13 KiB
Monitor, troubleshoot, and debug applications with eBPF metrics
When trying to troubleshoot or debug a finicky application, there's no such thing as too much information. At Netdata, we developed programs that connect to the extended Berkeley Packet Filter (eBPF) virtual machine to help you see exactly how specific applications are interacting with the Linux kernel. With these charts, you can root out bugs, discover optimizations, diagnose memory leaks, and much more.
This means you can see exactly how often, and in what volume, the application creates processes, opens files, writes to filesystem using virtual filesystem (VFS) functions, and much more. Even better, the eBPF collector gathers metrics at an event frequency, which is even faster than Netdata's beloved 1-second granularity. When you troubleshoot and debug applications with eBPF, rest assured you miss not even the smallest meaningful event.
Using this guide, you'll learn the fundamentals of setting up Netdata to give you kernel-level metrics from your application so that you can monitor, troubleshoot, and debug to your heart's content.
Configure apps.plugin to recognize your custom application
To start troubleshooting an application with eBPF metrics, you need to ensure your Netdata dashboard collects and displays those metrics independent from any other process.
You can use the apps_groups.conf file to configure which applications appear in charts generated by
apps.plugin. Once you edit this file and create a new group for the application
you want to monitor, you can see how it's interacting with the Linux kernel via real-time eBPF metrics.
Let's assume you have an application that runs on the process custom-app. To monitor eBPF metrics for that application
separate from any others, you need to create a new group in apps_groups.conf and associate that process name with it.
Open the apps_groups.conf file in your Netdata configuration directory.
cd /etc/netdata # Replace this path with your Netdata config directory
sudo ./edit-config apps_groups.conf
Scroll down past the explanatory comments and stop when you see # NETDATA processes accounting. Above that, paste in
the following text, which creates a new dev group with the custom-app process. Replace custom-app with the name of
your application's process name.
Your file should now look like this:
...
# -----------------------------------------------------------------------------
# Custom applications to monitor with apps.plugin and ebpf.plugin
dev: custom-app
# -----------------------------------------------------------------------------
# NETDATA processes accounting
...
Restart Netdata with sudo systemctl restart netdata, or the appropriate method for your system, to begin seeing metrics for this particular
group+process. You can also add additional processes to the same group.
You can set up apps_groups.conf to more show more precise eBPF metrics for any application or service running on your
system, even if it's a standard package like Redis, Apache, or any other application/service Netdata collects
from.
# -----------------------------------------------------------------------------
# Custom applications to monitor with apps.plugin and ebpf.plugin
dev: custom-app
database: *redis*
apache: *apache*
# -----------------------------------------------------------------------------
# NETDATA processes accounting
...
Now that you have apps_groups.conf set up to monitor your application/service, you can also set up the eBPF collector
to show other charts that will help you debug and troubleshoot how it interacts with the Linux kernel.
Configure the eBPF collector to monitor errors
The eBPF collector has two possible modes: entry and return. The default
is entry, and only monitors calls to kernel functions, but the return also monitors and charts whether these calls
return in error.
Let's turn on the return mode for more granularity when debugging Firefox's behavior.
cd /etc/netdata # Replace this path with your Netdata config directory
sudo ./edit-config ebpf.d.conf
Replace entry with return:
[global]
ebpf load mode = return
disable apps = no
[ebpf programs]
process = yes
network viewer = yes
Restart Netdata with sudo systemctl restart netdata, or the appropriate method for your system.
Get familiar with per-application eBPF metrics and charts
Visit the Netdata dashboard at http://NODE:19999, replacing NODE with the hostname or IP of the system you're using
to monitor this application. Scroll down to the Applications section. These charts now feature a firefox dimension
with metrics specific to that process.
Pay particular attention to the charts in the ebpf file, ebpf syscall, ebpf process, and ebpf net
sub-sections. These charts are populated by low-level Linux kernel metrics thanks to eBPF, and showcase the volume of
calls to open/close files, call functions like do_fork, IO activity on the VFS, and much more.
