mirror of
https://github.com/netdata/netdata.git
synced 2025-02-18 19:32:36 +00:00
234 lines
13 KiB
Text
234 lines
13 KiB
Text
# Kubernetes monitoring with Netdata
|
|
|
|
This document gives an overview of what visualizations Netdata provides on Kubernetes deployments.
|
|
|
|
At Netdata, we've built Kubernetes monitoring tools that add visibility without complexity while also helping you
|
|
actively troubleshoot anomalies or outages. This guide walks you through each of the visualizations and offers best
|
|
practices on how to use them to start Kubernetes monitoring in a matter of minutes, not hours or days.
|
|
|
|
Netdata's Kubernetes monitoring solution uses a handful of [complementary tools and
|
|
collectors](#related-reference-documentation) for peeling back the many complex layers of a Kubernetes cluster,
|
|
_entirely for free_. These methods work together to give you every metric you need to troubleshoot performance or
|
|
availability issues across your Kubernetes infrastructure.
|
|
|
|
## Challenge
|
|
|
|
While Kubernetes (k8s) might simplify the way you deploy, scale, and load-balance your applications, not all clusters
|
|
come with "batteries included" when it comes to monitoring. Doubly so for a monitoring stack that helps you actively
|
|
troubleshoot issues with your cluster.
|
|
|
|
Some k8s providers, like GKE (Google Kubernetes Engine), do deploy clusters bundled with monitoring capabilities, such
|
|
as Google Stackdriver Monitoring. However, these pre-configured solutions might not offer the depth of metrics,
|
|
customization, or integration with your preferred alerting methods.
|
|
|
|
Without this visibility, it's like you built an entire house and _then_ smashed your way through the finished walls to
|
|
add windows.
|
|
|
|
## Solution
|
|
|
|
In this tutorial, you'll learn how to navigate Netdata's Kubernetes monitoring features, using
|
|
[robot-shop](https://github.com/instana/robot-shop) as an example deployment. Deploying robot-shop is purely optional.
|
|
You can also follow along with your own Kubernetes deployment if you choose. While the metrics might be different, the
|
|
navigation and best practices are the same for every cluster.
|
|
|
|
## What you need to get started
|
|
|
|
To follow this tutorial, you need:
|
|
|
|
- A free Netdata Cloud account. [Sign up](https://app.netdata.cloud/sign-up?cloudRoute=/spaces) if you don't have one
|
|
already.
|
|
- A working cluster running Kubernetes v1.9 or newer, with a Netdata deployment and connected parent/child nodes. See
|
|
our [Kubernetes deployment process](/packaging/installer/methods/kubernetes.md) for details on deployment and
|
|
connecting to Cloud.
|
|
- The [`kubectl`](https://kubernetes.io/docs/reference/kubectl/overview/) command line tool, within [one minor version
|
|
difference](https://kubernetes.io/docs/tasks/tools/install-kubectl/#before-you-begin) of your cluster, on an
|
|
administrative system.
|
|
- The [Helm package manager](https://helm.sh/) v3.0.0 or newer on the same administrative system.
|
|
|
|
### Install the `robot-shop` demo (optional)
|
|
|
|
Begin by downloading the robot-shop code and using `helm` to create a new deployment.
|
|
|
|
```bash
|
|
git clone git@github.com:instana/robot-shop.git
|
|
cd robot-shop/K8s/helm
|
|
kubectl create ns robot-shop
|
|
helm install robot-shop --namespace robot-shop .
|
|
```
|
|
|
|
Running `kubectl get pods` shows both the Netdata and robot-shop deployments.
|
|
|
|
```bash
|
|
kubectl get pods --all-namespaces
|
|
NAMESPACE NAME READY STATUS RESTARTS AGE
|
|
default netdata-child-29f9c 2/2 Running 0 10m
|
|
default netdata-child-8xphf 2/2 Running 0 10m
|
|
default netdata-child-jdvds 2/2 Running 0 11m
|
|
default netdata-parent-554c755b7d-qzrx4 1/1 Running 0 11m
|
|
kube-system aws-node-jnjv8 1/1 Running 0 17m
|
|
kube-system aws-node-svzdb 1/1 Running 0 17m
|
|
kube-system aws-node-ts6n2 1/1 Running 0 17m
|
|
kube-system coredns-559b5db75d-f58hp 1/1 Running 0 22h
|
|
kube-system coredns-559b5db75d-tkzj2 1/1 Running 0 22h
|
|
kube-system kube-proxy-9p9cd 1/1 Running 0 17m
|
|
kube-system kube-proxy-lt9ss 1/1 Running 0 17m
|
|
kube-system kube-proxy-n75t9 1/1 Running 0 17m
|
|
robot-shop cart-b4bbc8fff-t57js 1/1 Running 0 14m
|
|
robot-shop catalogue-8b5f66c98-mr85z 1/1 Running 0 14m
|
|
robot-shop dispatch-67d955c7d8-lnr44 1/1 Running 0 14m
|
|
robot-shop mongodb-7f65d86c-dsslc 1/1 Running 0 14m
|
|
robot-shop mysql-764c4c5fc7-kkbnf 1/1 Running 0 14m
|
|
robot-shop payment-67c87cb7d-5krxv 1/1 Running 0 14m
|
|
robot-shop rabbitmq-5bb66bb6c9-6xr5b 1/1 Running 0 14m
|
|
robot-shop ratings-94fd9c75b-42wvh 1/1 Running 0 14m
|
|
robot-shop redis-0 0/1 Pending 0 14m
|
|
robot-shop shipping-7d69cb88b-w7hpj 1/1 Running 0 14m
|
|
robot-shop user-79c445b44b-hwnm9 1/1 Running 0 14m
|
|
robot-shop web-8bb887476-lkcjx 1/1 Running 0 14m
|
|
```
|
|
|
|
## Explore Netdata's Kubernetes monitoring charts
|
|
|
|
The Netdata Helm chart deploys and enables everything you need for monitoring Kubernetes on every layer. Once you deploy
|
|
Netdata and connect your cluster's nodes, you're ready to check out the visualizations **with zero configuration**.
