event occurred |
|
||||
| `${name}` | The name of the alarm, as given in netdata health.d entries |
|
||||
| `${name}` | The name of the alert, as given in netdata health.d entries |
|
||||
| `${url_name}` | Same as ${name} but URL encoded |
|
||||
| `${chart}` | The name of the chart (type.id) |
|
||||
| `${url_chart}` | Same as ${chart} but URL encoded |
|
||||
|
|
@ -78,27 +78,27 @@ Edit `health_alarm_notify.conf`, changes to this file do not require restarting
|
|||
| `${url_family}` | Same as ${family} but URL encoded |
|
||||
| `${status}` | The current status : REMOVED, UNINITIALIZED, UNDEFINED, CLEAR, WARNING, CRITICAL |
|
||||
| `${old_status}` | The previous status: REMOVED, UNINITIALIZED, UNDEFINED, CLEAR, WARNING, CRITICAL |
|
||||
| `${value}` | The current value of the alarm |
|
||||
| `${old_value}` | The previous value of the alarm |
|
||||
| `${src}` | The line number and file the alarm has been configured |
|
||||
| `${duration}` | The duration in seconds of the previous alarm state |
|
||||
| `${value}` | The current value of the alert |
|
||||
| `${old_value}` | The previous value of the alert |
|
||||
| `${src}` | The line number and file the alert has been configured |
|
||||
| `${duration}` | The duration in seconds of the previous alert state |
|
||||
| `${duration_txt}` | Same as ${duration} for humans |
|
||||
| `${non_clear_duration}` | The total duration in seconds this is/was non-clear |
|
||||
| `${non_clear_duration_txt}` | Same as ${non_clear_duration} for humans |
|
||||
| `${units}` | The units of the value |
|
||||
| `${info}` | A short description of the alarm |
|
||||
| `${info}` | A short description of the alert |
|
||||
| `${value_string}` | Friendly value (with units) |
|
||||
| `${old_value_string}` | Friendly old value (with units) |
|
||||
| `${image}` | The URL of an image to represent the status of the alarm |
|
||||
| `${color}` | A color in AABBCC format for the alarm |
|
||||
| `${image}` | The URL of an image to represent the status of the alert |
|
||||
| `${color}` | A color in AABBCC format for the alert |
|
||||
| `${goto_url}` | The URL the user can click to see the netdata dashboard |
|
||||
| `${calc_expression}` | The expression evaluated to provide the value for the alarm |
|
||||
| `${calc_expression}` | The expression evaluated to provide the value for the alert |
|
||||
| `${calc_param_values}` | The value of the variables in the evaluated expression |
|
||||
| `${total_warnings}` | The total number of alarms in WARNING state on the host |
|
||||
| `${total_critical}` | The total number of alarms in CRITICAL state on the host |
|
||||
| `${total_warnings}` | The total number of alerts in WARNING state on the host |
|
||||
| `${total_critical}` | The total number of alerts in CRITICAL state on the host |
|
||||
|
||||
3. Set `DEFAULT_RECIPIENT_AWSSNS` to the Topic ARN you noted down upon creating the Topic.
|
||||
All roles will default to this variable if left unconfigured.
|
||||
All roles will default to this variable if it is not configured.
|
||||
|
||||
You can then have different recipient Topics per **role**, by editing `DEFAULT_RECIPIENT_AWSSNS` with the Topic ARN you want, in the following entries at the bottom of the same file:
|
||||
|
||||
|
|
|
|||
|
|
@ -39,7 +39,7 @@ Edit `health_alarm_notify.conf`, changes to this file do not require restarting
|
|||
# limit it to 160 characters and encode it for use in a URL
|
||||
urlencode "${msg:0:160}" >/dev/null; msg="${REPLY}"
|
||||
|
||||
# a space separated list of the recipients to send alarms to
|
||||
# a space separated list of the recipients to send alerts to
|
||||
to="${1}"
|
||||
|
||||
for phone in ${to}; do
|
||||
|
|
@ -67,14 +67,14 @@ Edit `health_alarm_notify.conf`, changes to this file do not require restarting
|
|||
| `${alarm}` | Like "name = value units" |
|
||||
| `${status_message}` | Like "needs attention", "recovered", "is critical" |
|
||||
| `${severity}` | Like "Escalated to CRITICAL", "Recovered from WARNING" |
|
||||
| `${raised_for}` | Like "(alarm was raised for 10 minutes)" |
|
||||
| `${raised_for}` | Like "(alert was raised for 10 minutes)" |
|
||||
| `${host}` | The host generated this event |
|
||||
| `${url_host}` | Same as ${host} but URL encoded |
|
||||
| `${unique_id}` | The unique id of this event |
|
||||
| `${alarm_id}` | The unique id of the alarm that generated this event |
|
||||
| `${event_id}` | The incremental id of the event, for this alarm id |
|
||||
| `${alarm_id}` | The unique id of the alert that generated this event |
|
||||
| `${event_id}` | The incremental id of the event, for this alert id |
|
||||
| `${when}` | The timestamp this event occurred |
|
||||
| `${name}` | The name of the alarm, as given in netdata health.d entries |
|
||||
| `${name}` | The name of the alert, as given in netdata health.d entries |
|
||||
| `${url_name}` | Same as ${name} but URL encoded |
|
||||
| `${chart}` | The name of the chart (type.id) |
|
||||
| `${url_chart}` | Same as ${chart} but URL encoded |
|
||||
|
|
@ -82,24 +82,24 @@ Edit `health_alarm_notify.conf`, changes to this file do not require restarting
|
|||
| `${url_family}` | Same as ${family} but URL encoded |
|
||||
| `${status}` | The current status : REMOVED, UNINITIALIZED, UNDEFINED, CLEAR, WARNING, CRITICAL |
|
||||
| `${old_status}` | The previous status: REMOVED, UNINITIALIZED, UNDEFINED, CLEAR, WARNING, CRITICAL |
|
||||
| `${value}` | The current value of the alarm |
|
||||
| `${old_value}` | The previous value of the alarm |
|
||||
| `${src}` | The line number and file the alarm has been configured |
|
||||
| `${duration}` | The duration in seconds of the previous alarm state |
|
||||
| `${value}` | The current value of the alert |
|
||||
| `${old_value}` | The previous value of the alert |
|
||||
| `${src}` | The line number and file the alert has been configured |
|
||||
| `${duration}` | The duration in seconds of the previous alert state |
|
||||
| `${duration_txt}` | Same as ${duration} for humans |
|
||||
| `${non_clear_duration}` | The total duration in seconds this is/was non-clear |
|
||||
| `${non_clear_duration_txt}` | Same as ${non_clear_duration} for humans |
|
||||
| `${units}` | The units of the value |
|
||||
| `${info}` | A short description of the alarm |
|
||||
| `${info}` | A short description of the alert |
|
||||
| `${value_string}` | Friendly value (with units) |
|
||||
| `${old_value_string}` | Friendly old value (with units) |
|
||||
| `${image}` | The URL of an image to represent the status of the alarm |
|
||||
| `${color}` | A color in AABBCC format for the alarm |
|
||||
| `${image}` | The URL of an image to represent the status of the alert |
|
||||
| `${color}` | A color in AABBCC format for the alert |
|
||||
| `${goto_url}` | The URL the user can click to see the netdata dashboard |
|
||||
| `${calc_expression}` | The expression evaluated to provide the value for the alarm |
|
||||
| `${calc_expression}` | The expression evaluated to provide the value for the alert |
|
||||
| `${calc_param_values}` | The value of the variables in the evaluated expression |
|
||||
| `${total_warnings}` | The total number of alarms in WARNING state on the host |
|
||||
| `${total_critical}` | The total number of alarms in CRITICAL state on the host |
|
||||
| `${total_warnings}` | The total number of alerts in WARNING state on the host |
|
||||
| `${total_critical}` | The total number of alerts in CRITICAL state on the host |
|
||||
|
||||
You can then have different `${to}` variables per **role**, by editing `DEFAULT_RECIPIENT_CUSTOM` with the variable you want, in the following entries at the bottom of the same file:
|
||||
|
||||
|
|
@ -129,7 +129,7 @@ custom_sender() {
|
|||
# limit it to 160 characters and encode it for use in a URL
|
||||
urlencode "${msg:0:160}" >/dev/null; msg="${REPLY}"
|
||||
|
||||
# a space separated list of the recipients to send alarms to
|
||||
# a space separated list of the recipients to send alerts to
|
||||
to="${1}"
|
||||
|
||||
for phone in ${to}; do
|
||||
|
|
|
|||
|
|
@ -21,7 +21,7 @@ You will need:
|
|||
- An API Space. This is the URL part of the page you have access in order to generate the API Token.
|
||||
For example, the URL for a generated API token might look like: `https://monitor.illumineit.com/e/2a93fe0e-4cd5-469a-9d0d-1a064235cfce/#settings/integration/apikeys;gf=all` In that case, the Space is `2a93fe0e-4cd5-469a-9d0d-1a064235cfce`.
|
||||
- A Server Tag. To generate one on your Dynatrace Server, go to **Settings** --> **Tags** --> **Manually applied tags** and create the Tag.
|
||||
The Netdata alarm is sent as a Dynatrace Event to be correlated with all those hosts tagged with this Tag you have created.
|
||||
The Netdata alert is sent as a Dynatrace Event to be correlated with all those hosts tagged with this Tag you have created.
|
||||
- terminal access to the Agent you wish to configure
|
||||
|
||||
## Configure Netdata to send alert notifications to Dynatrace
|
||||
|
|
@ -42,7 +42,7 @@ Edit `health_alarm_notify.conf`:
|
|||
3. Set `DYNATRACE_TOKEN` to your Dynatrace API authentication token
|
||||
4. Set `DYNATRACE_SPACE` to the API Space, it is the URL part of the page you have access in order to generate the API Token. For example, the URL for a generated API token might look like: `https://monitor.illumineit.com/e/2a93fe0e-4cd5-469a-9d0d-1a064235cfce/#settings/integration/apikeys;gf=all` In that case, the Space is `2a93fe0e-4cd5-469a-9d0d-1a064235cfce`.
|
||||
5. Set `DYNATRACE_TAG_VALUE` to your Dynatrace Server Tag.
|
||||
6. `DYNATRACE_ANNOTATION_TYPE` can be left to its default value `Netdata Alarm`, but you can change it to better fit your needs.