See the eBPF collector documentation for the full list of per-application charts.
Let's show some examples of how you can first identify normal eBPF patterns, then use that knowledge to identify anomalies in a few simulated scenarios.
For example, the following screenshot shows the number of open files, failures to open files, and closed files on a
Debian 10 system. The first spike is from configuring/compiling a small C program, then from running Apache's ab tool
to benchmark an Apache web server.
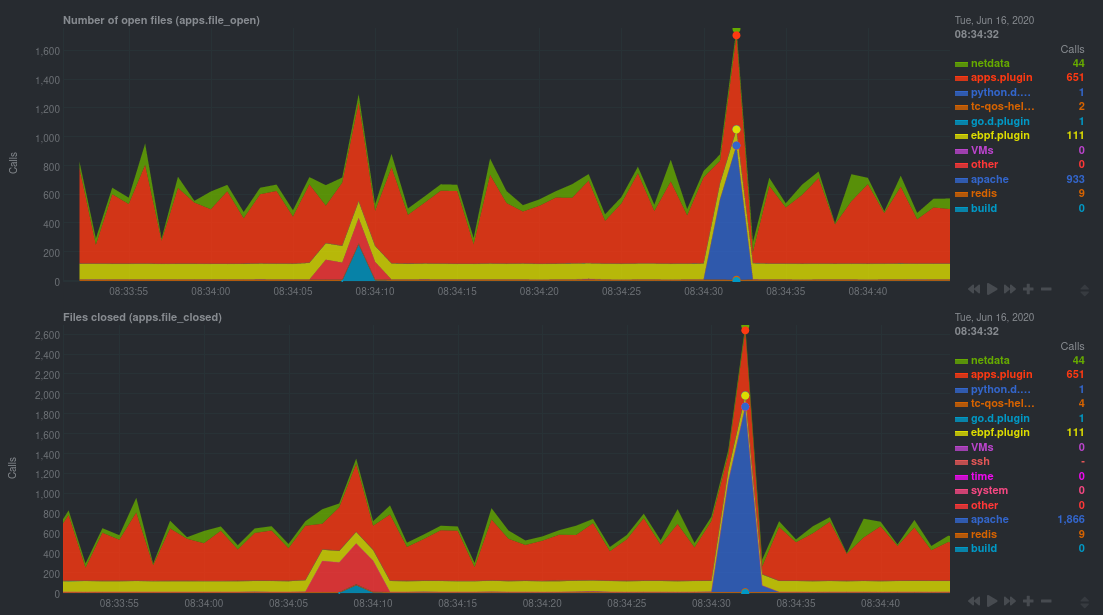
In these charts, you can see first a spike in syscalls to open and close files from the configure/build process, followed by a similar spike from the Apache benchmark.
👋 Don't forget that you can view chart data directly via Netdata's API!
For example, open your browser and navigate to
http://NODE:19999/api/v1/data?chart=apps.file_open, replacingNODEwith the IP address or hostname of your Agent. The API returns JSON of that chart's dimensions and metrics, which you can use in other operations.To see other charts, replace
apps.file_openwith the context of the chart you want to see data for.To see all the API options, visit our Swagger documentation and look under the /data section.
Troubleshoot and debug applications with eBPF
The actual method of troubleshooting and debugging any application with Netdata's eBPF metrics depends on the application, its place within your stack, and the type of issue you're trying to root cause. This guide won't be able to explain how to troubleshoot any application with eBPF metrics, but it should give you some ideas on how to start with your own systems.
The value of using Netdata to collect and visualize eBPF metrics is that you don't have to rely on existing (complex) command line eBPF programs or, even worse, write your own eBPF program to get the information you need.
Let's walk through some scenarios where you might find value in eBPF metrics.