|
|
|
|
To get started, [sign in](https://app.netdata.cloud/sign-in?cloudRoute=/spaces) to your Netdata Cloud account. Head over
|
|
to the Room you connected your cluster to, if not **General**.
|
|
|
|
Let's walk through monitoring each layer of a Kubernetes cluster using the Overview as our framework.
|
|
|
|
## Cluster and node metrics
|
|
|
|
The gauges and time-series charts you see right away in the Overview show aggregated metrics from every node in your
|
|
cluster.
|
|
|
|
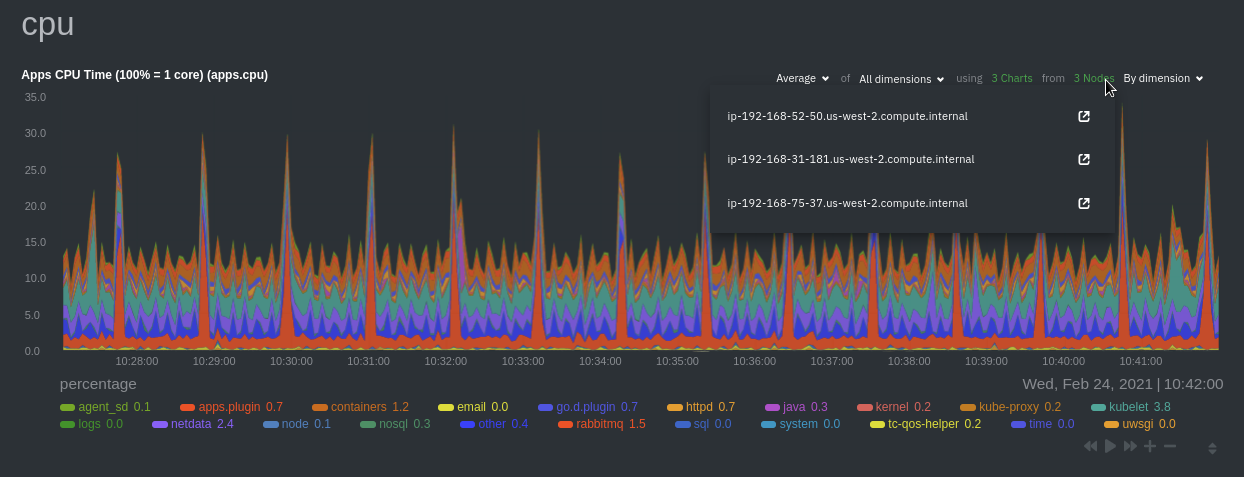
For example, the `apps.cpu` chart (in the **Applications** menu item), visualizes the CPU utilization of various
|
|
applications/services running on each of the nodes in your cluster. The **X Nodes** dropdown shows which nodes
|
|
contribute to the chart and links to jump a single-node dashboard for further investigation.
|
|
|
|
|
|
|
|
For example, the chart above shows a spike in the CPU utilization from `rabbitmq` every minute or so, along with a
|
|
baseline CPU utilization of 10-15% across the cluster.