|
||||
6. `DYNATRACE_ANNOTATION_TYPE` can be left to its default value `Netdata Alert`, but you can change it to better fit your needs.
|
||||
7. Set `DYNATRACE_EVENT` to the Dynatrace `eventType` you want, possible values are:
|
||||
`AVAILABILITY_EVENT`, `CUSTOM_ALERT`, `CUSTOM_ANNOTATION`, `CUSTOM_CONFIGURATION`, `CUSTOM_DEPLOYMENT`, `CUSTOM_INFO`, `ERROR_EVENT`, `MARKED_FOR_TERMINATION`, `PERFORMANCE_EVENT`, `RESOURCE_CONTENTION_EVENT`. You can read more [here](https://www.dynatrace.com/support/help/dynatrace-api/environment-api/events-v2/post-event#request-body-objects)
|
||||
|
||||
|
|
|
|||
|
|
@ -47,7 +47,7 @@ Edit `health_alarm_notify.conf`, changes to this file do not require restarting
|
|||
|
||||
2. Set `SEND_EMAIL` to `YES`.
|
||||
3. Set `DEFAULT_RECIPIENT_EMAIL` to the email address you want the email to be sent by default.
|
||||
You can define multiple email addresses like this: `alarms@example.com systems@example.com`.
|
||||
You can define multiple email addresses like this: `alerts@example.com systems@example.com`.
|
||||
All roles will default to this variable if left unconfigured.
|
||||
4. There are also other optional configuration entries that can be found in the same section of the file.
|
||||
|
||||
|
|
|
|||
|
|
@ -58,7 +58,7 @@ An example of a working configuration would be:
|
|||
|
||||
SEND_FLOCK="YES"
|
||||
FLOCK_WEBHOOK_URL="https://api.flock.com/hooks/sendMessage/XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
|
||||
DEFAULT_RECIPIENT_FLOCK="alarms"
|
||||
DEFAULT_RECIPIENT_FLOCK="alerts"
|
||||
```
|
||||
|
||||
## Test the notification method
|
||||
|
|
|
|||
|
|
@ -10,7 +10,7 @@ Learn how to send alerts to your Gotify instance using Netdata's Agent alert not
|
|||
|
||||
This is what you will get:
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/103264516/162509205-1e88e5d9-96b6-4f7f-9426-182776158128.png" alt="Example alarm notifications in Gotify" width="70%"></img>
|
||||
<img src="https://user-images.githubusercontent.com/103264516/162509205-1e88e5d9-96b6-4f7f-9426-182776158128.png" alt="Example alert notifications in Gotify" width="70%"></img>
|
||||
|
||||
## Prerequisites
|
||||
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
|||
# Google Hangouts agent alert notifications
|
||||
|
||||
[Google Hangouts](https://hangouts.google.com/) is a cross-platform messaging app developed by Google. You can configure
|
||||
Netdata to send alarm notifications to a Hangouts room in order to stay aware of possible health or performance issues
|
||||
Netdata to send alert notifications to a Hangouts room in order to stay aware of possible health or performance issues
|
||||
on your nodes. Here's an example of the notification in action:
|
||||
|
||||
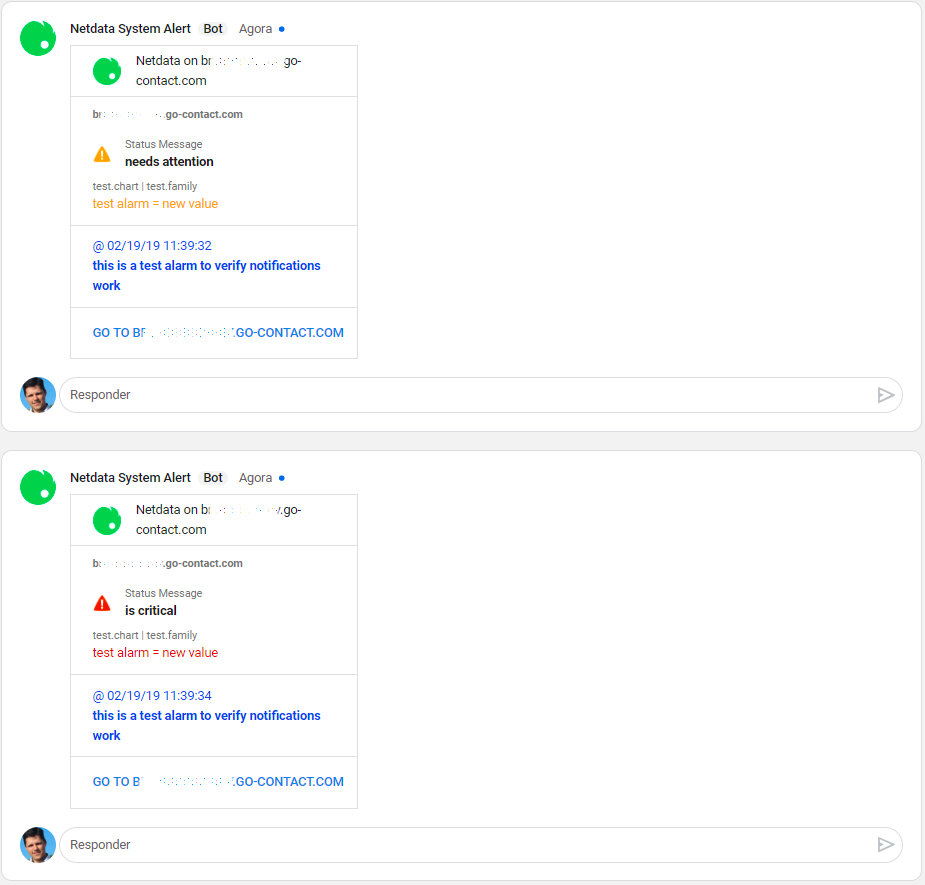
|
||||
|
|
@ -30,7 +30,7 @@ Set the webhook URIs and room names in `health_alarm_notify.conf`. To edit it on
|
|||
|
||||
## Threads (optional)
|
||||
|
||||
Instead to receive alarms on different threads, Netdata allows you to concentrate them inside an unique thread when you
|
||||
Instead, to receive alerts on different threads, Netdata allows you to concentrate them inside a unique thread when you
|
||||
set the variable `HANGOUTS_WEBHOOK_THREAD[NAME]`.
|
||||
|
||||
```
|
||||
|
|
@ -49,11 +49,11 @@ HANGOUTS_WEBHOOK_URI[development]="https://chat.googleapis.com/v1/spaces/AAAAYYY
|
|||
# if a DEFAULT_RECIPIENT_HANGOUTS are not configured,
|
||||
# notifications wouldn't be send to hangouts rooms.
|
||||
# DEFAULT_RECIPIENT_HANGOUTS="systems development|critical"
|
||||
DEFAULT_RECIPIENT_HANGOUTS="sysadmin devops alarms|critical"
|
||||
DEFAULT_RECIPIENT_HANGOUTS="sysadmin devops alerts|critical"
|
||||
```
|
||||
|
||||
You can define multiple rooms like this: `sysadmin devops alarms|critical`.
|
||||
You can define multiple rooms like this: `sysadmin devops alerts|critical`.
|
||||
|
||||
The keywords `sysadmin`, `devops`, and `alarms` are Hangouts rooms.
|
||||
The keywords `sysadmin`, `devops`, and `alerts` are Hangouts rooms.
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -49,13 +49,13 @@ Edit `health_alarm_notify.conf`, changes to this file do not require restarting
|
|||
|
||||
2. Set `SEND_IRC` to `YES`
|
||||
3. Set `DEFAULT_RECIPIENT_IRC` to one or more channels to post the messages to.
|
||||
You can define multiple channels like this: `#alarms #systems`.
|
||||
All roles will default to this variable if left unconfigured.
|
||||
You can define multiple channels like this: `#alerts #systems`.
|
||||
All roles will default to this variable if it is not configured.
|
||||
4. Set `IRC_NETWORK` to the IRC network which your preferred channels belong to.
|
||||
5. Set `IRC_PORT` to the IRC port to which a connection will occur.
|
||||
6. Set `IRC_NICKNAME` to the IRC nickname which is required to send the notification.
|
||||
It must not be an already registered name as the connection's `MODE` is defined as a `guest`.
|
||||
7. Set `IRC_REALNAME` to the IRC realname which is required in order to make he connection.
|
||||
7. Set `IRC_REALNAME` to the IRC realname which is required in order to make the connection.
|
||||
|
||||
You can then have different channels per **role**, by editing `DEFAULT_RECIPIENT_IRC` with the channel you want, in the following entries at the bottom of the same file:
|
||||
|
||||
|
|
@ -77,9 +77,9 @@ An example of a working configuration would be:
|
|||
# irc notification options
|
||||
#
|
||||
SEND_IRC="YES"
|
||||
DEFAULT_RECIPIENT_IRC="#system-alarms"
|
||||
DEFAULT_RECIPIENT_IRC="#system-alerts"
|
||||
IRC_NETWORK="irc.freenode.net"
|
||||
IRC_NICKNAME="netdata-alarm-user"
|
||||
IRC_NICKNAME="netdata-alert-user"
|
||||
IRC_REALNAME="netdata-user"
|
||||
```
|
||||
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ You will need:
|
|||
|
||||
- The url of the homeserver (`https://homeserver:port`).
|
||||
- Credentials for connecting to the homeserver, in the form of a valid access token for your account (or for a dedicated notification account). These tokens usually don't expire.
|
||||
- The room ids that you want to sent the notification to.
|
||||
- The room ids that you want to send the notification to.
|
||||
|
||||
## Configure Netdata to send alert notifications to Matrix
|
||||
|
||||
|
|
|
|||
|
|
@ -10,7 +10,7 @@ Learn how to send alerts to an ntfy server using Netdata's Agent alert notificat
|
|||
|
||||
This is what you will get:
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/5953192/230661442-a180abe2-c8bd-496e-88be-9038e62fb4f7.png" alt="Example alarm notifications in Ntfy" width="60%"></img>
|
||||
<img src="https://user-images.githubusercontent.com/5953192/230661442-a180abe2-c8bd-496e-88be-9038e62fb4f7.png" alt="Example alert notifications in Ntfy" width="60%"></img>
|
||||
|
||||
## Prerequisites
|
||||
|
||||
|
|
@ -37,7 +37,7 @@ Edit `health_alarm_notify.conf`, changes to this file do not require restarting
|
|||
2. Set `DEFAULT_RECIPIENT_NTFY` to the URL formed by the server-topic combination you want the alert notifications to be sent to. Unless you are hosting your own server, the server should always be set to [https://ntfy.sh](https://ntfy.sh)
|
||||
|
||||
You can define multiple recipient URLs like this: `https://SERVER1/TOPIC1 https://SERVER2/TOPIC2`
|
||||
All roles will default to this variable if left unconfigured.