Benchmark application performance
You can use eBPF metrics to profile the performance of your applications, whether they're custom or a standard Linux service, like a web server or database.
For example, look at the charts below. The first spike represents running a Redis benchmark without pipelining
(redis-benchmark -n 1000000 -t set,get -q). The second spike represents the same benchmark with pipelining
(redis-benchmark -n 1000000 -t set,get -q -P 16).
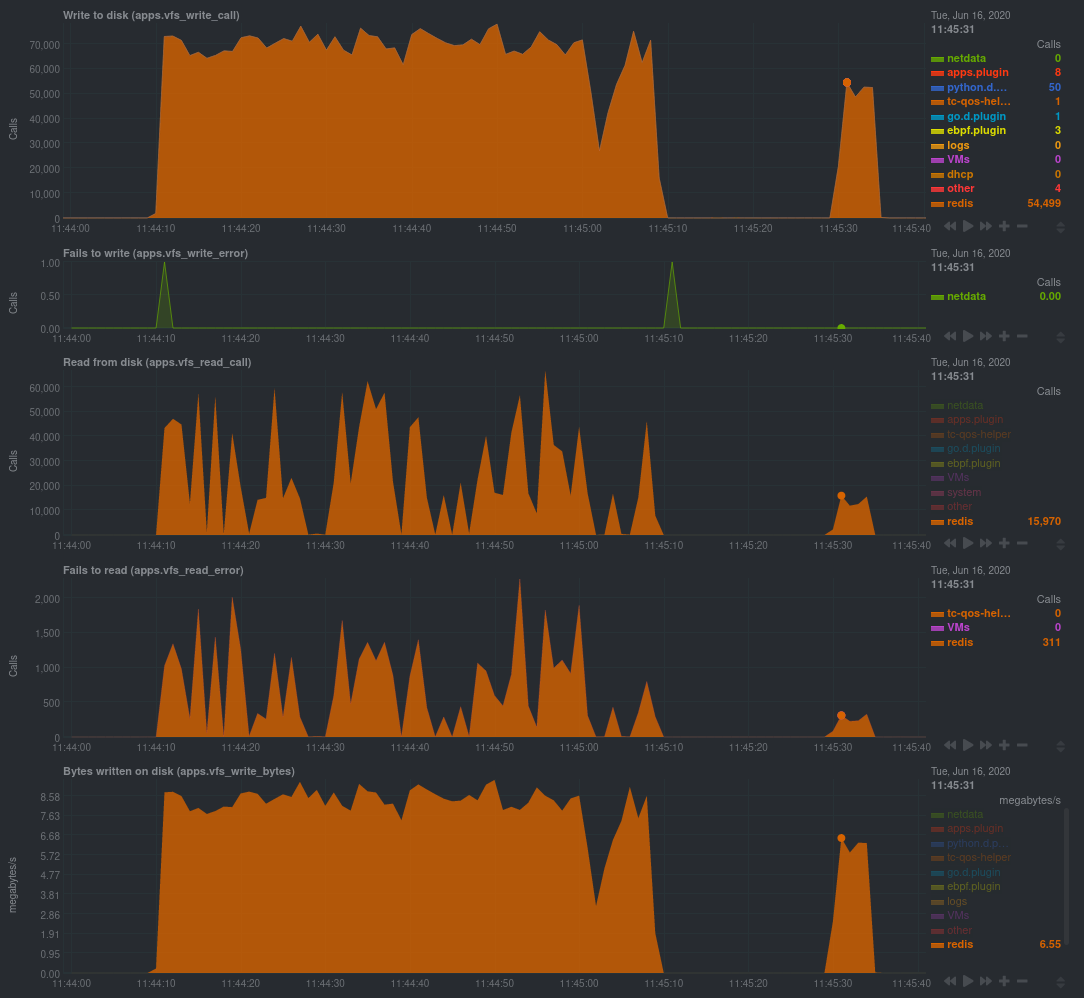
The performance optimization is clear from the speed at which the benchmark finished (the horizontal length of the spike) and the reduced write/read syscalls and bytes written to disk.