|
|
|
|
## Pod and container metrics
|
|
|
|
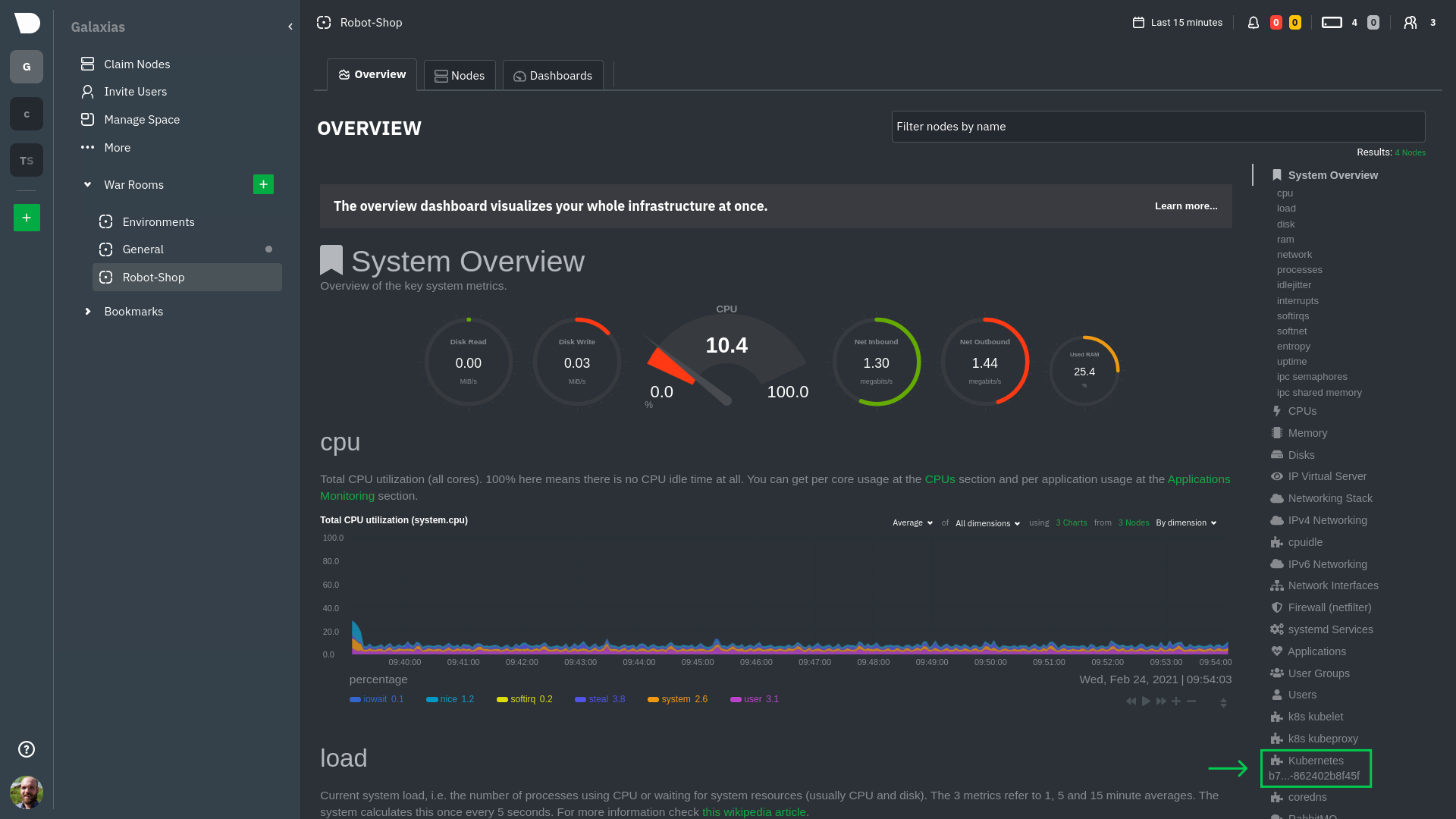
Click on the **Kubernetes xxxxxxx...** section to jump down to Netdata Cloud's unique Kubernetes visualizations for view
|
|
real-time resource utilization metrics from your Kubernetes pods and containers.
|
|
|
|
|
|