|
||||
All roles will default to this variable if it is not configured.
|
||||
|
||||
> ### Warning
|
||||
> All topics published on https://ntfy.sh are public, so anyone can subscribe to them and follow your notifications. To avoid that, ensure the topic is unique enough using a long, randomly generated ID, like in the following examples.
|
||||
|
|
|
|||
|
|
@ -7,11 +7,10 @@ Learn how to send notifications to Opsgenie using Netdata's Agent alert notifica
|
|||
> This file assumes you have read the [Introduction to Agent alert notifications](https://github.com/netdata/netdata/blob/master/health/notifications/README.md), detailing how the Netdata Agent's alert notification method works.
|
||||
|
||||
[Opsgenie](https://www.atlassian.com/software/opsgenie) is an alerting and incident response tool.
|
||||
It is designed to group and filter alarms, build custom routing rules for on-call teams, and correlate deployments and commits to incidents.
|
||||
It is designed to group and filter alerts, build custom routing rules for on-call teams, and correlate deployments and commits to incidents.
|
||||
|
||||
This is what you will get:
|
||||

|
||||

|
||||
|
||||
## Prerequisites
|
||||
|
||||
|
|
|
|||
|
|
@ -34,7 +34,7 @@ Edit `health_alarm_notify.conf`, changes to this file do not require restarting
|
|||
2. Set `ROCKETCHAT_WEBHOOK_URL` to your webhook URL.
|
||||
3. Set `DEFAULT_RECIPIENT_ROCKETCHAT` to the channel you want the alert notifications to be sent to.
|
||||
You can define multiple channels like this: `alerts systems`.
|
||||
All roles will default to this variable if left unconfigured.
|
||||
All roles will default to this variable if it is not configured.
|
||||
|
||||
You can then have different channels per **role**, by editing `DEFAULT_RECIPIENT_ROCKETCHAT` with the channel you want, in the following entries at the bottom of the same file:
|
||||
|
||||
|
|
@ -57,7 +57,7 @@ An example of a working configuration would be:
|
|||
|
||||
SEND_ROCKETCHAT="YES"
|
||||
ROCKETCHAT_WEBHOOK_URL="<your_incoming_webhook_url>"
|
||||
DEFAULT_RECIPIENT_ROCKETCHAT="monitoring_alarms"
|
||||
DEFAULT_RECIPIENT_ROCKETCHAT="monitoring_alerts"
|
||||
```
|
||||
|
||||
## Test the notification method
|
||||
|
|
|
|||
|
|
@ -36,7 +36,7 @@ Edit `health_alarm_notify.conf`, changes to this file do not require restarting
|
|||
2. Set `SLACK_WEBHOOK_URL` to your Slack app's webhook URL.
|
||||
3. Set `DEFAULT_RECIPIENT_SLACK` to the Slack channel your Slack app is set to send messages to.
|
||||
The syntax for channels is `#channel` or `channel`.
|
||||
All roles will default to this variable if left unconfigured.
|
||||
All roles will default to this variable if it is not configured.
|
||||
|
||||
An example of a working configuration would be:
|
||||
|
||||
|
|
@ -46,7 +46,7 @@ An example of a working configuration would be:
|
|||
|
||||
SEND_SLACK="YES"
|
||||
SLACK_WEBHOOK_URL="https://hooks.slack.com/services/XXXXXXXX/XXXXXXXX/XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
|
||||
DEFAULT_RECIPIENT_SLACK="#alarms"
|
||||
DEFAULT_RECIPIENT_SLACK="#alerts"
|
||||
```
|
||||
|
||||
## Test the notification method
|
||||
|
|
|
|||
|
|
@ -15,7 +15,7 @@ learn_autogeneration_metadata: "{'part_of_cloud': False, 'part_of_agent': True}"
|
|||
It helps SREs, DevOps Engineers and Software Developers reduce toil and alert fatigue while improving reliability of
|
||||
software services by managing, analyzing and automating incident response activities.
|
||||
|
||||
Sending Netdata alarm notifications to StackPulse allows you to create smart automated response workflows
|
||||
Sending Netdata alert notifications to StackPulse allows you to create smart automated response workflows
|
||||
(StackPulse playbooks) that will help you drive down your MTTD and MTTR by performing any of the following:
|
||||
|
||||
- Enriching the incident with data from multiple sources
|
||||
|
|
@ -44,41 +44,41 @@ STACKPULSE_WEBHOOK="https://hooks.stackpulse.io/v1/webhooks/YOUR_UNIQUE_ID"
|
|||
```
|
||||
|
||||
4. Now restart Netdata using `sudo systemctl restart netdata`, or the [appropriate
|
||||
method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system. When your node creates an alarm, you can see the
|
||||
method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system. When your node creates an alert, you can see the
|
||||
associated notification on your StackPulse Administration Portal
|
||||
|
||||
## React to alarms with playbooks
|
||||
## React to alerts with playbooks
|
||||
|
||||
StackPulse allow users to create `Playbooks` giving additional information about events that happen in specific
|
||||
scenarios. For example, you could create a Playbook that responds to a "low disk space" alarm by compressing and
|
||||
scenarios. For example, you could create a Playbook that responds to a "low disk space" alert by compressing and
|
||||
cleaning up storage partitions with dynamic data.
|
||||
|
||||

|
||||
|
||||

|
||||
### Create Playbooks for Netdata alarms
|
||||

|
||||
|
||||
### Create Playbooks for Netdata alerts
|
||||
|
||||
To create a Playbook, you need to access the StackPulse Administration Portal. After the initial setup, you need to
|
||||
access the **TRIGGER** tab to define the scenarios used to trigger the event. The following variables are available:
|
||||
|
||||
- `Hostname`: The host that generated the event.
|
||||
- `Chart`: The name of the chart.
|
||||
- `OldValue` : The previous value of the alarm.
|
||||
- `Value`: The current value of the alarm.
|
||||
- `OldValue` : The previous value of the alert.
|
||||
- `Value`: The current value of the alert.
|
||||
- `Units` : The units of the value.
|
||||
- `OldStatus` : The previous status: REMOVED, UNINITIALIZED, UNDEFINED, CLEAR, WARNING, CRITICAL.
|
||||
- `State`: The current alarm status, the acceptable values are the same of `OldStatus`.
|
||||
- `Alarm` : The name of the alarm, as given in Netdata's health.d entries.
|
||||
- `State`: The current alert status, the acceptable values are the same of `OldStatus`.
|
||||
- `Alarm` : The name of the alert, as given in Netdata's health.d entries.
|
||||
- `Date` : The timestamp this event occurred.
|
||||
- `Duration` : The duration in seconds of the previous alarm state.
|
||||
- `Duration` : The duration in seconds of the previous alert state.
|
||||
- `NonClearDuration` : The total duration in seconds this is/was non-clear.
|
||||
- `Description` : A short description of the alarm copied from the alarm definition.
|
||||
- `CalcExpression` : The expression that was evaluated to trigger the alarm.
|
||||
- `Description` : A short description of the alert copied from the alert definition.
|
||||
- `CalcExpression` : The expression that was evaluated to trigger the alert.
|
||||
- `CalcParamValues` : The values of the parameters in the expression, at the time of the evaluation.
|
||||
- `TotalWarnings` : Total number of alarms in WARNING state.
|
||||
- `TotalCritical` : Total number of alarms in CRITICAL state.
|
||||
- `ID` : The unique id of the alarm that generated this event.
|
||||
- `TotalWarnings` : Total number of alerts in WARNING state.
|
||||
- `TotalCritical` : Total number of alerts in CRITICAL state.
|
||||
- `ID` : The unique id of the alert that generated this event.
|
||||
|
||||
For more details how to create a scenario, take a look at the [StackPulse documentation](https://docs.stackpulse.io).
|
||||
|
||||
|
|
|
|||
|
|
@ -267,7 +267,7 @@ The anomaly rate across all dimensions of a node.
|
|||
|
||||
- We would love to hear any feedback relating to this functionality, please email us at analytics-ml-team@netdata.cloud or come join us in the [🤖-ml-powered-monitoring](https://discord.gg/4eRSEUpJnc) channel of the Netdata discord.
|
||||
- We are working on additional UI/UX based features that build on these core components to make them as useful as possible out of the box.
|
||||
- Although not yet a core focus of this work, users could leverage the `anomaly_detection` chart dimensions and/or `anomaly-bit` options in defining alarms based on ML driven anomaly detection models.
|
||||
- Although not yet a core focus of this work, users could leverage the `anomaly_detection` chart dimensions and/or `anomaly-bit` options in defining alerts based on ML driven anomaly detection models.
|
||||
- [This presentation](https://docs.google.com/presentation/d/18zkCvU3nKP-Bw_nQZuXTEa4PIVM6wppH3VUnAauq-RU/edit?usp=sharing) walks through some of the main concepts covered above in a more informal way.
|
||||
- After restart Netdata will wait until `minimum num samples to train` observations of data are available before starting training and prediction.
|
||||
- Netdata uses [dlib](https://github.com/davisking/dlib) under the hood for its core ML features.
|
||||
|
|
|
|||
|
|
@ -51,10 +51,10 @@ learn more about [how data collectors work](https://github.com/netdata/netdata/b
|
|||
collector](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md) for metrics you need, [configure the collector](https://github.com/netdata/netdata/blob/master/collectors/REFERENCE.md)
|
||||
or read about its requirements to configure your endpoint to publish metrics in the correct format and endpoint.
|
||||
|
||||
#### Alarms & notifications
|
||||
#### Alerts & notifications
|
||||
|
||||
Netdata comes with hundreds of preconfigured alarms, designed by our monitoring gurus in parallel with our open-source
|
||||
community, but you may want to [edit alarms](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) or
|
||||
Netdata comes with hundreds of preconfigured alerts, designed by our monitoring gurus in parallel with our open-source
|
||||
community, but you may want to [edit alerts](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) or
|
||||
[enable notifications](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md) to customize your Netdata experience.