You can run similar performance benchmarks against any application, view the results on a Linux kernel level, and continuously improve the performance of your infrastructure.
Inspect for leaking file descriptors
If your application runs fine and then only crashes after a few hours, leaking file descriptors may be to blame.
Check the Number of open files (apps.file_open) and Files closed (apps.file_closed) for discrepancies. These metrics should be more or less equal. If they diverge, with more open files than closed, your application may not be closing file descriptors properly.
See, for example, the volume of files opened and closed by apps.plugin itself. Because the eBPF collector is
monitoring these syscalls at an event level, you can see at any given second that the open and closed numbers as equal.
This isn't to say Netdata is perfect, but at least apps.plugin doesn't have a file descriptor problem.
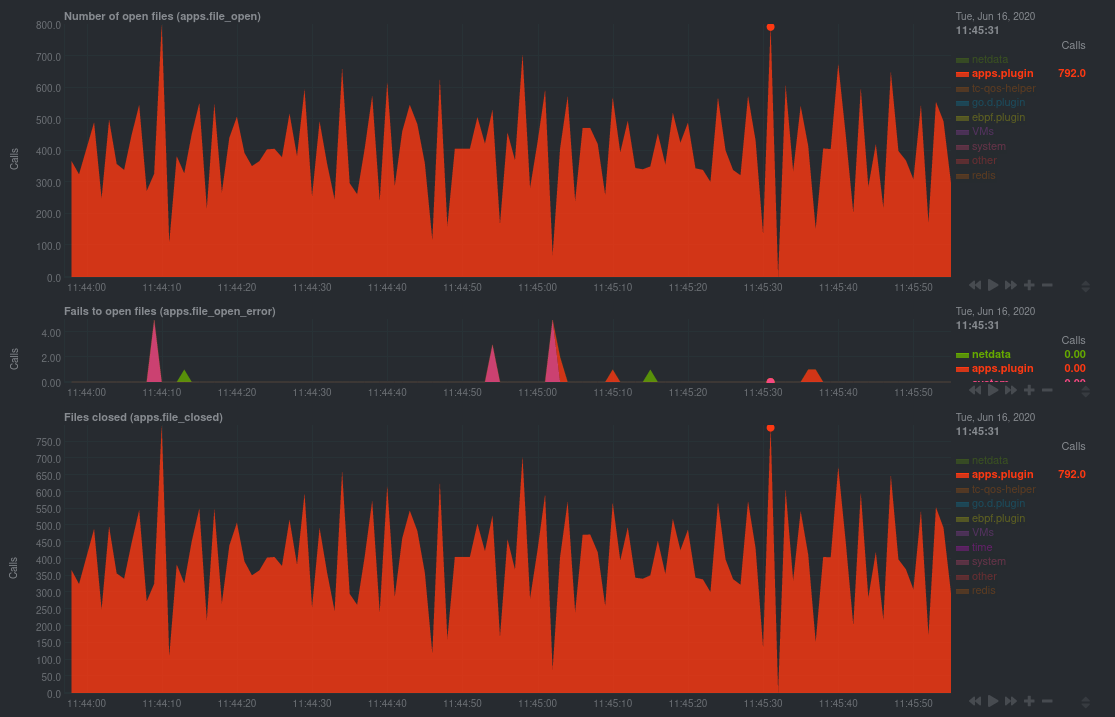
Pin down syscall failures
If you enabled the eBPF collector's return mode as mentioned in a previous
step, you can view charts related to how often a given application's
syscalls return in failure.
By understanding when these failures happen, and when, you might be able to diagnose a bug in your application.