|
|
### Health map
|
|
|
|
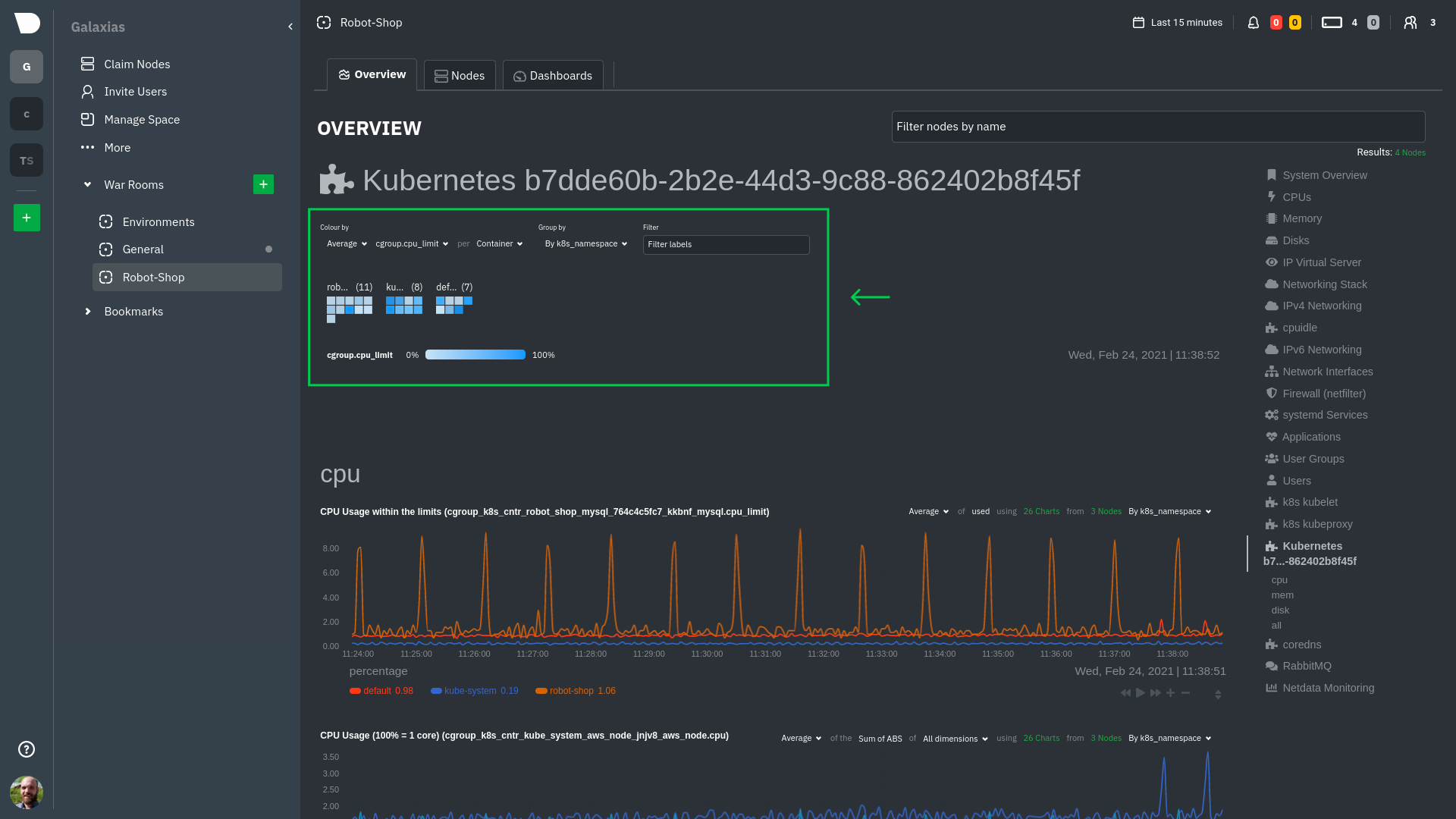
The first visualization is the [health map](/docs/dashboards-and-charts/kubernetes-tab.md#health-map),
|
|
which places each container into its own box, then varies the intensity of their color to visualize the resource
|
|