|
||||
|
||||
#### Make your deployment production ready
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ import TabItem from '@theme/TabItem';
|
|||
|
||||
This document details how to install Netdata on an existing Kubernetes (k8s) cluster, and connect it to Netdata Cloud. Read our [Kubernetes visualizations](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/kubernetes.md) documentation, to see what you will get.
|
||||
|
||||
The [Netdata Helm chart](https://github.com/netdata/helmchart/blob/master/charts/netdata/README.md) installs one `parent` pod for storing metrics and managing alarm notifications, plus an additional
|
||||
The [Netdata Helm chart](https://github.com/netdata/helmchart/blob/master/charts/netdata/README.md) installs one `parent` pod for storing metrics and managing alert notifications, plus an additional
|
||||
`child` pod for every node in the cluster, responsible for collecting metrics from the node, Kubernetes control planes,
|
||||
pods/containers, and [supported application-specific
|
||||
metrics](https://github.com/netdata/helmchart#service-discovery-and-supported-services).
|
||||
|
|
|
|||
|
|
@ -94,8 +94,8 @@ Netdata plugins and various aspects of Netdata can be enabled or benefit when th
|
|||
|
||||
| package |description|
|
||||
|:-----:|-----------|
|
||||
| `bash`|for shell plugins and **alarm notifications**|
|
||||
| `curl`|for shell plugins and **alarm notifications**|
|
||||
| `bash`|for shell plugins and **alert notifications**|
|
||||
| `curl`|for shell plugins and **alert notifications**|
|
||||
| `iproute` or `iproute2`|for monitoring **Linux traffic QoS**<br/>use `iproute2` if `iproute` reports as not available or obsolete|
|
||||
| `python`|for most of the external plugins|
|
||||
| `python-yaml`|used for monitoring **beanstalkd**|
|
||||
|
|
|
|||
|
|
@ -30,36 +30,36 @@ node**. This file is automatically generated by Netdata the first time it is sta
|
|||
|
||||
#### `[stream]` section
|
||||
|
||||
| Setting | Default | Description |
|
||||
| :---------------------------------------------- | :------------------------ | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| `enabled` | `no` | Whether this node streams metrics to any parent. Change to `yes` to enable streaming. |
|
||||
| [`destination`](#destination) | ` ` | A space-separated list of parent nodes to attempt to stream to, with the first available parent receiving metrics, using the following format: `[PROTOCOL:]HOST[%INTERFACE][:PORT][:SSL]`. [Read more →](#destination) |
|
||||
| `ssl skip certificate verification` | `yes` | If you want to accept self-signed or expired certificates, set to `yes` and uncomment. |
|
||||
| `CApath` | `/etc/ssl/certs/` | The directory where known certificates are found. Defaults to OpenSSL's default path. |
|
||||
| `CAfile` | `/etc/ssl/certs/cert.pem` | Add a parent node certificate to the list of known certificates in `CAPath`. |
|
||||
| `api key` | ` ` | The `API_KEY` to use as the child node. |
|
||||
| `timeout seconds` | `60` | The timeout to connect and send metrics to a parent. |
|
||||
| `default port` | `19999` | The port to use if `destination` does not specify one. |
|
||||
| [`send charts matching`](#send-charts-matching) | `*` | A space-separated list of [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) to filter which charts are streamed. [Read more →](#send-charts-matching) |
|
||||
| `buffer size bytes` | `10485760` | The size of the buffer to use when sending metrics. The default `10485760` equals a buffer of 10MB, which is good for 60 seconds of data. Increase this if you expect latencies higher than that. The buffer is flushed on reconnect. |
|
||||
| `reconnect delay seconds` | `5` | How long to wait until retrying to connect to the parent node. |
|
||||
| `initial clock resync iterations` | `60` | Sync the clock of charts for how many seconds when starting. |
|
||||
| Setting | Default | Description |
|
||||
|-------------------------------------------------|---------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| `enabled` | `no` | Whether this node streams metrics to any parent. Change to `yes` to enable streaming. |
|
||||
| [`destination`](#destination) | | A space-separated list of parent nodes to attempt to stream to, with the first available parent receiving metrics, using the following format: `[PROTOCOL:]HOST[%INTERFACE][:PORT][:SSL]`. [Read more →](#destination) |
|
||||
| `ssl skip certificate verification` | `yes` | If you want to accept self-signed or expired certificates, set to `yes` and uncomment. |
|
||||
| `CApath` | `/etc/ssl/certs/` | The directory where known certificates are found. Defaults to OpenSSL's default path. |
|
||||
| `CAfile` | `/etc/ssl/certs/cert.pem` | Add a parent node certificate to the list of known certificates in `CAPath`. |
|
||||
| `api key` | | The `API_KEY` to use as the child node. |
|
||||
| `timeout seconds` | `60` | The timeout to connect and send metrics to a parent. |
|
||||
| `default port` | `19999` | The port to use if `destination` does not specify one. |
|
||||
| [`send charts matching`](#send-charts-matching) | `*` | A space-separated list of [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) to filter which charts are streamed. [Read more →](#send-charts-matching) |
|
||||
| `buffer size bytes` | `10485760` | The size of the buffer to use when sending metrics. The default `10485760` equals a buffer of 10MB, which is good for 60 seconds of data. Increase this if you expect latencies higher than that. The buffer is flushed on reconnect. |
|
||||
| `reconnect delay seconds` | `5` | How long to wait until retrying to connect to the parent node. |
|
||||
| `initial clock resync iterations` | `60` | Sync the clock of charts for how many seconds when starting. |
|
||||
|
||||
### `[API_KEY]` and `[MACHINE_GUID]` sections
|
||||
|
||||
| Setting | Default | Description |
|
||||
| :---------------------------------------------- | :------------------------ | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| `enabled` | `no` | Whether this API KEY enabled or disabled. |
|
||||
| [`allow from`](#allow-from) | `*` | A space-separated list of [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) matching the IPs of nodes that will stream metrics using this API key. [Read more →](#allow-from) |
|
||||
| `default history` | `3600` | The default amount of child metrics history to retain when using the `save`, `map`, or `ram` memory modes. |
|
||||
| [`default memory mode`](#default-memory-mode) | `ram` | The [database](https://github.com/netdata/netdata/blob/master/database/README.md) to use for all nodes using this `API_KEY`. Valid settings are `dbengine`, `map`, `save`, `ram`, or `none`. [Read more →](#default-memory-mode) |
|
||||
| `health enabled by default` | `auto` | Whether alarms and notifications should be enabled for nodes using this `API_KEY`. `auto` enables alarms when the child is connected. `yes` enables alarms always, and `no` disables alarms. |
|
||||
| `default postpone alarms on connect seconds` | `60` | Postpone alarms and notifications for a period of time after the child connects. |
|
||||
| `default health log history` | `432000` | History of health log events (in seconds) kept in the database. |
|
||||
| `default proxy enabled` | ` ` | Route metrics through a proxy. |
|
||||
| `default proxy destination` | ` ` | Space-separated list of `IP:PORT` for proxies. |
|
||||
| `default proxy api key` | ` ` | The `API_KEY` of the proxy. |
|
||||
| `default send charts matching` | `*` | See [`send charts matching`](#send-charts-matching). |
|
||||
| Setting | Default | Description |
|
||||
|-----------------------------------------------|----------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| `enabled` | `no` | Whether this API KEY enabled or disabled. |
|
||||
| [`allow from`](#allow-from) | `*` | A space-separated list of [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) matching the IPs of nodes that will stream metrics using this API key. [Read more →](#allow-from) |
|
||||
| `default history` | `3600` | The default amount of child metrics history to retain when using the `save`, `map`, or `ram` memory modes. |
|
||||
| [`default memory mode`](#default-memory-mode) | `ram` | The [database](https://github.com/netdata/netdata/blob/master/database/README.md) to use for all nodes using this `API_KEY`. Valid settings are `dbengine`, `map`, `save`, `ram`, or `none`. [Read more →](#default-memory-mode) |
|
||||
| `health enabled by default` | `auto` | Whether alerts and notifications should be enabled for nodes using this `API_KEY`. `auto` enables alerts when the child is connected. `yes` enables alerts always, and `no` disables alerts. |
|
||||
| `default postpone alarms on connect seconds` | `60` | Postpone alerts and notifications for a period of time after the child connects. |
|
||||
| `default health log history` | `432000` | History of health log events (in seconds) kept in the database. |
|
||||
| `default proxy enabled` | | Route metrics through a proxy. |
|
||||
| `default proxy destination` | | Space-separated list of `IP:PORT` for proxies. |
|
||||
| `default proxy api key` | | The `API_KEY` of the proxy. |
|
||||
| `default send charts matching` | `*` | See [`send charts matching`](#send-charts-matching). |
|
||||
|
||||
#### `destination`
|
||||
|
||||
|
|
@ -145,24 +145,24 @@ cache size` and `dbengine multihost disk space` settings in the `[global]` secti
|
|||
|
||||
### `netdata.conf`
|
||||
|
||||
| Setting | Default | Description |
|
||||
| :----------------------------------------- | :---------------- | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| **`[global]` section** | | |
|
||||
| `memory mode` | `dbengine` | Determines the [database type](https://github.com/netdata/netdata/blob/master/database/README.md) to be used on that node. Other options settings include `none`, `ram`, `save`, and `map`. `none` disables the database at this host. This also disables alarms and notifications, as those can't run without a database. |
|
||||
| **`[web]` section** | | |
|
||||
| Setting | Default | Description |
|
||||
|--------------------------------------------|-------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| `[global]` section | | |
|
||||
| `memory mode` | `dbengine` | Determines the [database type](https://github.com/netdata/netdata/blob/master/database/README.md) to be used on that node. Other options settings include `none`, `ram`, `save`, and `map`. `none` disables the database at this host. This also disables alerts and notifications, as those can't run without a database. |
|
||||
| `[web]` section | | |
|
||||
| `mode` | `static-threaded` | Determines the [web server](https://github.com/netdata/netdata/blob/master/web/server/README.md) type. The other option is `none`, which disables the dashboard, API, and registry. |
|
||||
| `accept a streaming request every seconds` | `0` | Set a limit on how often a parent node accepts streaming requests from child nodes. `0` equals no limit. If this is set, you may see `... too busy to accept new streaming request. Will be allowed in X secs` in Netdata's `error.log`. |
|
||||
| `accept a streaming request every seconds` | `0` | Set a limit on how often a parent node accepts streaming requests from child nodes. `0` equals no limit. If this is set, you may see `... too busy to accept new streaming request. Will be allowed in X secs` in Netdata's `error.log`. |
|
||||
|
||||
### Basic use cases
|
||||
|
||||
This is an overview of how the main options can be combined:
|
||||
|
||||
| target|memory<br/>mode|web<br/>mode|stream<br/>enabled|exporting|alarms|dashboard|
|
||||
|------|:-------------:|:----------:|:----------------:|:-----:|:----:|:-------:|
|
||||
| headless collector|`none`|`none`|`yes`|only for `data source = as collected`|not possible|no|
|
||||
| headless proxy|`none`|not `none`|`yes`|only for `data source = as collected`|not possible|no|
|
||||
| proxy with db|not `none`|not `none`|`yes`|possible|possible|yes|
|
||||
| central netdata|not `none`|not `none`|`no`|possible|possible|yes|
|
||||
| target | memory<br/>mode | web<br/>mode | stream<br/>enabled | exporting | alerts | dashboard |
|
||||
|--------------------|:---------------:|:------------:|:------------------:|:-------------------------------------:|:------------:|:---------:|
|
||||
| headless collector | `none` | `none` | `yes` | only for `data source = as collected` | not possible | no |
|
||||
| headless proxy | `none` | not `none` | `yes` | only for `data source = as collected` | not possible | no |
|
||||
| proxy with db | not `none` | not `none` | `yes` | possible | possible | yes |
|
||||
| central netdata | not `none` | not `none` | `no` | possible | possible | yes |
|
||||
|
||||
### Per-child settings
|
||||
|
||||
|
|
@ -170,7 +170,7 @@ While the `[API_KEY]` section applies settings for any child node using that key
|
|||
with the `[MACHINE_GUID]` section.