To diagnose potential issues with an application, look at the Fails to open files (apps.file_open_error), Fails to close files (apps.file_close_error), Fails to write (apps.vfs_write_error), and Fails to read (apps.vfs_read_error) charts for failed syscalls coming from your application. If you see any, look to the surrounding charts for anomalies at the same time frame, or correlate with other activity in the application or on the system to get closer to the root cause.
Investigate zombie processes
Look for the trio of Process started (apps.process_create), Threads started (apps.thread_create), and Tasks closed (apps.task_close) charts to investigate situations where an application inadvertently leaves zombie processes.
These processes, which are terminated and don't use up system resources, can still cause issues if your system runs out of available PIDs to allocate.
For example, the chart below demonstrates a zombie factory program in action.
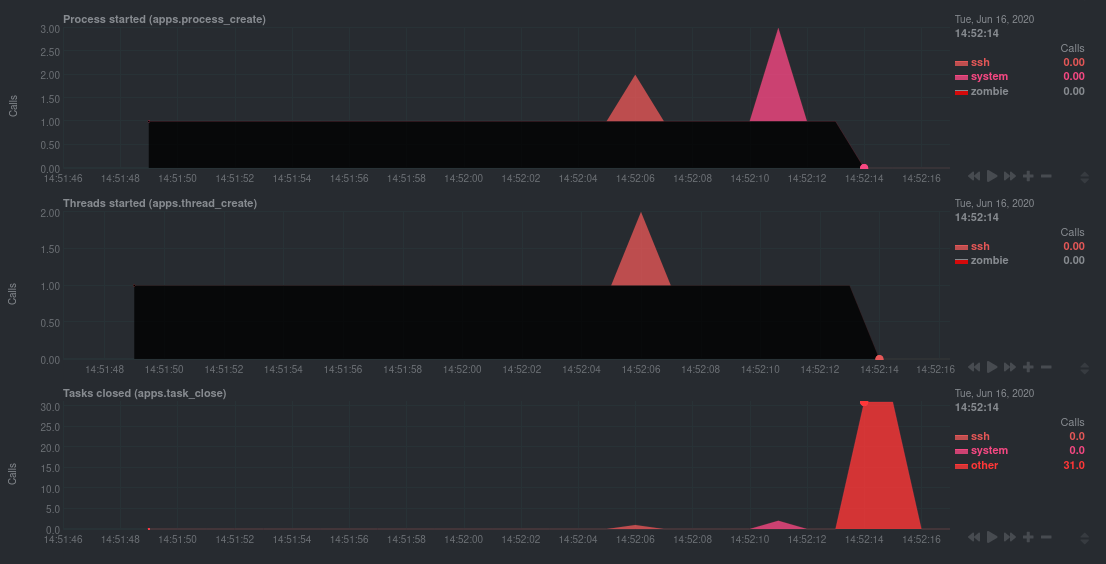
Starting at 14:51:49, Netdata sees the zombie group creating one new process every second, but no closed tasks. This
continues for roughly 30 seconds, at which point the factory program was killed with SIGINT, which results in the 31
closed tasks in the subsequent second.
Zombie processes may not be catastrophic, but if you're developing an application on Linux, you should eliminate them. If a service in your stack creates them, you should consider filing a bug report.
View eBPF metrics in Netdata Cloud
You can also show per-application eBPF metrics in Netdata Cloud. This could be particularly useful if you're running the same application on multiple systems and want to correlate how it performs on each target, or if you want to share your findings with someone else on your team.
If you don't already have a Netdata Cloud account, go sign in and get started for free. You can also read how to monitor your infrastructure with Netdata Cloud to understand the key features that it has to offer.
Once you've added one or more nodes to a Space in Netdata Cloud, you can see aggregated eBPF metrics in the Overview dashboard under the same Applications or eBPF sections that you find on the local Agent dashboard. Or, create new dashboards using eBPF metrics from any number of distributed nodes to see how your application interacts with multiple Linux kernels on multiple Linux systems.
Now that you can see eBPF metrics in Netdata Cloud, you can invite your team and share your findings with others.