utilization. By default, the health map shows the **average CPU utilization as a percentage of the configured limit**
|
|
for every container in your cluster.
|
|
|
|
|
|
|
|
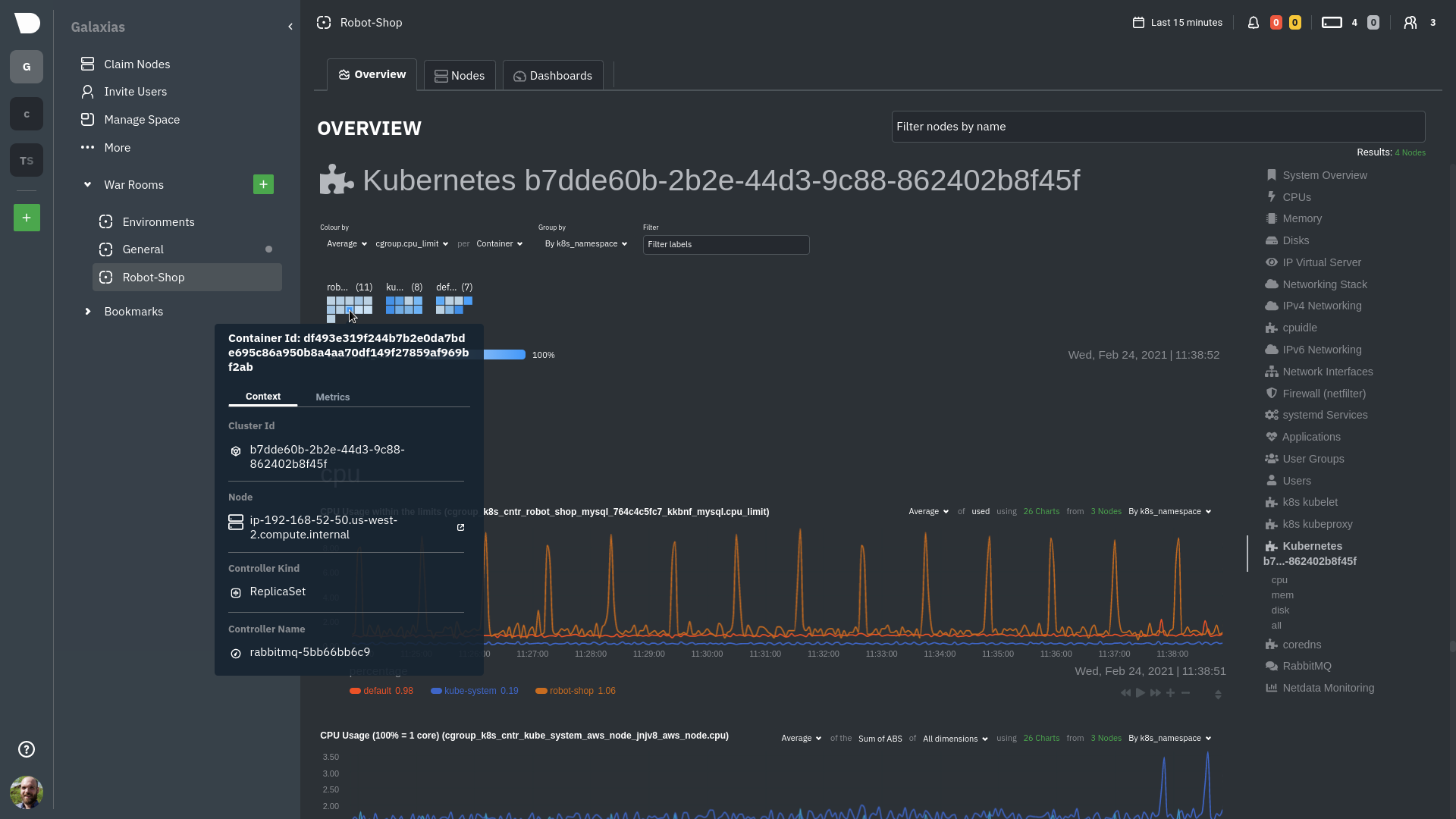
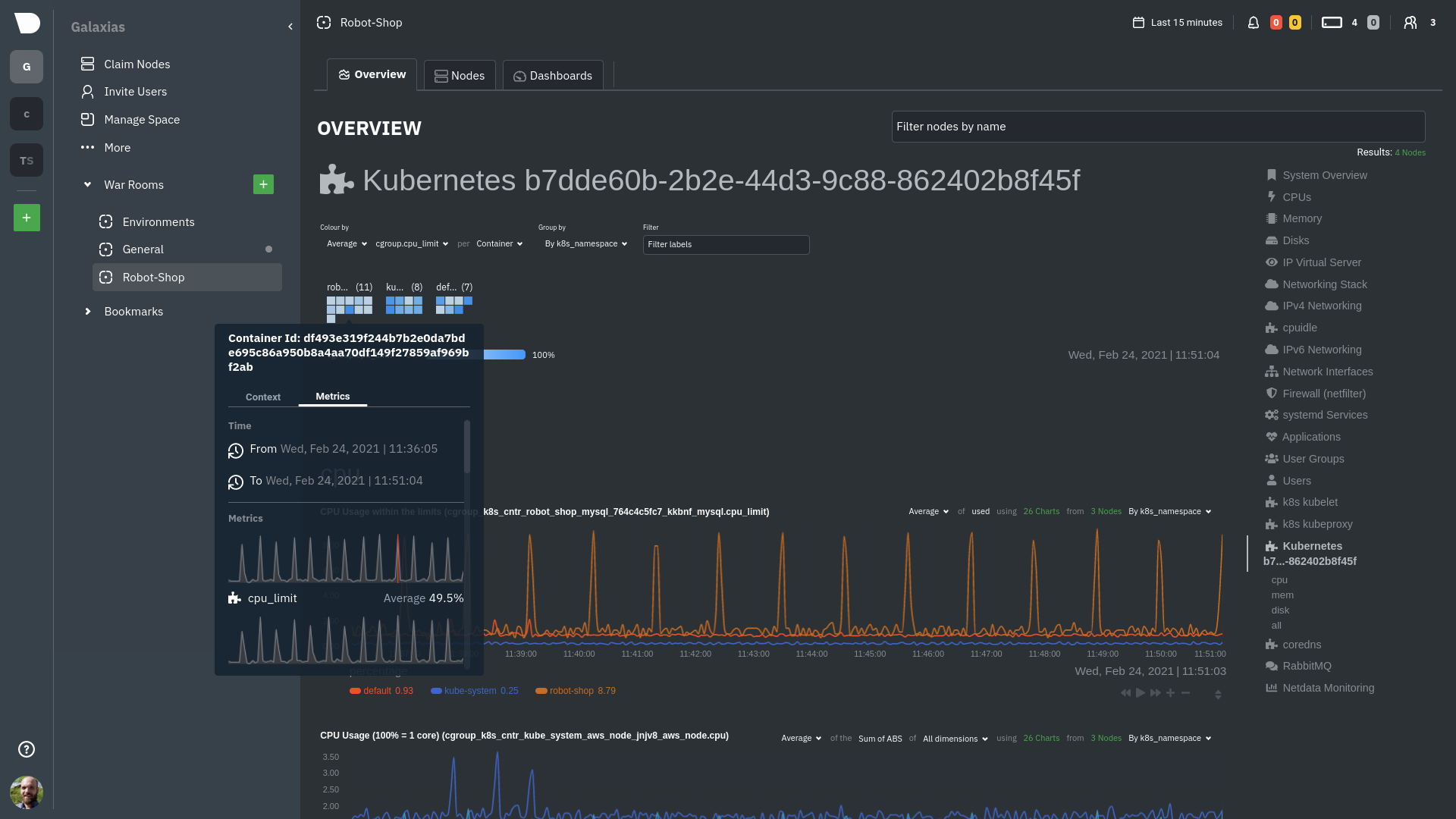
Let's explore the most colorful box by hovering over it.