|
||||
|
||||
For example, the metrics streamed from only the child node with `MACHINE_GUID` are saved in memory, not using the
|
||||
default `dbengine` as specified by the `API_KEY`, and alarms are disabled.
|
||||
default `dbengine` as specified by the `API_KEY`, and alerts are disabled.
|
||||
|
||||
```conf
|
||||
[API_KEY]
|
||||
|
|
@ -261,12 +261,12 @@ To enable stream compression:
|
|||
```
|
||||
|
||||
|
||||
| Parent | Stream compression | Child |
|
||||
|----------------------|--------------------|----------------------|
|
||||
| Supported & Enabled | compressed | Supported & Enabled |
|
||||
| (Supported & Disabled)/Not supported | uncompressed | Supported & Enabled |
|
||||
| Supported & Enabled | uncompressed | (Supported & Disabled)/Not supported |
|
||||
| (Supported & Disabled)/Not supported | uncompressed | (Supported & Disabled)/Not supported |
|
||||
| Parent | Stream compression | Child |
|
||||
|--------------------------------------|--------------------|--------------------------------------|
|
||||
| Supported & Enabled | compressed | Supported & Enabled |
|
||||
| (Supported & Disabled)/Not supported | uncompressed | Supported & Enabled |
|
||||
| Supported & Enabled | uncompressed | (Supported & Disabled)/Not supported |
|
||||
| (Supported & Disabled)/Not supported | uncompressed | (Supported & Disabled)/Not supported |
|
||||
|
||||
In case of parents with multiple children you can select which streams will be compressed by using the same configuration under the `[API_KEY]`, `[MACHINE_GUID]` section.
|
||||
|
||||
|
|
@ -383,7 +383,7 @@ following configurations:
|
|||
parameter (default is no).
|
||||
|
||||
| Parent TLS enabled | Parent port SSL | Child TLS | Child SSL Ver. | Behavior |
|
||||
| :----------------- | :--------------- | :-------- | :------------- | :--------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
|:-------------------|:-----------------|:----------|:---------------|:-----------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| No | - | No | no | Legacy behavior. The parent-child stream is unencrypted. |
|
||||
| Yes | force | No | no | The parent rejects the child connection. |
|
||||
| Yes | -/optional | No | no | The parent-child stream is unencrypted (expected situation for legacy child nodes and newer parent nodes) |
|
||||
|
|
@ -396,7 +396,7 @@ A proxy is a node that receives metrics from a child, then streams them onward t
|
|||
configure it as a receiving and a sending Netdata at the same time.
|
||||
|
||||
Netdata proxies may or may not maintain a database for the metrics passing through them. When they maintain a database,
|
||||
they can also run health checks (alarms and notifications) for the remote host that is streaming the metrics.
|
||||
they can also run health checks (alerts and notifications) for the remote host that is streaming the metrics.
|
||||
|
||||
In the following example, the proxy receives metrics from a child node using the `API_KEY` of
|
||||
`66666666-7777-8888-9999-000000000000`, then stores metrics using `dbengine`. It then uses the `API_KEY` of
|
||||
|
|
@ -431,7 +431,7 @@ On the parent, set the following in `stream.conf`:
|
|||
# do not save child metrics on disk
|
||||
default memory = ram
|
||||
|
||||
# alarms checks, only while the child is connected
|
||||
# alerts checks, only while the child is connected
|
||||
health enabled by default = auto
|
||||
```
|
||||
|
||||
|
|
@ -449,7 +449,7 @@ On the child nodes, set the following in `stream.conf`:
|
|||
api key = 11111111-2222-3333-4444-555555555555
|
||||
```
|
||||
|
||||
In addition, edit `netdata.conf` on each child node to disable the database and alarms.
|
||||
In addition, edit `netdata.conf` on each child node to disable the database and alerts.
|
||||
|
||||
```bash
|
||||
[global]
|
||||
|
|
|
|||
|
|
@ -77,11 +77,11 @@ Here is what you can put for `options` (these are standard Netdata API options):
|
|||
|
||||
- `alarm=NAME`
|
||||
|
||||
Render the current value and status of an alarm linked to the chart. This option can be ignored if the badge to be generated is not related to an alarm.
|
||||
Render the current value and status of an alert linked to the chart. This option can be ignored if the badge to be generated is not related to an alert.
|
||||
|
||||
The current value of the alarm will be rendered. The color of the badge will indicate the status of the alarm.
|
||||
The current value of the alert will be rendered. The color of the badge will indicate the status of the alert.
|
||||
|
||||
For alarm badges, **both `chart` and `alarm` parameters are required**.
|
||||
For alert badges, **both `chart` and `alarm` parameters are required**.
|
||||
|
||||
- `dimensions=DIMENSION1|DIMENSION2|...`
|
||||
|
||||
|
|
|
|||
|
|
@ -40,12 +40,12 @@ NETDATA_SYSTEM_CPU_VISIBLETOTAL=5
|
|||
echo ${NETDATA_SYSTEM_CPU_VISIBLETOTAL}
|
||||
5
|
||||
|
||||
# what about alarms?
|
||||
# what about alerts?
|
||||
set | grep "^NETDATA_ALARM_SYSTEM_SWAP_"
|
||||
NETDATA_ALARM_SYSTEM_SWAP_USED_SWAP_STATUS=CLEAR
|
||||
NETDATA_ALARM_SYSTEM_SWAP_USED_SWAP_VALUE=51
|
||||
|
||||
# let's get the current status of the alarm 'used swap'
|
||||
# let's get the current status of the alert 'used swap'
|
||||
echo ${NETDATA_ALARM_SYSTEM_SWAP_USED_SWAP_STATUS}
|
||||
CLEAR
|
||||
|
||||
|
|
|
|||
|
|
@ -12,23 +12,23 @@ learn_rel_path: "Developers/Web/Api"
|
|||
|
||||
## Health Read API
|
||||
|
||||
### Enabled Alarms
|
||||
### Enabled Alerts
|
||||
|
||||
Netdata enables alarms on demand, i.e. when the chart they should be linked to starts collecting data. So, although many
|
||||
more alarms are configured, only the useful ones are enabled.
|
||||
Netdata enables alerts on demand, i.e. when the chart they should be linked to starts collecting data. So, although many
|
||||
more alerts are configured, only the useful ones are enabled.
|
||||
|
||||
To get the list of all enabled alarms, open your browser and navigate to `http://NODE:19999/api/v1/alarms?all`,
|
||||
To get the list of all enabled alerts, open your browser and navigate to `http://NODE:19999/api/v1/alarms?all`,
|
||||
replacing `NODE` with the IP address or hostname for your Agent dashboard.
|
||||
|
||||
### Raised Alarms
|
||||
### Raised Alerts
|
||||
|
||||
This API call will return the alarms currently in WARNING or CRITICAL state.
|
||||
This API call will return the alerts currently in WARNING or CRITICAL state.
|
||||
|
||||
`http://NODE:19999/api/v1/alarms`
|
||||
|
||||
### Event Log
|
||||
|
||||
The size of the alarm log is configured in `netdata.conf`. There are 2 settings: the event history kept in the DB (in seconds), and the in memory size of the alarm log.
|
||||
The size of the alert log is configured in `netdata.conf`. There are 2 settings: the event history kept in the DB (in seconds), and the in memory size of the alert log.
|
||||
|
||||
```
|
||||
[health]
|
||||
|
|
@ -36,32 +36,32 @@ The size of the alarm log is configured in `netdata.conf`. There are 2 settings:
|
|||
health log history = 432000
|
||||
```
|
||||
|
||||
The API call retrieves all entries of the alarm log:
|
||||
The API call retrieves all entries of the alert log:
|
||||
|
||||
`http://NODE:19999/api/v1/alarm_log`
|
||||
|
||||
### Alarm Log Incremental Updates
|
||||
### Alert Log Incremental Updates
|
||||
|
||||
`http://NODE:19999/api/v1/alarm_log?after=UNIQUEID`
|
||||
|
||||
The above returns all the events in the alarm log that occurred after UNIQUEID (you poll it once without `after=`, remember the last UNIQUEID of the returned set, which you give back to get incrementally the next events).
|
||||
The above returns all the events in the alert log that occurred after UNIQUEID (you poll it once without `after=`, remember the last UNIQUEID of the returned set, which you give back to get incrementally the next events).
|
||||
|
||||
### Alarm badges
|
||||
### Alert badges
|
||||
|
||||
The following will return an SVG badge of the alarm named `NAME`, attached to the chart named `CHART`.
|
||||
The following will return an SVG badge of the alert named `NAME`, attached to the chart named `CHART`.
|
||||
|
||||
`http://NODE:19999/api/v1/badge.svg?alarm=NAME&chart=CHART`
|
||||
|
||||
## Health Management API
|
||||
|
||||
Netdata v1.12 and beyond provides a command API to control health checks and notifications at runtime. The feature is especially useful for maintenance periods, during which you receive meaningless alarms.
|
||||
Netdata v1.12 and beyond provides a command API to control health checks and notifications at runtime. The feature is especially useful for maintenance periods, during which you receive meaningless alerts.
|
||||
From Netdata v1.16.0 and beyond, the configuration controlled via the API commands is [persisted across Netdata restarts](#persistence).
|
||||
|
||||
Specifically, the API allows you to:
|
||||
|
||||
- Disable health checks completely. Alarm conditions will not be evaluated at all and no entries will be added to the alarm log.
|
||||
- Silence alarm notifications. Alarm conditions will be evaluated, the alarms will appear in the log and the Netdata UI will show the alarms as active, but no notifications will be sent.
|
||||
- Disable or Silence specific alarms that match selectors on alarm/template name, chart, context, host and family.
|
||||
- Disable health checks completely. Alert conditions will not be evaluated at all and no entries will be added to the alert log.
|
||||
- Silence alert notifications. Alert conditions will be evaluated, the alerts will appear in the log and the Netdata UI will show the alerts as active, but no notifications will be sent.
|
||||
- Disable or Silence specific alerts that match selectors on alert/template name, chart, context, host and family.
|
||||
|
||||
The API is available by default, but it is protected by an `api authorization token` that is stored in the file you will see in the following entry of `http://NODE:19999/netdata.conf`:
|
||||
|
||||
|
|
@ -81,7 +81,7 @@ By default access to the health management API is only allowed from `localhost`.
|
|||
The command `RESET` just returns Netdata to the default operation, with all health checks and notifications enabled.
|
||||
If you've configured and entered your token correctly, you should see the plain text response `All health checks and notifications are enabled`.
|
||||
|
||||
### Disable or silence all alarms
|
||||
### Disable or silence all alerts
|
||||
|
||||
If all you need is temporarily disable all health checks, then you issue the following before your maintenance period starts:
|
||||
|
||||
|
|
@ -89,14 +89,14 @@ If all you need is temporarily disable all health checks, then you issue the fol
|
|||
curl "http://NODE:19999/api/v1/manage/health?cmd=DISABLE ALL" -H "X-Auth-Token: Mytoken"
|
||||
```
|
||||
|
||||
The effect of disabling health checks is that the alarm criteria are not evaluated at all and nothing is written in the alarm log.
|
||||
The effect of disabling health checks is that the alert criteria are not evaluated at all and nothing is written in the alert log.
|
||||
If you want the health checks to be running but to not receive any notifications during your maintenance period, you can instead use this:
|
||||
|
||||
```sh
|
||||
curl "http://NODE:19999/api/v1/manage/health?cmd=SILENCE ALL" -H "X-Auth-Token: Mytoken"
|
||||
```
|
||||
|
||||
Alarms may then still be raised and logged in Netdata, so you'll be able to see them via the UI.
|
||||
Alerts may then still be raised and logged in Netdata, so you'll be able to see them via the UI.
|
||||
|
||||
Regardless of the option you choose, at the end of your maintenance period you revert to the normal state via the RESET command.
|
||||
|
||||
|
|
@ -104,25 +104,25 @@ Regardless of the option you choose, at the end of your maintenance period you r
|
|||
curl "http://NODE:19999/api/v1/manage/health?cmd=RESET" -H "X-Auth-Token: Mytoken"
|
||||
```
|
||||
|
||||
### Disable or silence specific alarms
|
||||
### Disable or silence specific alerts
|
||||
|
||||
If you do not wish to disable/silence all alarms, then the `DISABLE ALL` and `SILENCE ALL` commands can't be used.
|
||||
Instead, the following commands expect that one or more alarm selectors will be added, so that only alarms that match the selectors are disabled or silenced.
|
||||
If you do not wish to disable/silence all alerts, then the `DISABLE ALL` and `SILENCE ALL` commands can't be used.
|
||||
Instead, the following commands expect that one or more alert selectors will be added, so that only alerts that match the selectors are disabled or silenced.
|
||||
|
||||
- `DISABLE` : Set the mode to disable health checks.
|
||||
- `SILENCE` : Set the mode to silence notifications.
|
||||
|
||||
You will normally put one of these commands in the same request with your first alarm selector, but it's possible to issue them separately as well.
|
||||
You will normally put one of these commands in the same request with your first alert selector, but it's possible to issue them separately as well.
|
||||
You will get a warning in the response, if a selector was added without a SILENCE/DISABLE command, or vice versa.
|
||||
|
||||
Each request can specify a single alarm `selector`, with one or more `selection criteria`.
|
||||
A single alarm will match a `selector` if all selection criteria match the alarm.
|
||||
Each request can specify a single alert `selector`, with one or more `selection criteria`.
|
||||
A single alert will match a `selector` if all selection criteria match the alert.
|
||||
You can add as many selectors as you like.
|
||||
In essence, the rule is: IF (alarm matches all the criteria in selector1 OR all the criteria in selector2 OR ...) THEN apply the DISABLE or SILENCE command.
|
||||
In essence, the rule is: IF (alert matches all the criteria in selector1 OR all the criteria in selector2 OR ...) THEN apply the DISABLE or SILENCE command.
|
||||
|
||||
To clear all selectors and reset the mode to default, use the `RESET` command.
|
||||
|
||||
The following example silences notifications for all the alarms with context=load:
|
||||
The following example silences notifications for all the alerts with context=load:
|
||||
|
||||
```
|
||||
curl "http://NODE:19999/api/v1/manage/health?cmd=SILENCE&context=load" -H "X-Auth-Token: Mytoken"
|
||||
|
|
@ -138,9 +138,9 @@ The accepted keys for the `selection criteria` are the following:
|
|||
- `chart` : Chart ids/names, as shown on the dashboard. These will match the `on` entry of a configured `alarm`.
|
||||
- `context` : Chart context, as shown on the dashboard. These will match the `on` entry of a configured `template`.
|
||||
- `hosts` : The hostnames that will need to match.
|
||||
- `families` : The alarm families.
|
||||
- `families` : The alert families.
|
||||
|
||||
You can add any of the selection criteria you need on the request, to ensure that only the alarms you are interested in are matched and disabled/silenced. e.g. there is no reason to add `hosts: *`, if you want the criteria to be applied to alarms for all hosts.
|
||||
You can add any of the selection criteria you need on the request, to ensure that only the alerts you are interested in are matched and disabled/silenced. e.g. there is no reason to add `hosts: *`, if you want the criteria to be applied to alerts for all hosts.
|
||||
|
||||
Example 1: Disable all health checks for context = `random`
|
||||
|
||||
|
|
@ -148,13 +148,13 @@ Example 1: Disable all health checks for context = `random`
|
|||
http://NODE:19999/api/v1/manage/health?cmd=DISABLE&context=random
|
||||
```
|
||||
|
||||
Example 2: Silence all alarms and templates with name starting with `out_of` on host `myhost`
|
||||
Example 2: Silence all alerts and templates with name starting with `out_of` on host `myhost`
|
||||
|
||||
```
|
||||
http://NODE:19999/api/v1/manage/health?cmd=SILENCE&alarm=out_of*&hosts=myhost
|
||||
```
|
||||
|
||||
Example 2.2: Add one more selector, to also silence alarms for cpu1 and cpu2
|
||||
Example 2.2: Add one more selector, to also silence alerts for cpu1 and cpu2
|
||||
|
||||
```
|
||||
http://NODE:19999/api/v1/manage/health?families=cpu1 cpu2
|
||||
|
|
@ -168,7 +168,7 @@ The command `LIST` was added in Netdata v1.16.0 and returns a JSON with the curr
|
|||
curl "http://NODE:19999/api/v1/manage/health?cmd=LIST" -H "X-Auth-Token: Mytoken"
|
||||
```
|
||||
|
||||
As an example, the following response shows that we have two silencers configured, one for an alarm called `samplealarm` and one for alarms with context `random` on host `myhost`
|
||||
As an example, the following response shows that we have two silencers configured, one for an alert called `samplealert` and one for alerts with context `random` on host `myhost`
|
||||
|
||||
```
|
||||
json
|
||||
|
|
@ -177,7 +177,7 @@ json
|
|||
"type": "SILENCE",
|
||||
"silencers": [
|
||||
{
|
||||
"alarm": "samplealarm"
|
||||
"alarm": "samplealert"
|
||||
},
|
||||
{
|
||||
"context": "random",
|
||||
|
|
|
|||
|
|
@ -21,10 +21,10 @@ average = sum(numbers) / count(numbers)
|
|||
|
||||
## how to use
|
||||
|
||||
Use it in alarms like this:
|
||||
Use it in alerts like this:
|
||||
|
||||
```
|
||||
alarm: my_alarm
|
||||
alarm: my_alert
|
||||
on: my_chart
|
||||
lookup: average -1m unaligned of my_dimension
|
||||
warn: $this > 1000
|
||||
|
|
|
|||
|
|
@ -31,7 +31,7 @@ The target number and the desired condition can be set using the `group_options`
|
|||
|
||||
## how to use
|
||||
|
||||
This query cannot be used in alarms.
|
||||
This query cannot be used in alerts.
|
||||
|
||||
`countif` changes the units of charts. The result of the calculation is always from zero to 1, expressing the percentage of database points that matched the condition.
|
||||
|
||||
|
|
|
|||
|
|
@ -46,10 +46,10 @@ You can change the fixed value `15` by setting in `netdata.conf`:
|
|||
|
||||
## how to use
|
||||
|
||||
Use it in alarms like this:
|
||||
Use it in alerts like this:
|
||||
|
||||
```
|
||||
alarm: my_alarm
|
||||
alarm: my_alert
|
||||
on: my_chart
|
||||
lookup: des -1m unaligned of my_dimension
|
||||
warn: $this > 1000
|
||||
|
|
|
|||
|
|
@ -15,10 +15,10 @@ The result may be positive (rising) or negative (falling) depending on the first
|
|||
|
||||
## how to use
|
||||
|
||||
Use it in alarms like this:
|
||||
Use it in alerts like this:
|
||||
|
||||
```
|
||||
alarm: my_alarm
|
||||
alarm: my_alert
|
||||
on: my_chart
|
||||
lookup: incremental_sum -1m unaligned of my_dimension
|
||||
warn: $this > 1000
|
||||
|
|
|
|||
|
|
@ -13,10 +13,10 @@ This module finds the max value in the time-frame given.