|
|
|
|
|
|
|
|
The **Context** tab shows `rabbitmq-5bb66bb6c9-6xr5b` as the container's image name, which means this container is
|
|
running a [RabbitMQ](/src/go/plugin/go.d/collector/rabbitmq/README.md) workload.
|
|
|
|
Click the **Metrics** tab to see real-time metrics from that container. Unsurprisingly, it shows a spike in CPU
|
|
utilization at regular intervals.
|
|
|
|
|
|
|
|
### Time-series charts
|
|
|
|
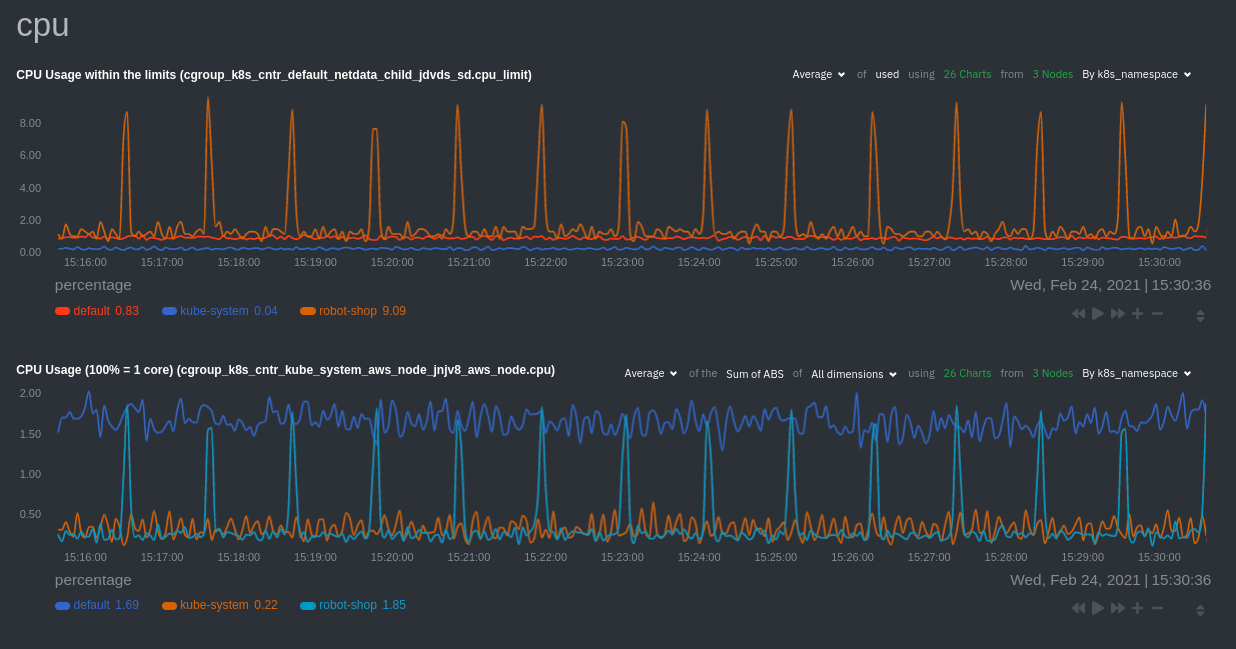
Beneath the health map is a variety of time-series charts that help you visualize resource utilization over time, which
|
|
is useful for targeted troubleshooting.
|
|
|
|
The default is to display metrics grouped by the `k8s_namespace` label, which shows resource utilization based on your
|
|
different namespaces.
|
|
|
|
|
|
|
|
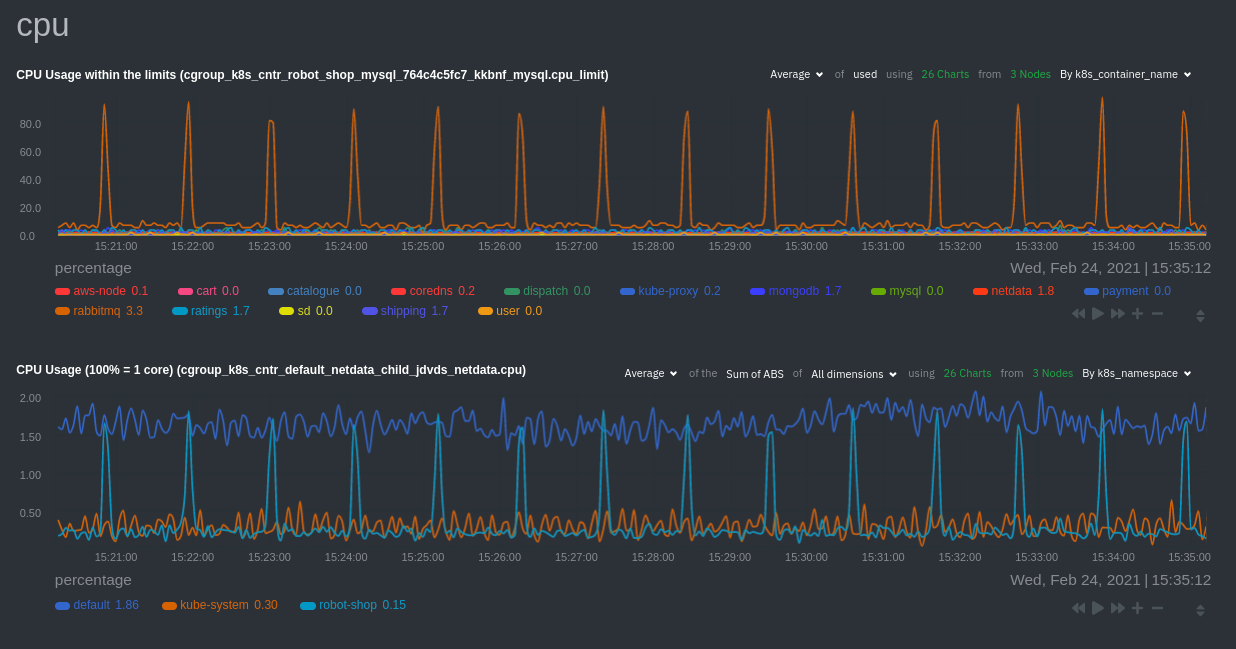
Each composite chart has a [definition bar](/docs/dashboards-and-charts/netdata-charts.md#definition-bar)
|
|
for complete customization. For example, grouping the top chart by `k8s_container_name` reveals new information.
|
|
|
|
|
|
|
|
## Service metrics
|
|
|
|
Netdata has a [service discovery plugin](https://github.com/netdata/agent-service-discovery), which discovers and
|
|
creates configuration files for [compatible
|
|
services](https://github.com/netdata/helmchart#service-discovery-and-supported-services) and any endpoints covered by
|
|
our [generic Prometheus collector](/src/go/plugin/go.d/collector/prometheus/README.md).
|
|
Netdata uses these files to collect metrics from any compatible application as they run _inside_ of a pod. Service
|
|
discovery happens without manual intervention as pods are created, destroyed, or moved between nodes.
|
|
|
|
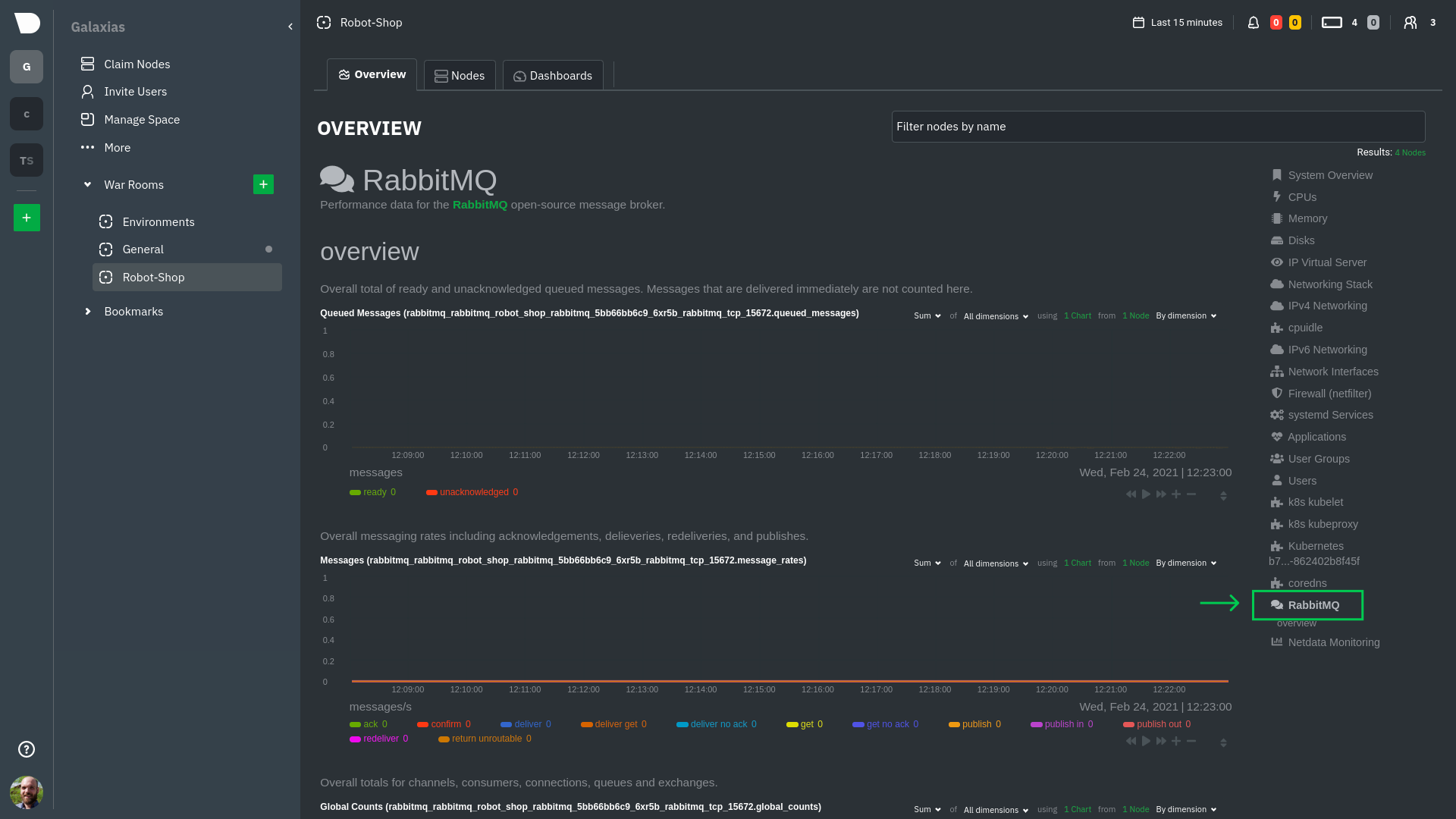
Service metrics show up on the Overview as well, beneath the **Kubernetes** section, and are labeled according to the
|
|
service in question. For example, the **RabbitMQ** section has numerous charts from the [`rabbitmq`
|
|
collector](/src/go/plugin/go.d/collector/rabbitmq/README.md):
|
|
|
|
|
|
|
|
> The robot-shop cluster has more supported services, such as MySQL, which are not visible with zero configuration. This
|
|
> is usually because of services running on non-default ports, using non-default names, or required passwords. Read up
|
|
> on [configuring service discovery](/packaging/installer/methods/kubernetes.md#configure-service-discovery) to collect
|
|
> more service metrics.
|
|
|
|
Service metrics are essential to infrastructure monitoring, as they're the best indicator of the end-user experience,
|
|
and key signals for troubleshooting anomalies or issues.
|
|
|
|
## Kubernetes components
|
|
|
|
Netdata also automatically collects metrics from two essential Kubernetes processes.
|
|
|
|
### kubelet
|
|
|
|
The **k8s kubelet** section visualizes metrics from the Kubernetes agent responsible for managing every pod on a given
|
|
node. This also happens without any configuration thanks to the [kubelet
|
|
collector](/src/go/plugin/go.d/collector/k8s_kubelet/README.md).
|
|
|
|