|
|||
|
||||
## how to use
|
||||
|
||||
Use it in alarms like this:
|
||||
Use it in alerts like this:
|
||||
|
||||
```
|
||||
alarm: my_alarm
|
||||
alarm: my_alert
|
||||
on: my_chart
|
||||
lookup: max -1m unaligned of my_dimension
|
||||
warn: $this > 1000
|
||||
|
|
|
|||
|
|
@ -33,10 +33,10 @@ The function `trimmed-median` is an alias for `trimmed-median5`.
|
|||
|
||||
## how to use
|
||||
|
||||
Use it in alarms like this:
|
||||
Use it in alerts like this:
|
||||
|
||||
```
|
||||
alarm: my_alarm
|
||||
alarm: my_alert
|
||||
on: my_chart
|
||||
lookup: median -1m unaligned of my_dimension
|
||||
warn: $this > 1000
|
||||
|
|
|
|||
|
|
@ -13,10 +13,10 @@ This module finds the min value in the time-frame given.
|
|||
|
||||
## how to use
|
||||
|
||||
Use it in alarms like this:
|
||||
Use it in alerts like this:
|
||||
|
||||
```
|
||||
alarm: my_alarm
|
||||
alarm: my_alert
|
||||
on: my_chart
|
||||
lookup: min -1m unaligned of my_dimension
|
||||
warn: $this > 1000
|
||||
|
|
|
|||
|
|
@ -33,10 +33,10 @@ Any percentile may be requested using the `group_options` query parameter.
|
|||
|
||||
## how to use
|
||||
|
||||
Use it in alarms like this:
|
||||
Use it in alerts like this:
|
||||
|
||||
```
|
||||
alarm: my_alarm
|
||||
alarm: my_alert
|
||||
on: my_chart
|
||||
lookup: percentile95 -1m unaligned of my_dimension
|
||||
warn: $this > 1000
|
||||
|
|
|
|||
|
|
@ -34,10 +34,10 @@ You can change the fixed value `15` by setting in `netdata.conf`:
|
|||
|
||||
## how to use
|
||||
|
||||
Use it in alarms like this:
|
||||
Use it in alerts like this:
|
||||
|
||||
```
|
||||
alarm: my_alarm
|
||||
alarm: my_alert
|
||||
on: my_chart
|
||||
lookup: ses -1m unaligned of my_dimension
|
||||
warn: $this > 1000
|
||||
|
|
|
|||
|
|
@ -18,10 +18,10 @@ out over a wider range of values.
|
|||
|
||||
## how to use
|
||||
|
||||
Use it in alarms like this:
|
||||
Use it in alerts like this:
|
||||
|
||||
```
|
||||
alarm: my_alarm
|
||||
alarm: my_alert
|
||||
on: my_chart
|
||||
lookup: stddev -1m unaligned of my_dimension
|
||||
warn: $this > 1000
|
||||
|
|
@ -61,16 +61,16 @@ and its standard deviation is 100 (meaning that it variates from 900 to 1100), t
|
|||
|
||||
This is an easy way to check the % variation, without using absolute values.
|
||||
|
||||
For example, you may trigger an alarm if your web server requests/sec `cv` is above 20 (`%`)
|
||||