Monitoring each node's kubelet can be invaluable when diagnosing issues with your Kubernetes cluster. For example, you
|
|
can see if the number of running containers/pods has dropped, which could signal a fault or crash in a particular
|
|
Kubernetes service or deployment (see `kubectl get services` or `kubectl get deployments` for more details). If the
|
|
number of pods increases, it may be because of something more benign, like another team member scaling up a
|
|
service with `kubectl scale`.
|
|
|
|
You can also view charts for the Kubelet API server, the volume of runtime/Docker operations by type,
|
|
configuration-related errors, and the actual vs. desired numbers of volumes, plus a lot more.
|
|
|
|
### kube-proxy
|
|
|
|
The **k8s kube-proxy** section displays metrics about the network proxy that runs on each node in your Kubernetes
|
|
cluster. kube-proxy lets pods communicate with each other and accept sessions from outside your cluster. Its metrics are
|
|
collected by the [kube-proxy
|
|
collector](/src/go/plugin/go.d/collector/k8s_kubeproxy/README.md).
|
|
|
|
With Netdata, you can monitor how often your k8s proxies are syncing proxy rules between nodes. Dramatic changes in
|
|
these figures could indicate an anomaly in your cluster that's worthy of further investigation.
|
|
|
|
## What's next?
|
|
|
|
After reading this guide, you should now be able to monitor any Kubernetes cluster with Netdata, including nodes, pods,
|
|
containers, services, and more.
|
|
|
|
With the health map, time-series charts, and the ability to drill down into individual nodes, you can see hundreds of
|
|
per-second metrics with zero configuration and less time remembering all the `kubectl` options. Netdata moves with your
|
|
cluster, automatically picking up new nodes or services as your infrastructure scales. And it's entirely free for
|
|
clusters of all sizes.
|
|
|
|
### Related reference documentation
|
|
|
|
- [Netdata Helm chart](https://github.com/netdata/helmchart)
|
|
- [Netdata service discovery](https://github.com/netdata/agent-service-discovery)
|
|
- [Netdata Agent · `kubelet`
|
|
collector](/src/go/plugin/go.d/collector/k8s_kubelet/README.md)
|
|
- [Netdata Agent · `kube-proxy`
|
|
collector](/src/go/plugin/go.d/collector/k8s_kubeproxy/README.md)
|
|
- [Netdata Agent · `cgroups.plugin`](/src/collectors/cgroups.plugin/README.md)
|