For example, you may trigger an alert if your web server requests/sec `cv` is above 20 (`%`)
|
||||
over the last minute. So if your web server was serving 1000 reqs/sec over the last minute,
|
||||
it will trigger the alarm if had spikes below 800/sec or above 1200/sec.
|
||||
it will trigger the alert if had spikes below 800/sec or above 1200/sec.
|
||||
|
||||
## how to use
|
||||
|
||||
Use it in alarms like this:
|
||||
Use it in alerts like this:
|
||||
|
||||
```
|
||||
alarm: my_alarm
|
||||
alarm: my_alert
|
||||
on: my_chart
|
||||
lookup: cv -1m unaligned of my_dimension
|
||||
units: %
|
||||
|
|
|
|||
|
|
@ -31,10 +31,10 @@ Any percentage may be requested using the `group_options` query parameter.
|
|||
|
||||
## how to use
|
||||
|
||||
Use it in alarms like this:
|
||||
Use it in alerts like this:
|
||||
|
||||
```
|
||||
alarm: my_alarm
|
||||
alarm: my_alert
|
||||
on: my_chart
|
||||
lookup: trimmed-mean5 -1m unaligned of my_dimension
|
||||
warn: $this > 1000
|
||||
|
|
|
|||
|
|
@ -73,7 +73,7 @@ like this (type `{html` for the html box to appear - you need the confluence htm
|
|||
|
||||
### Add a few badges
|
||||
|
||||
Then, go to your Netdata and copy an alarm badge (the `<embed>` version of it):
|
||||
Then, go to your Netdata and copy an alert badge (the `<embed>` version of it):
|
||||
|
||||
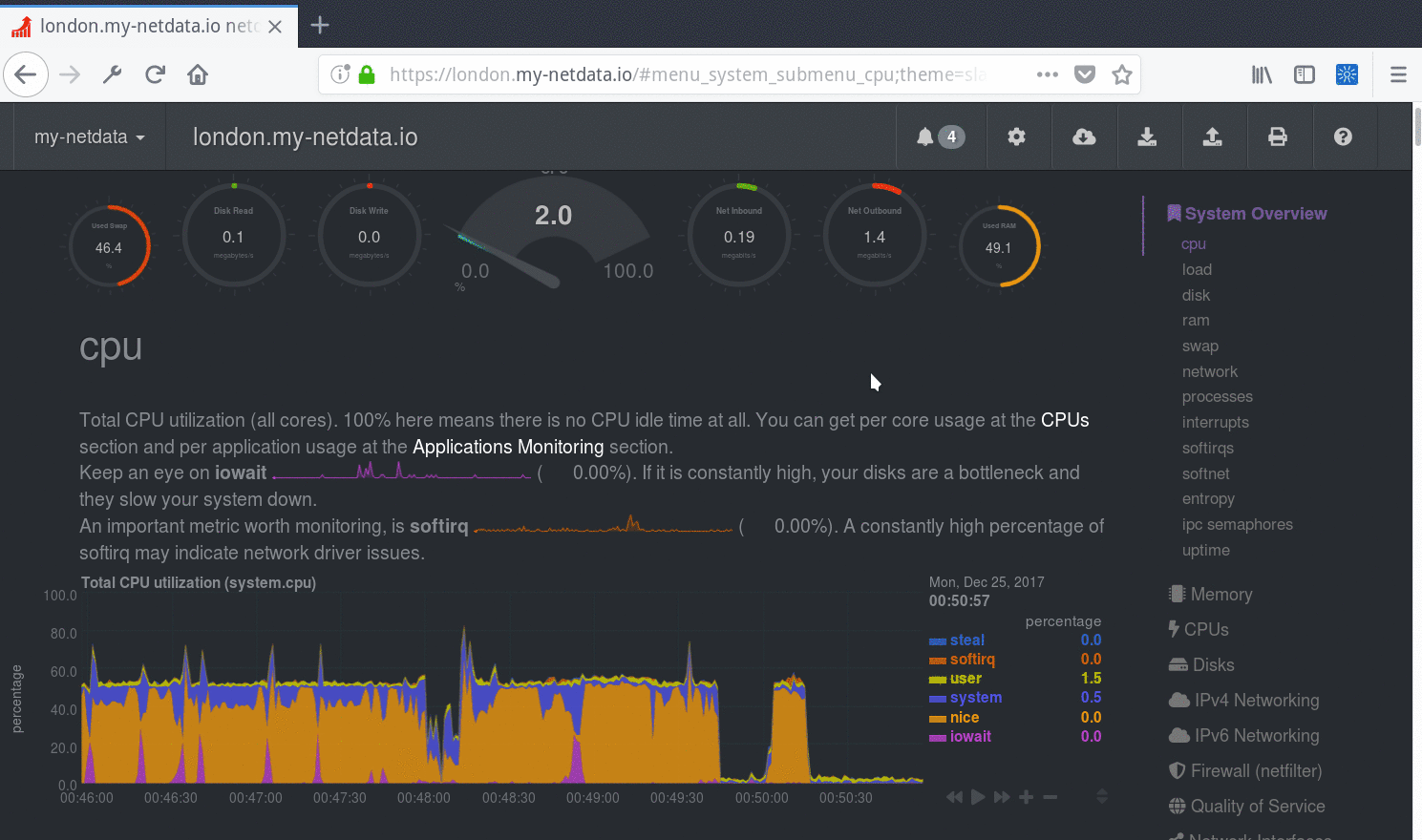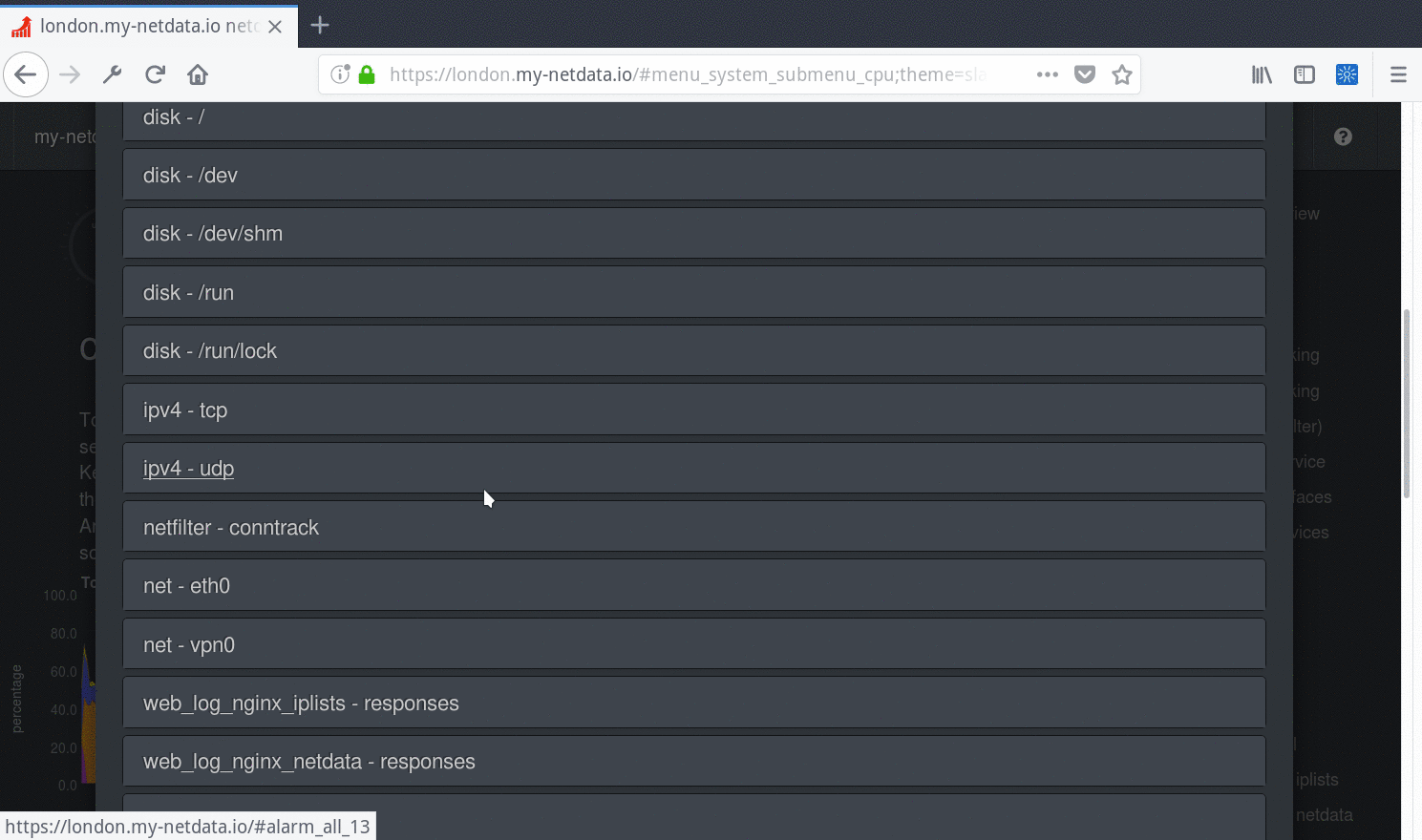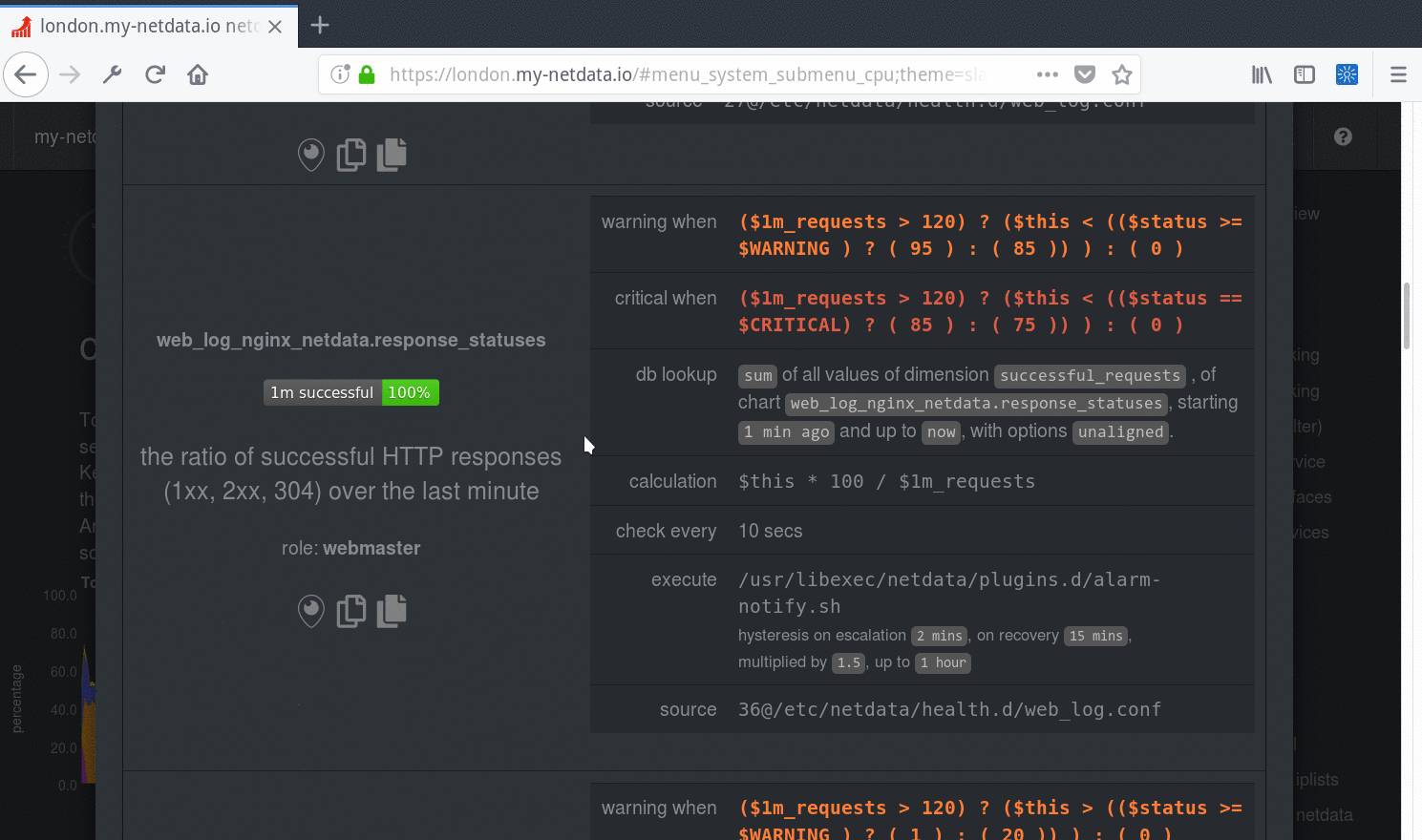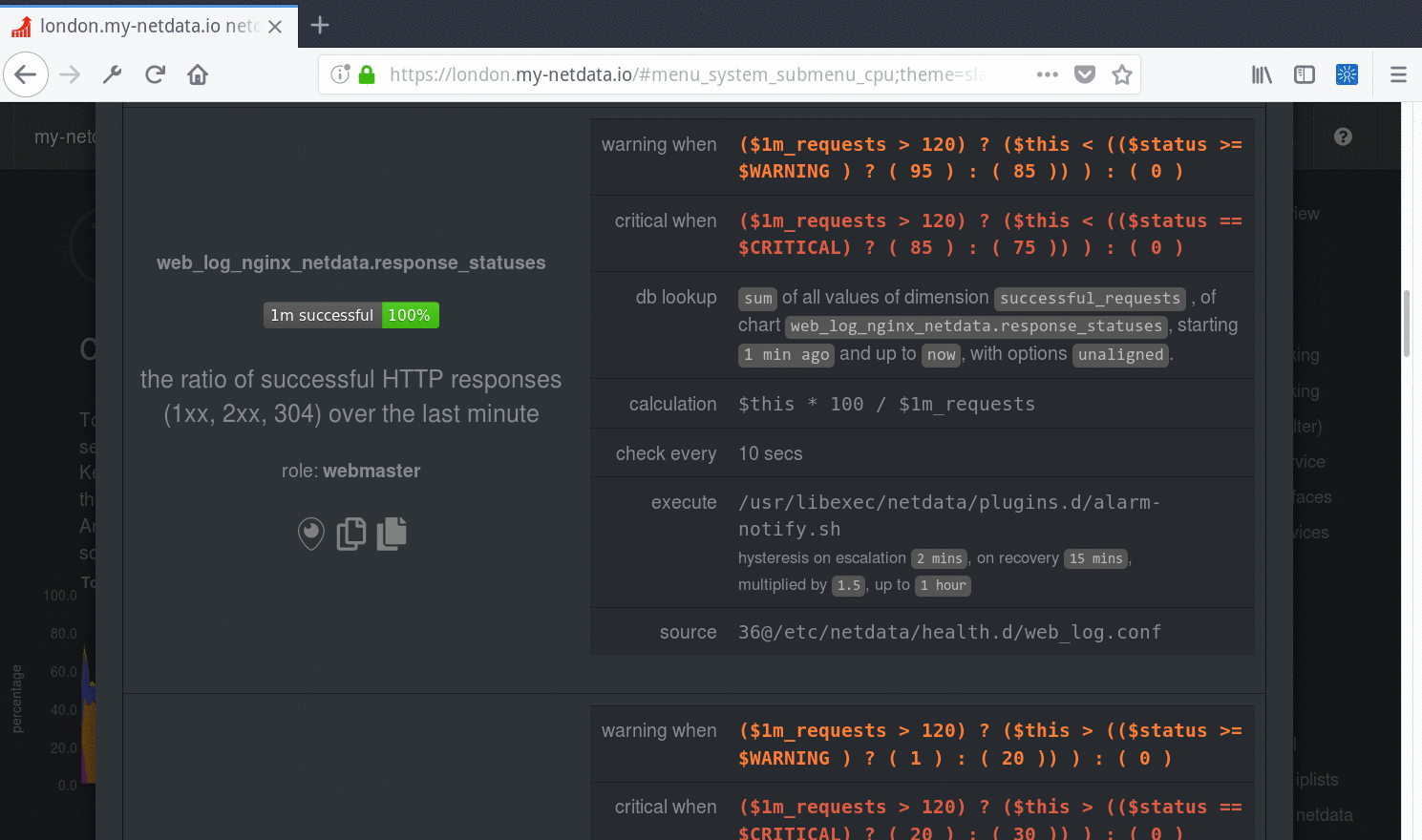
|
||||
|
||||
|
|
@ -85,10 +85,10 @@ Hit **update** and you will get this:
|
|||
|
||||

|
||||
|
||||
This badge is now auto-refreshing. It will update itself based on the update frequency of the alarm.
|
||||
This badge is now auto-refreshing. It will update itself based on the update frequency of the alert.
|
||||
|
||||
> Keep in mind you can add badges with custom Netdata queries too. Netdata automatically creates badges for all the
|
||||
> alarms, but every chart, every dimension on every chart, can be used for a badge. And Netdata badges are quite
|
||||
> alerts, but every chart, every dimension on every chart, can be used for a badge. And Netdata badges are quite
|
||||
> powerful! Check [Creating Badges](https://github.com/netdata/netdata/blob/master/web/api/badges/README.md) for more information on badges.
|
||||
|
||||
So, let's create a table and add this badge for both our web servers:
|
||||
|
|
|
|||
Loading…
Add table
Reference in a new issue